1 网络管理
1.1Service
1.1.1 网络体系
学习目标
这一节,我们从 应用流程、细节解读、小结 三个方面来学习。
应用流程
资源对象体系
简介
通过对Pod及其管理资源RC和Deployment的实践,我们知道,我们所有的应用服务都是工作在pod资源中,由于每个Pod都有独立的ip地址,而大量的动态创建和销毁操作后,虽然pod资源的数量是控制住了,但是由于pod重新启动,导致他的IP很有可能发生了变化,假设我们这里有前段应用的pod和后端应用的pod,那么再剧烈变动的场景中,两个应用该如何自由通信呢?难道是让我们以类似nginx负载均衡的方式手工定制pod ip然后进行一一管理么?但是这是做不到的。
Kubernetes集群就为我们提供了这样的一个对象--Service,它定义了一组Pod的逻辑集合和一个用于访问它们的策略,它可以基于标签的方式自动找到对应的pod应用,而无需关心pod的ip地址变化与否,从而实现了类似负载均衡的效果.
这个资源在master端的Controller组件中,由Service Controller 来进行统一管理。
service
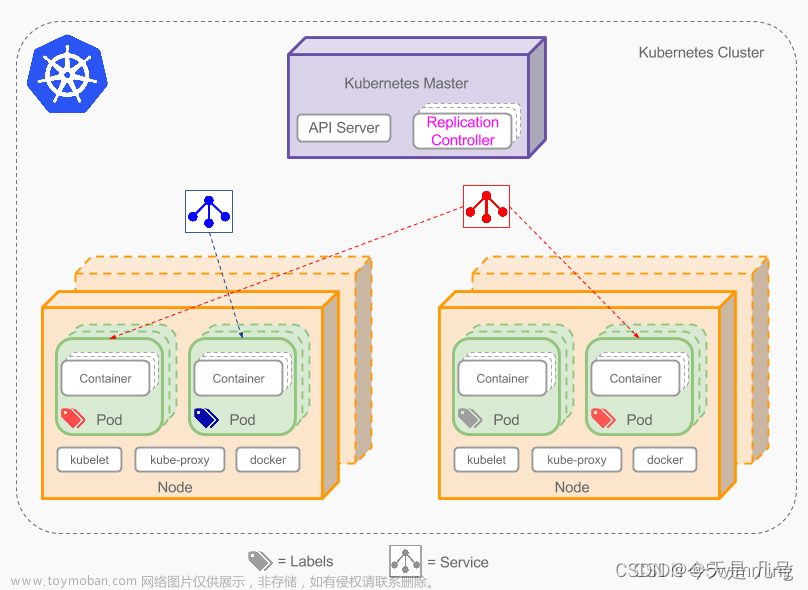
service是Kubernetes里最核心的资源对象之一,每一个Service都是一个完整的业务服务,我们之前学到的Pod、RC、Deployment等资源对象都是为Service服务的。他们之间的关系如下图:

解析
Kubernetes 的 Service定义了一个服务的访问入口地址,前端的应用Pod通过Service访问其背后一组有Pod副本组成的集群示例,Service通过Label Selector访问指定的后端Pod,RC保证Service的服务能力和服务质量处于预期状态。
Service是Kubernetes中最高一级的抽象资源对象,每个Service提供一个独立的服务,集群Service彼此间使用TCP/IP进行通信,将不同的服务组合在一起运行起来,就行了我们所谓的"系统",效果如下图

细节解读
Pod入口
我们知道每个Pod都有一个专用的IP地址,加上Pod内部容器的Port端口,就组成了一个访问Pod专用的EndPoint(Pod IP+Container Port),从而实现了用户外部资源访问Pod内部应用的效果。这个EndPoint资源在master端的Controller组件中,由EndPoint Controller 来进行统一管理。
kube-proxy
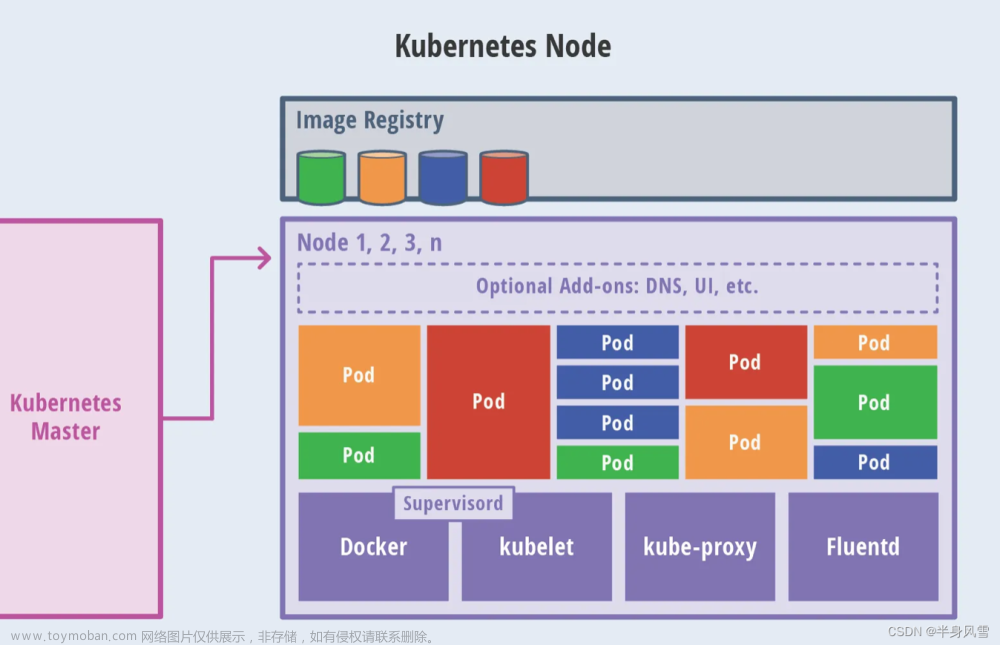
Pod是工作在不同的Node节点上,而Node节点上有一个kube-proxy组件,它本身就是一个软件负载均衡器,在内部有一套专有的负载均衡与会话保持机制,可以达到,接收到所有对Service请求,进而转发到后端的某个具体的Pod实例上,相应该请求。
-- kube-proxy 其实就是 Service Controller位于各节点上的agent。
service表现
Kubernetes给Service分配一个全局唯一的虚拟ip地址--cluster IP,它不存在任何网络设备上,Service通过内容的标签选择器,指定相应该Service的Pod资源,这样以来,请求发给cluster IP,后端的Pod资源收到请求后,就会响应请求。
这种情况下,每个Service都有一个全局唯一通信地址,整个系统的内部服务间调用就变成了最基础的TCP/IP网络通信问题。如果我们的集群内部的服务想要和外部的网络进行通信,方法很多,比如:
NodePort类型,通过在所有结点上增加一个对外的端口,用于接入集群外部请求
ingress类型,通过集群附加服务功能,将外部的域名流量转交到集群内部。
service vs endpoint
1 当创建 Service资源的时候,最重要的就是为Service指定能够提供服务的标签选择器,
2 Service Controller就会根据标签选择器创建一个同名的Endpoint资源对象。
3 Endpoint Controller开始介入,使用Endpoint的标签选择器(继承自Service标签选择器),筛选符合条件的pod资源
4 Endpoint Controller 将符合要求的pod资源绑定到Endpoint上,并告知给Service资源,谁可以正常提供服务。
5 Service 根据自身的cluster IP向外提供由Endpoint提供的服务资源。
