提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
本文介绍IK Analyzer分词器的安装配置、使用以及ES数据迁移。
一、IK分词器的安装配置
1.克隆elasticsearch-analysis-ik
克隆IK分词器项目,根据README的描述选择对应版本的分支。浏览器访问ES的ip+端口就能看到版本信息,所以我需要切到master分支。

打开pom需要调整一些依赖的版本,与你安装的es版本一致,否则无法使用插件。
<elasticsearch.version>7.9.2</elasticsearch.version>
修改版本后reload project,可能会编译不通过,需要修改代码,比如我遇到的这个问题工具类包路径变了,重新导包就行;另一个是父类的构造方法变了,填入对应的参数等。切换不同版本的elasticsearch包需要修改的部分可能不一样。

2.编译并安装分词器插件
使用maven的package打包项目后会在target生成一个releases目录,里面有一个zip包,elasticsearch-analysis-ik-version.zip
进入es安装目录,创建一个目录,再解压上述文件,其中config目录中包含分词词典,可以自定义词典。
到这一步就可以启动es测试分词效果了。
使用kibana访问
#ik_smart模式分词
GET /_analyze
{
"analyzer": "ik_smart",
"text": "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
#es默认分词
GET /_analyze
{
"analyzer": "standard",
"text": "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
3.自定义分词词典
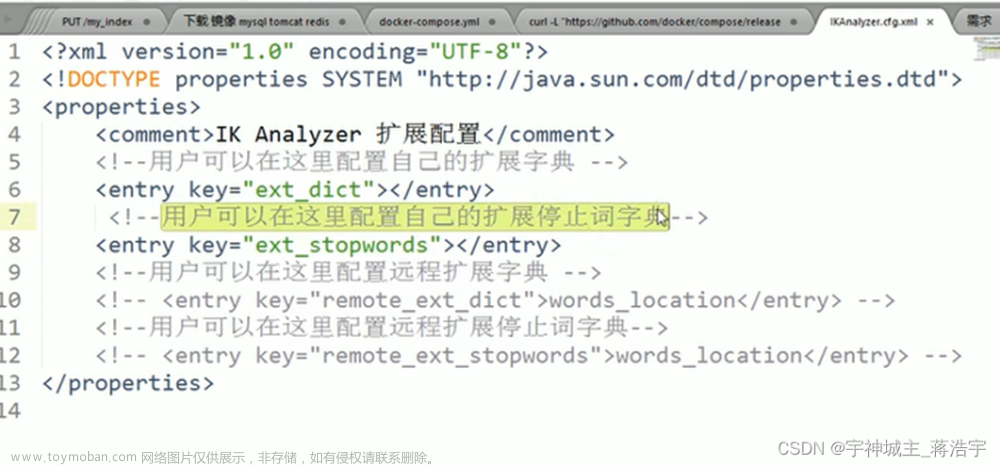
自定义词典需要创建一个文本以dic结尾,每行一个词,且,编辑IKAnalyzer.cfg.xml,使用相对路径,多个词典使用英文分号分隔。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">mydic.dic;mydic2.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
4.注意事项
1.关于ik的两种模式
ik_smart模式,是以最粗粒度进行分词。如果关键字本身就是分词库中的一个词语,那么将不会进一步分词;如果它包含多个分词库中的分词,每次取最先获取到的分词,再对剩余的词语分词。例如有“联想台式”、“台式计算机”、“计算机”三个分词;那么"联想台式计算机"的ik_smart分词结果为“联想台式”、“计算机”,而不会有“台式计算机”。(适合搜索时分词)
ik_max_word则会穷举所有的分词。(适合建立索引时进行分词)
2.词典只支持中文,因此中英混合词语会拆分,但是英文数字可以作为一个词语。
3.该插件虽然支持热更新分词库,但是只是针对搜索时进行的分词,底层的倒排索引并没有改变。
二、ES数据迁移
1.建立新的索引
因为原来没有使用中文分词器,中文会拆分成单独的字,所以倒排索引中全是单个字,这时候使用match搜索,搜索条件按词典分词了,但是词语并不能匹配到文档中的内容。所以需要重建建立索引,让ES按照我们的词典去建立倒排记录表。
2.将旧索引数据导入新索引
使用es的reindex操作,其中slices是分片数,可理解为多线程执行reindex操作,refresh是执行完后刷新。旧索引的名称是my_index_v1,新索引是my_index_v2
#重建索引
POST _reindex?slices=5&refresh
{
"source": {
"index": "my_index_v1"
},
"dest": {
"index": "my_index_v2"
},
"script": {
"source": """
//我将索引中的myName改成了my_name,reindex时旧索引字段会默认copy进新索引,所以我需要删除myName,并将值赋值给my_name。如果没有这类操作,可以删除script。
ctx._source.my_name = ctx._source.remove("myName");
""",
"lang": "painless"
}
}
数据量大的话重建请求会超时,此时可以利用task查看它的任务
#查看reindex的任务列表需要显示任务详情
GET _tasks?detailed=true&actions=*reindex
任务完成后文档数量应与旧索引文档数量一致文章来源:https://www.toymoban.com/news/detail-516948.html
GET /_cat/count/my_index_v2?v
之后将新索引添加别名,系统连接es时使用索引别名。文章来源地址https://www.toymoban.com/news/detail-516948.html
#添加别名
POST /_aliases
{
"actions": [
{
"add": {
"index": "my_index_v2",
"alias": "my_index"
}
}
]
}
到了这里,关于Elasticsearch安装中文分词器IK Analyzer的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!