人体手势检测识别是指通过计算机视觉和深度学习技术,自动地识别和理解人体的手势动作。这项技术可以应用于各种领域,如人机交互、虚拟现实、智能监控等。
下面是一般的人体手势检测识别流程:
-
数据采集:首先需要收集包含手势动作的训练数据。这些数据可以通过摄像头或者深度传感器捕捉到人体的图像或视频序列。
-
预处理:对采集到的图像或视频进行预处理,包括图像降噪、尺寸调整、人体姿态估计等。目的是提取出清晰且准确的人体图像。
-
手关键点检测:利用关键点检测算法,如人体姿态估计模型(如OpenPose、HRNet等),在图像中��测和定位人体的手部区域,并获得手指关节的位置信息。
-
特征提取:基于手关键点的位置信息,可以计算手势的特征表示。常见的方法包括使用手指之间的距离、角度、方向等来表示手势的形状和动作。
-
建立分类模型:使用机器学习或深度学习算法,建立一个手势分类模型。可以采用传统的机器学习算法如支持向量机(SVM),也可以使用深度学习模型如卷积神经网络(CNN)或循环神经网络(RNN)。
-
训练和优化:使用标记好的手势数据集进行训练,并通过反向传播算法等优化模型参数,以提高模型的准确性和泛化能力。
-
手势识别:使用训练好的模型对新的手势图像或视频序列进行识别。将图像输入模型,获得对应的手势类别或标签。
-
应用领域:根据应用需求,可以将手势动作应用于各种场景中,如游戏控制、手势交互界面、手势语音识别等。
人体手势检测识别是一个复杂的任务,需要结合图像处理、计算机视觉和机器学习等技术。随着深度学习的发展,现代的手势识别系统在准确性和实时性方面取得了显著的进步。
本文的核心目的就是为例尝试基于YOLOv5目标检测模型开发构建实现人体手势检测识别模型,首先看下效果实例:

数据集来源于人工数据标注,如下所示:

训练数据配置文件如下所示:
# Dataset
path: ./dataset
train:
- images/train
val:
- images/test
test:
- images/test
# Classes
names:
0: 0
1: 1
2: 2
3: 3
4: 4
5: 5
6: 6
7: 7
8: 8
9: 9YOLOv5是一种基于深度学习的目标检测算法,它在YOLOv3的基础上进行了改进和优化。YOLOv5提供了不同参数量级的模型,分别称为YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,其中s、m、l和x表示小、中、大和额外大。
这些不同参数量级的模型主要区别在于网络的深度和宽度,以及在训练过程中使用的图像尺寸。具体来说,以下是对每个模型的简要描述:
-
YOLOv5s:这是最小的模型,具有较少的参数量。它适用于资源受限的设备或需要快速推理的场景。YOLOv5s在检测速度和准确性之间取得了良好的平衡。
-
YOLOv5m:这是介于小型和大型模型之间的中等规模模型。它在YOLOv5系列中是默认模型,提供了更高的检测精度,适用于多种应用场景。
-
YOLOv5l:这是一个较大的模型,比YOLOv5m具有更多的参数。相对于YOLOv5m,YOLOv5l在精度方面略微提升,但需要更多的计算资源。
-
YOLOv5x:这是YOLOv5系列中参数最多的模型,也是最大的模型。它提供了最高的检测精度,但需要更多的计算资源。YOLOv5x适用于对精度要求较高的场景,如精细粒度目标检测。
总体而言,YOLOv5s适用于资源受限的情况下,YOLOv5m是一个平衡的选择,YOLOv5l和YOLOv5x适合需要更高精度的任务。选择适合的模型版本取决于具体应用场景、硬件资源和性能需求等因素。
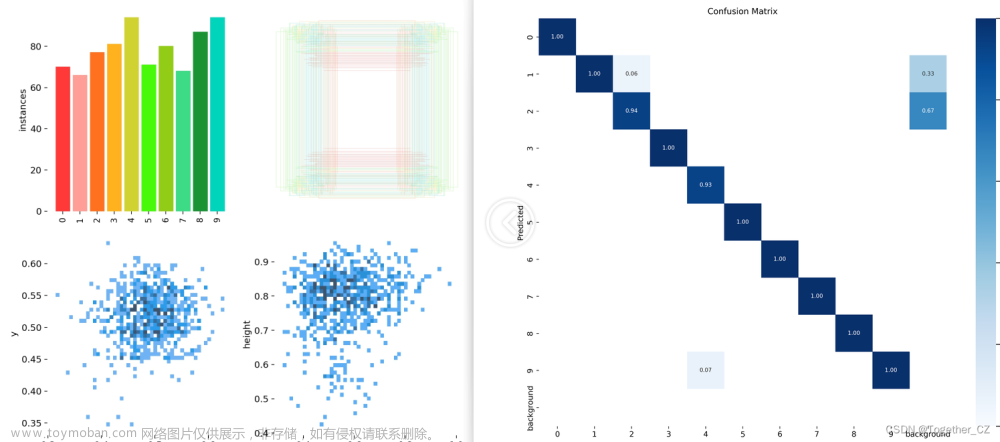
这里同样是开发了n、s、m、l不同参数量级的模型来对比性能差异。默认都是100次epoch迭代计算,模型训练日志输出如下所示:

接下来看下具体的结果详情。
【yolov5n】

【yolov5s】



【yolov5m】



【yolov5l】




接下来我们整体对比了这四款不同量级的模型,如下所示:
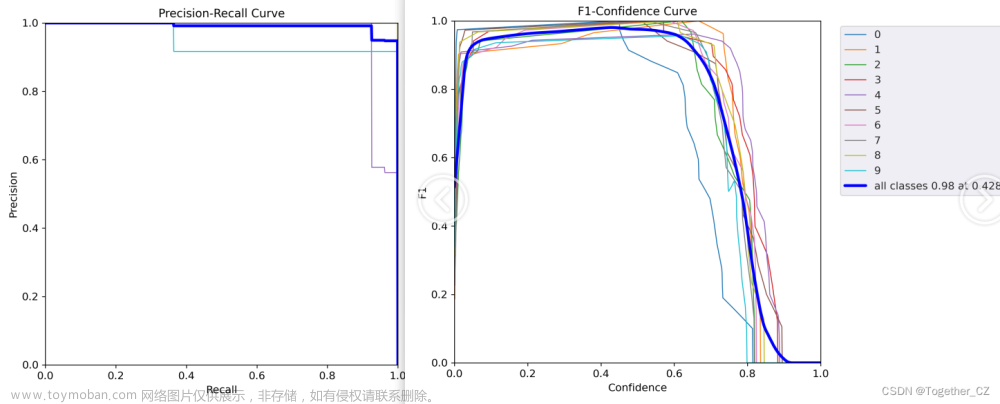
首先是F1值曲线,F1值是一个常用的评估指标,用于衡量分类模型的综合性能。它结合了准确率(Precision)和召回率(Recall),提供了对模型在正负样本上的平衡性评价。
F1值的计算公式如下: F1 = 2 * (Precision * Recall) / (Precision + Recall)
其中,Precision表示预测为正例中实际为正例的比例,可以理解为模型的准确率。Recall表示实际为正例中被正确预测为正例的比例,也称为查全率。
F1值的取值范围在0到1之间,值越接近1表示模型的分类性能越好。当Precision和Recall同时较高时,F1值会更接近1;当Precision和Recall出现较大差异时,F1值会较低。
F1值适用于两个类别均衡或不均衡的二分类问题。对于不同类别的重要程度不一致的情况,可以使用加权F1值,通过为每个类别分配不同的权重来调整F1值的计算。
总而言之,F1值是一个综合考虑准确率和召回率的指标,用于评估分类模型的整体性能。它是在不同场景下判断分类器优劣的重要指标之一。
核心代码实现如下所示:
def F1(P,R):
"""
F1值
"""
return 2*P*R/(P+R)结果如下所示:

接下来是loss曲线,如下所示:

之后是Precision精确率和Recall召回率曲线。
精确率(Precision)是用于评估分类模型在预测为正例的样本中真实为正例的能力,也称为阳性预测值。它是分类模型的性能指标之一。
精确率的计算公式如下: Precision = TP / (TP + FP)
其中,TP表示真阳性(True Positive),即被正确地预测为正例的样本数量;FP表示假阳性(False Positive),即被错误地预测为正例的样本数量。
精确率的取值范围在0到1之间,值越高表示模型在预测正例时的准确性越高。一个高精确率意味着模型能够尽可能减少将负例误判为正例的情况。
精确率是解决特定问题时的重要指标。例如,在垃圾邮件过滤中,我们更关注将正常邮件误判为垃圾邮件的情况,因此希望获得较高的精确率。但是需要注意的是,精确率只能提供了解模型在预测为正例的样本中的准确性,并无法反映模型对负例的预测能力。
在评估分类模型性能时,通常需要综合考虑其他指标如召回率、F1值等。这些指标能够提供更全面的性能评估,帮助我们了解模型在不同方面的表现。
召回率(Recall),也称为查全率,是用于评估分类模型在所有实际正例中正确预测为正例的能力。它是分类模型的性能指标之一。
召回率的计算公式如下: Recall = TP / (TP + FN)
其中,TP表示真阳性(True Positive),即被正确地预测为正例的样本数量;FN表示假阴性(False Negative),即被错误地预测为负例的样本数量。
召回率的取值范围在0到1之间,值越高表示模型在找出实际正例方面的能力越强。一个高召回率意味着模型能够尽可能减少将正例漏判为负例的情况。
召回率通常应用于那些对于找出所有正例非常关键的任务中,例如在医学诊断中寻找患有某种疾病的患者。在这种情况下,我们更关注将实际正例正确预测出来,而可以容忍一些误判为正例的情况。
然而,需要注意的是,召回率无法单独评估一个分类模型的性能。在不平衡数据集中,召回率较高可能会导致精确率较低。因此,在评估分类模型性能时,需要综合考虑其他指标如精确率、F1值等,以获得更全面的性能评估。
精确率曲线如下所示:

召回率曲线如下所示:
 文章来源:https://www.toymoban.com/news/detail-516763.html
文章来源:https://www.toymoban.com/news/detail-516763.html
后面有时间会继续把yolox系列的模型也开发出来整体对比一下。文章来源地址https://www.toymoban.com/news/detail-516763.html
到了这里,关于基于YOLOv5系列【n/s/m/l】模型开发构建人体手势目标检测识别分析系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!