-- 所以Service 其实就是 为动态的一组pod资源对象 提供一个固定的访问入口。
小结
1.1.2 工作模型
学习目标
这一节,我们从 模型解读、类型解读、小结 三个方面来学习。
模型解读
简介
Service对象,对于当前集群的节点来说,本质上就是工作节点的一些iptables或ipvs规则,这些规则由kube-proxy进行实时维护,站在kubernetes的发展脉络上来说,kube-proxy将请求代理至相应端点的方式有三种:userspace/iptables/ipvs。目前我们主要用的是 iptables/ipvs 两种。
模式解析

userspace模型是k8s(1.1-1.2)最早的一种工作模型,作用就是将service的策略转换成iptables规则,这些规则仅仅做请求的拦截,而不对请求进行调度处理。
该模型中,请求流量到达内核空间后,由套接字送往用户空间的kube-proxy,再由它送回内核空间,并调度至后端Pod。因为涉及到来回转发,效率不高,另外用户空间的转发,默认开启了会话粘滞,会导致流量转发给无效的pod上。
iptables模式是k8s(1.2-至今)默认的一种模式,作用是将service的策略转换成iptables规则,不仅仅包括拦截,还包括调度,捕获到达ClusterIP和Port的流量,并重定向至当前Service的代理的后端Pod资源。性能比userspace更加高效和可靠
缺点:
不会在后端Pod无响应时自动重定向,而userspace可以
中量级k8s集群(service有几百个)能够承受,但是大量级k8s集群(service有几千个)维护达几万条规则,难度较大
ipvs是自1.8版本引入,1.11版本起为默认设置,通过内核的Netlink接口创建相应的ipvs规则
请求流量的转发和调度功能由ipvs实现,余下的其他功能仍由iptables完成。ipvs流量转发速度快,规则同步性能好,且支持众多调度算法,如rr/lc/dh/sh/sed/nq等。
注意:
对于我们kubeadm方式安装k8s集群来说,他会首先检测当前主机上是否已经包含了ipvs模块,如果加载了,就直接用ipvs模式,如果没有加载ipvs模块的话,会自动使用iptables模式。
类型解读
service类型
对于k8s来说,内部服务的自由通信可以满足我们环境的稳定运行,但是我们作为一个平台,其核心功能还是将平台内部的服务发布到外部环境,那么在k8s环境平台上,Service主要有四种样式来满足我们的需求,种类如下:
ClusterIP
这是service默认的服务暴露模式,主要针对的对象是集群内部。
NodePort
在ClusterIP的基础上,以<NodeIP>:<NodePort>方式对外提供服务,默认端口范围沿用Docker初期的随机端口范围 30000~32767,但是NodePort设定的时候,会在集群所有节点上实现相同的端口。
LoadBalancer
基于NodePort之上,使用运营商负载均衡器方式实现对外提供服务底层是基于IaaS云创建一个k8s云,同时该平台也支持LBaaS产品服务。
ExternalName
当前k8s集群依赖集群外部的服务,那么通过externalName将外部主机引入到k8s集群内部外部主机名以 DNS方式解析为一个 CNAME记录给k8s集群的其他主机来使用这种Service既不会有ClusterIP,也不会有NodePort.而且依赖于内部的CoreDNS功能
小结
1.1.3 SVC实践
学习目标
这一节,我们从 资源实践、NodePort实践、小结 三个方面来学习。
资源实践
资源属性
apiVersion: v1
kind: Service
metadata:
name: …
namespace: …
labels:
key1: value1
key2: value2
spec:
type <string> # Service类型,默认为ClusterIP
selector <map[string]string> # 等值类型的标签选择器,内含“与”逻辑
ports: # Service的端口对象列表
- name <string> # 端口名称
protocol <string> # 协议,目前仅支持TCP、UDP和SCTP,默认为TCP
port <integer> # Service的端口号
targetPort <string> # 后端目标进程的端口号或名称,名称需由Pod规范定义
