Flink
1. 概述
分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
有界流:有定义流的开始,也有定义流的结束,可以在摄取所有数据后再进行计算。所有数据可以被排序,所以并不需要有序获取,通常被称为批处理。
无界流:有定义流的开始,但没有定义流的结束,无休止地产生数据。无界流的数据必须持续处理,即数据被获取后需要立刻处理,流处理。
-
1.1 Flink批处理和流处理
Flink分别提供了面向流处理的接口(DataStreamAPI)和面向批处理的接口(DataSetAPI)。因此,Flink既可以完成流处理,也可以完成批处理。tableAPI是针对流处理和批处理的API。
Spark中,对于批处理和流处理采用了不同的技术框架,批处理由 SparkSQL 实现,流处理由 Spark Streaming 实现。
-
1.2 Flink 四大基石
-
窗口Window
流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算
Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口
类似离线批处理分析中开窗函数中窗口大小设置 -
时间Time
Flink中窗口计算,基本上都是基于时间设置窗口
Flink还实现了Watermark的机制,能够支持基于事件时间的处理,能够容忍迟到/乱序的数据
基于事件时间窗口计算:EventTime事件时间、窗口计算Window、窗口类型 -
状态State
Flink计算引擎,自身就是基于状态计算框架,默认情况下程序自己管理状态
提供一致性的语义,使得用户在编程时能够更轻松、更容易地去管理状态
提供一套非常简单明了的State API,包括ValueState、ListState、MapState,BroadcastState -
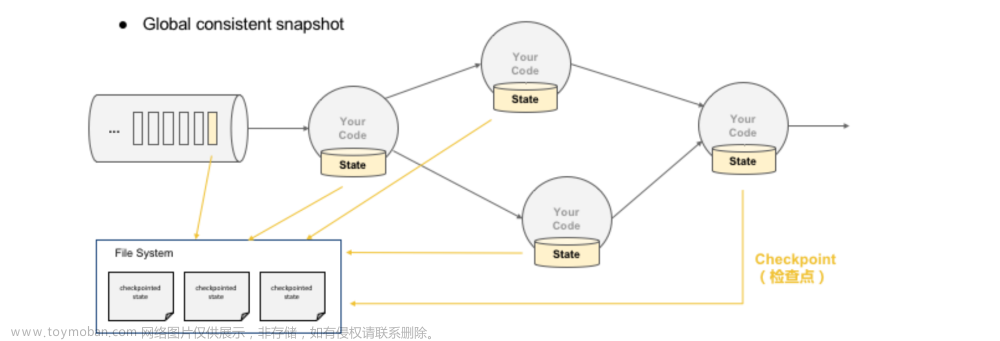
检查点Checkpoint
Flink Checkpoint检查点:保存状态数据
基于Chandy-Lamport算法实现了一个分布式的一致性的快照,从而提供了一致性的语义
进行Checkpoint后,可以设置自动进行故障恢复
保存点Savepoint,人工进行Checkpoint操作,进行程序恢复执行
参考:
https://blog.csdn.net/weixin_44133605/article/details/125117615 -
-
1.3 Flink特性
-
同时支持高吞吐、低延迟、高性能的流处理
Flink 的流处理引擎只需要很少配置就能实现高吞吐率和低延迟。 -
支持带有事件时间的窗口操作
Event time使得计算乱序到达的事件或可能延迟到达的事件更加简单。
大多数窗口计算采用的都是系统时间(Process Time),也是事件传输到计算框架时,系统主机的当前时间。Flink能够支持基于时间事件时间(Event Time)语义进行窗口计算,也就是时间产生的时间。这种基于时间驱动的机制使得事件即使是乱序到达,流系统也能够计算出精确的结果,保持了时间原本产生的时序性。尽量避免网络传输或硬件系统影响。 -
支持有状态计算的 Exactly-once 语义
流程序可以在计算过程中维护自定义状态。
Flink 的 checkpointing 机制保证了即时在故障发生下也能保障状态的 exactly once 语义。
:::info
Flink的Exactly-once 指的是:状态只持久化一次到最终的存储介质中(本地数据库/HDFS…)
无状态简单理解为:每次的执行都不依赖上一次或上N次的执行结果,每次的执行都是独立的。
有状态简单理解为:执行需要依赖上一次或上N次的执行结果,某次的执行需要依赖前面事件的处理结果。
::: -
支持高度灵活的窗口操作,支持基于 time、count、session,以及 data-driven 的窗口操作
在流处理应用中,数据是连续不断的,需要通过窗口的方式对数据进行一定范围的聚合计算,窗口可以用灵活的触发条件定制化达到对复杂的流传输模式的支持,用户可以定义不同窗口触发机制来满足不同的需求。 -
支持具有反压功能的持续流模型
慢的数据sink节点会反压(backpressure)快的数据源(sources)。 -
支持基于轻量级分布式快照(Snapshot)实现的容错
这种机制是非常轻量级的,允许系统拥有高吞吐率的同时还能提供强一致性的保障。 -
Batch和Streaming 一个系统流处理和批处理共用一个引擎
Flink 为流处理和批处理应用公用一个通用的引擎。批处理应用可以以一种特殊的流处理应用高效地运行。 -
Flink 在 JVM 内部实现了自己的内存管理
应用可以超出主内存的大小限制,并且承受更少的垃圾收集的开销。 -
支持迭代计算
Flink 具有迭代计算的专门支持,增量迭代可以利用依赖计算来更快地收敛。 -
支持程序自动优化
避免特定情况下 Shuffle、排序等昂贵操作,中间结果有必要进行缓存
参考:
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/learn-flink/
https://blog.csdn.net/kwame211/article/details/110422947/ -
-
1.4 Flink部署及启动
Flink 支持多种安装模式:-
local(本地)——单机模式,一般不使用;
-
standalone——独立模式,Flink 自带集群,开发测试环境使用;
-
yarn——计算资源统一由 Hadoop YARN 管理,生产环境使用。
详情参考官方文档
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/ -
2. 架构
-
2.1 Flink 程序结构
Flink 程序的基本构建块是流和转换。
-
Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、RabbitMQ 等