nodePort <integer> # 节点端口号,仅适用于NodePort和LoadBalancer类型
clusterIP <string> # Service的集群IP,建议由系统自动分配
externalTrafficPolicy <string> # 外部流量策略处理方式,Local表示由当前节点处理,Cluster表示向集群范围调度
loadBalancerIP <string> # 外部负载均衡器使用的IP地址,仅适用于LoadBlancer
externalName <string> # 外部服务名称,该名称将作为Service的DNS CNAME值
手工方法
创建一个应用
[root@kubernetes-master ~]# kubectl create deployment nginx --image=kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1
创建多种类型svc
[root@kubernetes-master ~]# kubectl expose deployment nginx --port=80
[root@kubernetes-master ~]# kubectl expose deployment nginx --name=svc-default --port=80
[root@kubernetes-master ~]# kubectl expose deployment nginx --name=svc-nodeport --port=80 --type=NodePort
[root@kubernetes-master ~]# kubectl expose deployment nginx --name=svc-loadblancer --port=80 --type=LoadBalancer
查看效果
[root@kubernetes-master1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP 10.99.57.240 <none> 80/TCP 4m31s
svc-default ClusterIP 10.103.54.139 <none> 80/TCP 3m2s
svc-loadblancer LoadBalancer 10.104.39.177 <pending> 80:30778/TCP 2m44s
svc-nodeport NodePort 10.100.104.140 <none> 80:32335/TCP 2m54s
资源对象方式
查看对象标签
[root@kubernetes-master1 ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-f44f65dc-pbht6 1/1 Running 0 8h app=nginx,pod-template-hash=f44f65dc
简单实践
定制资源清单文件
[root@kubernetes-master1 ~]# mkdir /data/kubernetes/service -p ; cd /data/kubernetes/service
[root@kubernetes-master1 /data/kubernetes/service]#
[root@kubernetes-master1 /data/kubernetes/service]# vim 01_kubernetes-service_test.yml
apiVersion: v1
kind: Service
metadata:
name: superopsmsb-nginx-service
spec:
selector:
app: nginx
ports:
- name: http
port: 80
应用资源清单文件
[root@kubernetes-master1 /data/kubernetes/service]# kubectl apply -f 01_kubernetes-service_test.yml
service/superopsmsb-nginx-service created
查看service效果
[root@kubernetes-master1 /data/kubernetes/service]# kubectl describe svc superopsmsb-nginx-service
Name: superopsmsb-nginx-service
...
IP: 10.109.240.56
IPs: 10.109.240.56
Port: http 8000/TCP
TargetPort: 8000/TCP
Endpoints: 10.244.3.63:8000
...
访问service
[root@kubernetes-master1 /data/kubernetes/service]# curl -s 10.101.25.116 -I | head -n1
HTTP/1.1 200 OK
NodePort实践
属性解读
NodePort会在所有的节点主机上,暴露一个指定或者随机的端口,供外部的服务能够正常的访问pod内部的资源。
简单实践
[root@kubernetes-master1 /data/kubernetes/service]# vim 02_kubernetes-service_nodePort.yml
apiVersion: v1
kind: Service
metadata:
name: superopsmsb-nginx-nodeport
spec:
selector:
app: nginx
ports:
- name: http
port: 80
nodePort: 30080
应用资源清单文件
[root@kubernetes-master1 /data/kubernetes/service]# kubectl apply -f 02_kubernetes-service_nodePort.yml
service/superopsmsb-nginx-nodeport created
检查效果
[root@kubernetes-master1 /data/kubernetes/service]# kubectl describe svc superopsmsb-nginx-nodeport
Name: superopsmsb-nginx-nodeport
...
Type: NodePort
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.102.1.177
IPs: 10.102.1.177
Port: http 80/TCP
TargetPort: 80/TCP
NodePort: http 30080/TCP
...
访问效果
[root@kubernetes-master1 /data/kubernetes/service]# curl 10.0.0.12:30080 Hello Nginx, nginx-6944855df5-8zjdn-1.23.0
小结
1.1.4 IPVS实践
学习目标
这一节,我们从 基础知识、简单实践、小结 三个方面来学习。
基础知识
简介

关键点:
ipvs会在每个节点上创建一个名为kube-ipvs0的虚拟接口,并将集群所有Service对象的ClusterIP和ExternalIP都配置在该接口;
- 所以每增加一个ClusterIP 或者 EternalIP,就相当于为 kube-ipvs0 关联了一个地址罢了。
kube-proxy为每个service生成一个虚拟服务器( IPVS Virtual Server)的定义。
基本流程:
所以当前节点接收到外部流量后,如果该数据包是交给当前节点上的clusterIP,则会直接将数据包交给kube-ipvs0,而这个接口是内核虚拟出来的,而kube-proxy定义的VS直接关联到kube-ipvs0上。
如果是本地节点pod发送的请求,基本上属于本地通信,效率是非常高的。
默认情况下,这里的ipvs使用的是nat转发模型,而且支持更多的后端调度算法。仅仅在涉及到源地址转换的场景中,会涉及到极少量的iptables规则(应该不会超过20条)
前提:当前操作系统需要提前加载ipvs模块
yum install ipvsadm -y
kube-proxy
对于k8s来说,默认情况下,支持的规则是 iptables,我们可以通过多种方式对我们的代理模式进行更改,因为这些规则都是基于kube-proxy来定制的,所以,我们如果要更改代理模式的话,就需要调整kube-proxy的属性。
在k8s集群中,关于kube-proxy的所有属性信息,我们可以通过一个 configmap 的资源对象来了解一下
[root@kubernetes-master1 ~]# kubectl describe configmap kube-proxy -n kube-system
Name: kube-proxy
Namespace: kube-system
Labels: app=kube-proxy
...
iptables:
masqueradeAll: false # 这个属性打开的话,会对所有的请求都进行源地址转换
...
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: "" # 调度算法,默认是randomrobin
...
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: "" # 默认没有指定,就是使用 iptables 规则
...
查看默认模式
通过kube-proxy-b8dpc的pod日志查看模式
[root@kubernetes-master1 /data/kubernetes/service]# kubectl logs kube-proxy-b8dpc -n kube-system
...