-
Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select等,操作很多,可以将数据转换计算成你想要的数据。
-
Sink:接收器,Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等。

-
2.2 Flink 并行数据流
Flink 程序在执行的时候,会被映射成一个 Streaming Dataflow,一个 Streaming Dataflow 是由一组 Stream 和 Transformation Operator 组成的。在启动时从一个或多个 Source Operator 开始,结束于一个或多个 Sink Operator。
Flink 程序本质上是并行的和分布式的,在执行过程中,一个流(stream)包含一个或多个流分区,而每一个 operator 包含一个或多个 operator 子任务。操作子任务间彼此独立,在不同的线程中执行,甚至是在不同的机器或不同的容器上。operator 子任务的数量是这一特定 operator 的并行度。相同程序中的不同 operator 有不同级别的并行度。
一个 Stream 可以被分成多个 Stream 的分区,也就是 Stream Partition。一个 Operator 也可以被分为多个 Operator Subtask。如上图中,Source 被分成 Source1 和 Source2,它们分别为 Source 的 Operator Subtask。每一个 Operator Subtask 都是在不同的线程当中独立执行的。一个 Operator 的并行度,就等于 Operator Subtask 的个数。上图 Source 的并行度为 2。而一个 Stream 的并行度就等于它生成的 Operator 的并行度。
数据在两个 operator 之间传递的时候有两种模式:
One to One 模式:两个 operator 用此模式传递的时候,会保持数据的分区数和数据的排序;如上图中的 Source1 到 Map1,它就保留的 Source 的分区特性,以及分区元素处理的有序性。Redistributing (重新分配)模式:这种模式会改变数据的分区数;每个一个 operator subtask 会根据选择 transformation 把数据发送到不同的目标 subtasks,比如 keyBy()会通过 hashcode 重新分区,broadcast()和 rebalance()方法会随机重新分区;
-
2.3 Task 和 Operator chain流
Flink的所有操作都称之为Operator,客户端在提交任务的时候会对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行。
-
2.4 任务调度与执行

(1) 当Flink执行executor会自动根据程序代码生成DAG数据流图;(2) ActorSystem创建Actor将数据流图发送给JobManager中的Actor;
(3) JobManager会不断接收TaskManager的心跳消息,从而可以获取到有效的TaskManager;(4) JobManager通过调度器在TaskManager中调度执行Task(在Flink中,最小的调度单元就是task,对应就是一个线程);
(5) 在程序运行过程中,task与task之间是可以进行数据传输的。
Flink 四大组件-
作业管理器(JobManager)
- 控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager 所控制执行。
- JobManager 会先接收到要执行的应用程序,这个应用程序会包括:作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它资源的JAR包。
- JobManager 会把JobGraph转换成一个物理层面的数据流图,这个图被叫做“执行图”(ExecutionGraph),包含了所有可以并发执行的任务。
- JobManager 会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的 TaskManager上。而在运行过程中,JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
-
任务管理器(TaskManager)
- Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。
- 启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。
- 在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据。
-
资源管理器(ResourceManager)
- 主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger 插槽是Flink中定义的处理资源单元。
- Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、Mesos、K8s,以及standalone部署。
- 当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。
-
分发器(Dispatcher)
- 可以跨作业运行,它为应用提交提供了REST接口。
- 当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。
- Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。
- Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
参考:
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/learn-flink/overview/ -
作业管理器(JobManager)
2. 算子
Flink和Spark类似,也是一种一站式处理的框架;既可以进行批处理(DataSet),也可以进行实时处理(DataStream)。
将Flink的算子分为两大类:一类是DataSet,一类是DataStream。
-
3.1 DataSet 批处理算子
-
Source算子
- fromCollection
从本地集合读取数据
eg:
val env = ExecutionEnvironment.getExecutionEnvironment val textDataSet: DataSet[String] = env.fromCollection( List("1,张三", "2,李四", "3,王五", "4,赵六")- readTextFile
从文件中读取
eg:
val textDataSet: DataSet[String] = env.readTextFile("/data/a.txt") - fromCollection
-
Transform转换算子
基于Source算子操作- map
将DataSet中的每一个元素转换为另外一个元素
eg:
// 使用map将List转换为一个Scala的样例类 case class User(name: String, id: String) val userDataSet: DataSet[User] = textDataSet.map { text => val fieldArr = text.split(",") User(fieldArr(0), fieldArr(1)) } userDataSet.print()- flatMap
将DataSet中的每一个元素转换为0…n个元素。
eg:
// 使用flatMap操作,将集合中的数据: // 根据第一个元素,进行分组 // 根据第二个元素,进行聚合求值 val result = textDataSet.flatMap(line => line) .groupBy(0) // 根据第一个元素,进行分组 .sum(1) // 根据第二个元素,进行聚合求值 result.print()- mapPartition
将一个分区中的元素转换为另一个元素
eg:
// 使用mapPartition操作,将List转换为一个scala的样例类 case class User(name: String, id: String) val result: DataSet[User] = textDataSet.mapPartition(line => { line.map(index => User(index._1, index._2)) }) result.print()- filter
过滤出来一些符合条件的元素,返回boolean值为true的元素
eg:
val source: DataSet[String] = env.fromElements("java", "scala", "java") val filter:DataSet[String] = source.filter(line => line.contains("java"))//过滤出带java的数据 filter.print()- reduce
可以对一个dataset或者一个group来进行聚合计算,最终聚合成一个元素
eg:
// 使用 fromElements 构建数据源 val source = env.fromElements(("java", 1), ("scala", 1), ("java", 1)) // 使用map转换成DataSet元组 val mapData: DataSet[(String, Int)] = source.map(line => line) // 根据首个元素分组 val groupData = mapData.groupBy(_._1) // 使用reduce聚合 val reduceData = groupData.reduce((x, y) => (x._1, x._2 + y._2)) // 打印测试 reduceData.print()- reduceGroup
将一个dataset或者一个group聚合成一个或多个元素。
reduceGroup是reduce的一种优化方案;
它会先分组reduce,然后在做整体的reduce;这样做的好处就是可以减少网络IO
eg:
// 使用 fromElements 构建数据源 val source: DataSet[(String, Int)] = env.fromElements(("java", 1), ("scala", 1), ("java", 1)) // 根据首个元素分组 val groupData = source.groupBy(_._1) // 使用reduceGroup聚合 val result: DataSet[(String, Int)] = groupData.reduceGroup { (in: Iterator[(String, Int)], out: Collector[(String, Int)]) => val tuple = in.reduce((x, y) => (x._1, x._2 + y._2)) out.collect(tuple) } // 打印测试 result.print()- minBy和maxBy
选择具有最小值或最大值的元素
eg:
// 使用minBy操作,求List中每个人的最小值 // List("张三,1", "李四,2", "王五,3", "张三,4") case class User(name: String, id: String) // 将List转换为一个scala的样例类 val text: DataSet[User] = textDataSet.mapPartition(line => { line.map(index => User(index._1, index._2)) }) val result = text .groupBy(0) // 按照姓名分组 .minBy(1) // 每个人的最小值- Aggregate