I0719 08:39:44.410078 1 server_others.go:561] "Unknown proxy mode, assuming iptables proxy" proxyMode=""
I0719 08:39:44.462438 1 server_others.go:206] "Using iptables Proxier"
...
简单实践
准备
清理所有svc
[root@kubernetes-master1 /data/kubernetes/service]# for i in $(kubectl get svc | egrep -v 'NAME|kubernetes' | awk '{print $1}')
> do
> kubectl delete svc $i
> done
修改kube-proxy模式
我们在测试环境中,临时修改一下configmap中proxy的基本属性 - 临时环境推荐
[root@kubernetes-master1 /data/kubernetes/service]# kubectl edit configmap kube-proxy -n kube-system
...
mode: "ipvs"
...
重启所有的kube-proxy pod对象
[root@kubernetes-master1 /data/kubernetes/service]# kubectl delete pod -n kube-system -l k8s-app=kube-proxy
通过kube-proxy的pod日志查看模式
[root@kubernetes-master1 /data/kubernetes/service]# kubectl logs kube-proxy-fb9pz -n kube-system
...
I0721 10:31:40.408116 1 server_others.go:269] "Using ipvs Proxier"
I0721 10:31:40.408155 1 server_others.go:271] "Creating dualStackProxier for ipvs"
...
测试效果
安装参考命令
[root@kubernetes-master1 /data/kubernetes/service]# yum install ipvsadm -y
查看规则效果
[root@kubernetes-master1 /data/kubernetes/service]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.17.0.1:30443 rr
-> 10.244.3.2:8443 Masq 1 0 0
...
创建一个service
[root@kubernetes-master1 /data/kubernetes/service]# kubectl apply -f 02_kubernetes-service_nodePort.yml
service/superopsmsb-nginx-nodeport created
查看svc的ip
[root@kubernetes-master1 /data/kubernetes/service]# kubectl get svc superopsmsb-nginx-nodeport -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
superopsmsb-nginx-nodeport NodePort 10.106.138.242 <none> 80:30080/TCP 23s app=nginx
查看ipvsadm规则
[root@kubernetes-master1 /data/kubernetes/service]# ipvsadm -Ln | grep -A1 10.106.138.242
TCP 10.106.138.242:80 rr
-> 10.244.3.64:80 Masq 1 0 0
查看防火墙规则
[root@kubernetes-master1 /data/kubernetes/service]# iptables -t nat -S KUBE-NODE-PORT
-N KUBE-NODE-PORT
-A KUBE-NODE-PORT -p tcp -m comment --comment "Kubernetes nodeport TCP port for masquerade purpose" -m set --match-set KUBE-NODE-PORT-TCP dst -j KUBE-MARK-MASQ
结果显示:
没有生成对应的防火墙规则
小结
1.2 其他资源
1.2.1 域名服务
学习目标
这一节,我们从 场景需求、域名测试、小结 三个方面来学习。
场景需求
简介
在传统的系统部署中,服务运行在一个固定的已知的 IP 和端口上,如果一个服务需要调用另外一个服务,可以通过地址直接调用,但是,在虚拟化或容器话的环境中,以我们的k8s集群为例,如果存在个位数个service我们可以很快的找到对应的clusterip地址,进而找到指定的资源,虽然ip地址不容易记住,因为service在创建的时候会为每个clusterip分配一个名称,我们同样可以根据这个名称找到对应的服务。但是,如果我们的集群中有1000个Service,我们如何找到指定的service呢?
虽然我们可以借助于传统的DNS机制来实现,但是在k8s集群中,服务实例的启动和销毁是很频繁的,服务地址在动态的变化,所以传统的方式配置DNS解析记录就不太好实现了。所以针对于这种场景,我们如果需要将请求发送到动态变化的服务实例上,可以通过一下两个步骤来实现:
服务注册 — 创建服务实例后,主动将当前服务实例的信息,存储到一个集中式的服务管理中心。
服务发现 — 当A服务需要找未知的B服务时,先去服务管理中心查找B服务地址,然后根据该地址找到B服务
DNS方案
专用于kubernetes集群中的服务注册和发现的解决方案就是KubeDNS。kubeDNS自从k8s诞生以来,其方案的具体实现样式前后经历了三代,分别是 SkyDNS、KubeDNS、CoreDNS(目前默认的)。

域名解析记录
Kubelet会为创建的每一个容器于/etc/resolv.conf配置文件中生成DNS查询客户端依赖到的必要配置,相关的配置信息源自于kubelet的配置参数,容器的DNS服务器由clusterDNS参数的值设定,它的取值为kube-system名称空间中的Service对象kube-dns的ClusterIP,默认为10.96.0.10.
DNS搜索域的值由clusterDomain参数的值设定,若部署Kubernetes集群时未特别指定,其值将为cluster.local、svc.cluster.local和NAMESPACENAME.svc.cluster.local
kubeadm 1.23.8 环境初始化配置文件中与dns相关的检索信息
[root@kubernetes-master1 ~]# grep -A1 networking /data/kubernetes/cluster_init/kubeadm_init_1.23.8.yml
networking:
dnsDomain: cluster.local
资源对象的dns记录
对于kubernetes的内部资源对象来说,为了更好的绕过变化频率更高的ip地址的限制,它可以在内部以dns记录的方式进行对象发现,dns记录具有标准的名称格式:
资源对象名.命名空间名.svc.cluster.local
域名测试
创建一个svc记录
[root@kubernetes-master1 /data/kubernetes/service]# kubectl apply -f 01_kubernetes-service_test.yml
service/superopsmsb-nginx-service created
[root@kubernetes-master1 /data/kubernetes/service]# kubectl get svc superopsmsb-nginx-service -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
superopsmsb-nginx-service ClusterIP 10.97.135.126 <none> 80/TCP 23s app=nginx
资源对象的名称记录
查看本地的pod效果
[root@kubernetes-master1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-6944855df5-8zjdn 1/1 Running 0 38m
查看pod内部的resolv.conf文件
[root@kubernetes-master1 ~]# kubectl exec -it nginx-6944855df5-8zjdn -- cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local localhost
options ndots:5
可以看到:
资源对象的查看dns的后缀主要有四种:
default.svc.cluster.local
svc.cluster.local
cluster.local
localhost
查看内部的资源对象完整域名
[root@kubernetes-master1 /data/kubernetes/service]# kubectl exec -it nginx-6944855df5-8zjdn -- /bin/bash
root@nginx-6944855df5-8zjdn:/# curl
curl: try 'curl --help' or 'curl --manual' for more information
root@nginx-6944855df5-8zjdn:/# curl superopsmsb-nginx-service
Hello Nginx, nginx-6944855df5-8zjdn-1.23.0
root@nginx-6944855df5-8zjdn:/# curl superopsmsb-nginx-service.default.svc.cluster.local
Hello Nginx, nginx-6944855df5-8zjdn-1.23.0
root@nginx-6944855df5-8zjdn:/# curl superopsmsb-nginx-service.default.svc.cluster.local.
Hello Nginx, nginx-6944855df5-8zjdn-1.23.0
内部dns测试效果
安装dns测试工具
root@nginx-6944855df5-8zjdn:/# apt update
root@nginx-6944855df5-8zjdn:/# apt install dnsutils -y
资源对象的查看效果
root@nginx-6944855df5-8zjdn:/# nslookup superopsmsb-nginx-service
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: superopsmsb-nginx-service.default.svc.cluster.local
Address: 10.97.135.126
root@nginx-6944855df5-8zjdn:/# nslookup 10.97.135.126
126.135.97.10.in-addr.arpa name = superopsmsb-nginx-service.default.svc.cluster.local.
root@nginx-6944855df5-8zjdn:/# nslookup kubernetes
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: kubernetes.default.svc.cluster.local
Address: 10.96.0.1
查看跨命名空间的资源对象
[root@kubernetes-master1 ~]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 2d2h
回到pod终端查看效果
root@nginx-6944855df5-8zjdn:/# nslookup kube-dns.kube-system.svc.cluster.local
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: kube-dns.kube-system.svc.cluster.local
Address: 10.96.0.10
root@nginx-6944855df5-8zjdn:/# nslookup 10.96.0.10
10.0.96.10.in-addr.arpa name = kube-dns.kube-system.svc.cluster.local.
root@nginx-6944855df5-8zjdn:/# nslookup kube-dns
Server: 10.96.0.10
Address: 10.96.0.10#53
** server can't find kube-dns: NXDOMAIN
结果显示:
对于跨命名空间的资源对象必须使用完整的名称格式
pod资源对象解析
查看pod资源对象
[root@kubernetes-master1 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP ...
nginx-6944855df5-8zjdn 1/1 Running 0 56m 10.244.3.64 ...