在数据集上进行聚合求最值(最大值、最小值),只能作用于元组上
eg:
val data = new mutable.MutableList[(Int, String, Double)] data.+=((1, "yuwen", 89.0)) data.+=((2, "shuxue", 92.2)) data.+=((3, "yuwen", 89.99)) // 使用 fromElements 构建数据源 val input: DataSet[(Int, String, Double)] = env.fromCollection(data) // 使用group执行分组操作 val value = input.groupBy(1) // 使用aggregate求最大值元素 .aggregate(Aggregations.MAX, 2) // 打印测试 value.print()- distinct
去重
eg:
// 数据源使用上一题的 // 使用distinct操作,根据科目去除集合中重复的元组数据 val value: DataSet[(Int, String, Double)] = input.distinct(1) value.print()- first
取前N个元素
eg:
input.first(2) // 取前两个数- join
将两个DataSet按照一定条件连接到一起,形成新的DataSet
eg:
// s1 和 s2 数据集格式如下: // DataSet[(Int, String,String, Double)] val joinData = s1.join(s2) // s1数据集 join s2数据集 .where(0).equalTo(0) { // join的条件 (s1, s2) => (s1._1, s1._2, s2._2, s1._3) }- leftOuterJoin
左外连接,左边的Dataset中的每一个元素,去连接右边的元素
此外还有:
rightOuterJoin:右外连接,左边的Dataset中的每一个元素,去连接左边的元素
fullOuterJoin:全外连接,左右两边的元素,全部连接
leftOuterJoin eg:
val data1 = ListBuffer[Tuple2[Int,String]]() data1.append((1,"zhangsan")) data1.append((2,"lisi")) data1.append((3,"wangwu")) data1.append((4,"zhaoliu")) val data2 = ListBuffer[Tuple2[Int,String]]() data2.append((1,"beijing")) data2.append((2,"shanghai")) data2.append((4,"guangzhou")) val text1 = env.fromCollection(data1) val text2 = env.fromCollection(data2) text1.leftOuterJoin(text2).where(0).equalTo(0).apply((first,second)=>{ if(second==null){ (first._1,first._2,"null") }else{ (first._1,first._2,second._2) } }).print()- cross
交叉操作,通过形成这个数据集和其他数据集的笛卡尔积,创建一个新的数据集
和join类似,但是这种交叉操作会产生笛卡尔积,在数据比较大的时候,是非常消耗内存的操作
eg:
val cross = input1.cross(input2){ (input1 , input2) => (input1._1,input1._2,input1._3,input2._2) } cross.print()- union
联合操作,创建包含来自该数据集和其他数据集的元素的新数据集,不会去重
eg:
val unionData: DataSet[String] = elements1.union(elements2).union(elements3) // 去除重复数据 val value = unionData.distinct(line => line)- rebalance
数据均衡,解决数据倾斜问题
eg:
// 使用rebalance操作,避免数据倾斜 val rebalance = filterData.rebalance()- partitionByHash
按照指定的key进行hash分区
eg:
val data = new mutable.MutableList[(Int, Long, String)] data.+=((1, 1L, "Hi")) data.+=((2, 2L, "Hello")) data.+=((3, 2L, "Hello world")) val collection = env.fromCollection(data) val unique = collection.partitionByHash(1).mapPartition{ line => line.map(x => (x._1 , x._2 , x._3)) } unique.writeAsText("hashPartition", WriteMode.NO_OVERWRITE) env.execute()- partitionByRange
根据指定的key对数据集进行范围分区
eg:
val data = new mutable.MutableList[(Int, Long, String)] data.+=((1, 1L, "Hi")) data.+=((2, 2L, "Hello")) data.+=((3, 2L, "Hello world")) data.+=((4, 3L, "Hello world, how are you?")) val collection = env.fromCollection(data) val unique = collection.partitionByRange(x => x._1).mapPartition(line => line.map{ x=> (x._1 , x._2 , x._3) }) unique.writeAsText("rangePartition", WriteMode.OVERWRITE) env.execute()- sortPartition
根据指定的字段值进行分区的排序
eg:
val data = new mutable.MutableList[(Int, Long, String)] data.+=((1, 1L, "Hi")) data.+=((2, 2L, "Hello")) data.+=((3, 2L, "Hello world")) data.+=((4, 3L, "Hello world, how are you?")) val ds = env.fromCollection(data) val result = ds .map { x => x }.setParallelism(2) .sortPartition(1, Order.DESCENDING)//第一个参数代表按照哪个字段进行分区 .mapPartition(line => line) .collect() println(result) - map
-
Sink算子
- collect
将数据输出到本地集合
eg:
result.collect()- writeAsText
将数据输出到文件
Flink支持多种存储设备上的文件,包括本地文件,hdfs文件等
Flink支持多种文件的存储格式,包括text文件,CSV文件等
eg:
// 将数据写入本地文件 result.writeAsText("/data/a", WriteMode.OVERWRITE) // 将数据写入HDFS result.writeAsText("hdfs://node01:9000/data/a", WriteMode.OVERWRITE) - collect
-
-
3.2 DataStream流处理算子
-
Source算子
Flink可以使用 StreamExecutionEnvironment.addSource(source) 来为我们的程序添加数据来源。
Flink在流处理上的source和在批处理上的source基本一致,大约有四大类:基于本地集合的source、基于文件的source、基于socket的source、自定义的source。
Kafka数据写入Flink eg:
val properties = new Properties() properties.setProperty("bootstrap.servers", "localhost:9092") properties.setProperty("group.id", "consumer-group") properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") properties.setProperty("auto.offset.reset", "latest") val source = env.addSource(new FlinkKafkaConsumer011[String]("sensor", new SimpleStringSchema(), properties))-
Transform 转换算子
- Map
将DataStream中的每一个元素转换为另外一个元素
eg:
dataStream.map { x => x * 2 }- FlatMap
采用一个数据元并生成零个,一个或多个数据元。将句子分割为单词的flatmap函数
eg:
dataStream.flatMap { str => str.split(" ") }- Filter
计算每个数据元的布尔函数,并保存函数返回true的数据元。过滤掉零值的过滤器
eg:
dataStream.filter { _ != 0 }- KeyBy
逻辑上将流分区为不相交的分区。具有相同Keys的所有记录都分配给同一分区。在内部,keyBy()是使用散列分区实现的。指定键有不同的方法。
此转换返回KeyedStream,其中包括使用被Keys化状态所需的KeyedStream。
eg:
dataStream.keyBy(0)- Reduce
被Keys化数据流上的“滚动”Reduce。将当前数据元与最后一个Reduce的值组合并发出新值
eg:
keyedStream.reduce { _ + _ }- Fold
具有初始值的被Keys化数据流上的“滚动”折叠。将当前数据元与最后折叠的值组合并发出新值
eg:
val result: DataStream[String] = keyedStream.fold("start")((str, i) => { str + "-" + i })- Aggregations
在被Keys化数据流上滚动聚合。min和minBy之间的差异是min返回最小值,而minBy返回该字段中具有最小值的数据元(max和maxBy相同)。
eg:
keyedStream.sum(0); keyedStream.min(0); keyedStream.max(0); keyedStream.minBy(0); keyedStream.maxBy(0);- Window
可以在已经分区的KeyedStream上定义Windows。Windows根据某些特征(例如,在最后5秒内到达的数据)对每个Keys中的数据进行分组
eg:
dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5)));- WindowAll
Windows可以在常规DataStream上定义。Windows根据某些特征(例如,在最后5秒内到达的数据)对所有流事件进行分组。
注意:在许多情况下,这是非并行转换。所有记录将收集在windowAll 算子的一个任务中。
eg:
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))- Window Apply
将一般函数应用于整个窗口。
注意:如果您正在使用windowAll转换,则需要使用AllWindowFunction。
下面是一个手动求和窗口数据元的函数
eg:
windowedStream.apply { WindowFunction } allWindowedStream.apply { AllWindowFunction }- Window Reduce
将函数缩减函数应用于窗口并返回缩小的值
eg:
windowedStream.reduce { _ + _ }- Window Fold
将函数折叠函数应用于窗口并返回折叠值
eg:
val result: DataStream[String] = windowedStream.fold("start", (str, i) => { str + "-" + i })- Window Join
在给定Keys和公共窗口上连接两个数据流
eg:
dataStream.join(otherStream) .where(<key selector>).equalTo(<key selector>) .window(TumblingEventTimeWindows.of(Time.seconds(3))) .apply (new JoinFunction () {...})- Union
两个或多个数据流的联合,创建包含来自所有流的所有数据元的新流。注意:如果将数据流与自身联合,则会在结果流中获取两次数据元
eg:
dataStream.union(otherStream1, otherStream2, ...)- Interval Join
在给定的时间间隔内使用公共Keys关联两个被Key化的数据流的两个数据元e1和e2,以便e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound
eg:
dataStream.intervalJoin(otherKeyedStream) .between(Time.milliseconds(-2), Time.milliseconds(2)) .upperBoundExclusive(true) .lowerBoundExclusive(true) .process(new IntervalJoinFunction() {...})- Window CoGroup
在给定Keys和公共窗口上对两个数据流进行Cogroup
eg:
dataStream.coGroup(otherStream) .where(0).equalTo(1) .window(TumblingEventTimeWindows.of(Time.seconds(3))) .apply (new CoGroupFunction () {...})- Connect
“连接”两个保存其类型的数据流。连接允许两个流之间的共享状态
eg:
DataStream<Integer> someStream = ... DataStream<String> otherStream = ... ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream) // ... 代表省略中间操作- CoMap,CoFlatMap
类似于连接数据流上的map和flatMap
eg:
connectedStreams.map( (_ : Int) => true, (_ : String) => false)connectedStreams.flatMap( (_ : Int) => true, (_ : String) => false)- Split
根据某些标准将流拆分为两个或更多个流
eg:
val split = someDataStream.split( (num: Int) => (num % 2) match { case 0 => List("even") case 1 => List("odd") })- Select
从拆分流中选择一个或多个流
eg:
SplitStream<Integer> split;DataStream<Integer> even = split.select("even");DataStream<Integer> odd = split.select("odd");DataStream<Integer> all = split.select("even","odd") - Map
-
Sink算子
支持将数据输出到:
本地文件、本地集合、HDFS (参考批处理)
除此之外,还支持:
sink到kafka、sink到mysql、sink到redis文章来源:https://www.toymoban.com/news/detail-516851.html
参考:
dataset api: https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/dataset/overview/
datastream api:
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/datastream/overview/文章来源地址https://www.toymoban.com/news/detail-516851.html -
Source算子
到了这里,关于Flink入门学习(一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!