构造资源对象名,pod的ip名称转换
root@nginx-6944855df5-8zjdn:/# nslookup 10-244-3-64.superopsmsb-nginx-service.default.svc.cluster.local. Server: 10.96.0.10
Address: 10.96.0.10#53
Name: 10-244-3-64.superopsmsb-nginx-service.default.svc.cluster.local
Address: 10.244.3.64
小结
1.2.2 CoreDNS
学习目标
这一节,我们从 基础知识、简单实践、小结 三个方面来学习。
基础知识
简介
coredns是一个用go语言编写的开源的DNS服务,coredns是首批加入CNCF组织的云原生开源项目,并且作为已经在CNCF毕业的项目,coredns还是目前kubernetes中默认的dns服务。同时,由于coredns可以集成插件,它还能够实现服务发现的功能。
coredns和其他的诸如bind、knot、powerdns、unbound等DNS服务不同的是:coredns非常的灵活,并且几乎把所有的核心功能实现都外包给了插件。如果你想要在coredns中加入Prometheus的监控支持,那么只需要安装对应的prometheus插件并且启用即可。
配置解析
coredns的配置依然是存放在 configmap中
[root@kubernetes-master1 ~]# kubectl get cm coredns -n kube-system
NAME DATA AGE
coredns 1 2d2h
查看配置详情
[root@kubernetes-master1 ~]# kubectl describe cm coredns -n kube-system
Name: coredns
Namespace: kube-system
Labels: <none>
Annotations: <none>
Data
====
Corefile:
----
.:53 {
errors
health { # 健康检测
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa { # 解析配置
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf { # 转发配置
max_concurrent 1000
}
cache 30
loop
reload # 自动加载
loadbalance
}
BinaryData
====
Events: <none>
其他属性和示例:
except domain 排除的域名
添加dns解析
hosts {
192.168.8.100 www.example.com
fallthrough # 在CoreDNS里面表示如果自己无法处理,则交由下个插件处理。
}
简单实践
修改实践
修改配置文件
[root@kubernetes-master1 ~]# kubectl edit cm coredns -n kube-system
...
forward . /etc/resolv.conf {
max_concurrent 1000
except www.baidu.com.
}
hosts {
10.0.0.20 harbor.superopsmsb.com
fallthrough
}
...
注意:
多个dns地址间用空格隔开
排除的域名最好在末尾添加 “.”,对于之前的旧版本来说可能会出现无法保存的现象
测试效果
同步dns的配置信息
[root@kubernetes-master1 ~]# kubectl delete pod -l k8s-app=kube-dns -n kube-system
pod "coredns-5d555c984-fmrht" deleted
pod "coredns-5d555c984-scvjh" deleted
删除旧pod,使用新pod测试 (可以忽略)
[root@kubernetes-master1 /data/kubernetes/service]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-6944855df5-8zjdn 1/1 Running 0 70m
[root@kubernetes-master1 /data/kubernetes/service]# kubectl delete pod nginx-6944855df5-8zjdn
pod "nginx-6944855df5-8zjdn" deleted
pod中测试效果
[root@kubernetes-master1 /data/kubernetes/service]# kubectl exec -it nginx-6944855df5-9s4bd -- /bin/bash
root@nginx-6944855df5-9s4bd:/# apt update ; apt install dnsutils -y
测试效果
root@nginx-6944855df5-9s4bd:/# nslookup www.baidu.com
Server: 10.96.0.10
Address: 10.96.0.10#53
** server can't find www.baidu.com: SERVFAIL
root@nginx-6944855df5-9s4bd:/# nslookup harbor.superopsmsb.com
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: harbor.superopsmsb.com
Address: 10.0.0.20
清理环境
将之前的配置清理掉
1.2.3 无头服务
学习目标
这一节,我们从 基础知识、简单实践、小结 三个方面来学习。
基础知识
简介
在kubernetes中,有一种特殊的无头service,它本身是Service,但是没有ClusterIP,这种svc在一些有状态的场景中非常重要。
无头服务场景下,k8s会将一个集群内部的所有成员提供唯一的DNS域名来作为每个成员的网络标识,集群内部成员之间使用域名通信,这个时候,就特别依赖service的selector属性配置了。
无头服务管理的域名是如下的格式:$(service_name).$(k8s_namespace).svc.cluster.local。
pod资源对象的解析记录
dns解析记录
A记录
<a>-<b>-<c>-<d>.<service>.<ns>.svc.<zone> A PodIP
关键点:
svc_name的解析结果从常规Service的ClusterIP,转为各个Pod的IP地址;
反解,则从常规的clusterip解析为service name,转为从podip到hostname, <a>-<b>-<c>-<d>.<service>.<ns>.svc.<zone>
<hostname>指的是a-b-c-d格式,而非Pod自己的主机名;
简单实践
准备工作
扩展pod对象数量
[root@kubernetes-master1 ~]# kubectl scale deployment nginx --replicas=3
deployment.apps/nginx scaled
[root@kubernetes-master1 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP ...
nginx-6944855df5-9m44b 1/1 Running 0 5s 10.244.2.4 ...
nginx-6944855df5-9s4bd 1/1 Running 0 14m 10.244.3.2 kubernetes-node3 <none> <none>
nginx-6944855df5-mswl4 1/1 Running 0 5s 10.244.1.3 kubernetes-node2 <none> <none>
定制无头服务
手工定制无头服务
[root@kubernetes-master1 ~]# kubectl create service clusterip service-headless --clusterip="None"
service/service-headless-cmd created
查看无头服务
[root@kubernetes-master1 ~]# kubectl get svc service-headless
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service-headless ClusterIP None <none> <none> 6s
资源清单文件定制无头服务
[root@kubernetes-master1 /data/kubernetes/service]# cat 03_kubernetes-service_headless.yml
apiVersion: v1
kind: Service
metadata:
name: superopsmsb-nginx-headless
spec:
selector:
app: nginx
ports:
- name: http
port: 80
clusterIP: "None"
应用资源对象
[root@kubernetes-master1 /data/kubernetes/service]# kubectl apply -f 03_kubernetes-service_headless.yml
service/superopsmsb-nginx-headless created
[root@kubernetes-master1 /data/kubernetes/service]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6m33s
service-headless ClusterIP None <none> <none> 61s
superopsmsb-nginx-headless ClusterIP None <none> 80/TCP 7s
测试效果
进入测试容器
[root@kubernetes-master1 /data/kubernetes/service]# kubectl exec -it nginx-fd669dcb-h5d9d -- /bin/bash
root@nginx-fd669dcb-h5d9d:/# nslookup superopsmsb-nginx-headless
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: superopsmsb-nginx-headless.default.svc.cluster.local
Address: 10.244.2.4
Name: superopsmsb-nginx-headless.default.svc.cluster.local
Address: 10.244.1.3
Name: superopsmsb-nginx-headless.default.svc.cluster.local
Address: 10.244.3.2
结果显式:
由于我们没有对域名做定向解析,那么找请求的时候,就像无头苍蝇似的,到处乱串
小结
1.3 flannel方案
1.3.1 网络方案
学习目标
这一节,我们从 存储原理、方案解读、小结 三个方面来学习。
存储原理
容器实现网络访问样式

1 虚拟网桥:
brdige,用纯软件的方式实现一个虚拟网络,用一个虚拟网卡接入到我们虚拟网桥上去。这样就能保证每一个容器和每一个pod都能有一个专用的网络接口,从而实现每一主机组件有网络接口。
2 多路复用:
MacVLAN,借助于linux内核级的VLAN模块,在同一个物理网卡上配置多个 MAC 地址,每个 MAC 给一个Pod使用,然后借助物理网卡中的MacVLAN机制进行跨节点之间进行通信了。
3 硬件交换:
很多网卡都已经支持"单根IOV的虚拟化"了,借助于单根IOV(SR-IOV)的方式,直接在物理主机虚拟出多个接口来,通信性能很高,然后每个虚拟网卡能够分配给容器使用。
容器网络方案
任何一种能够让容器自由通信的网络解决方案,必须包含三个功能:
1 构建一个网络
2 将容器接入到这个网络中
3 实时维护所有节点上的路由信息,实现容器的通信
CNI方案
1 所有节点的内核都启用了VXLAN的功能模块
每个节点都启动一个cni网卡,并维护所有节点所在的网段的路由列表
2 node上的pod发出请求到达cni0
根据内核的路由列表判断对端网段的节点位置
经由 隧道设备 对数据包进行封装标识,对端节点的隧道设备解封标识数据包,
当前数据包一看当前节点的路由表发现有自身的ip地址,这直接交给本地的pod
3 多个节点上的路由表信息维护,就是各种网络解决方案的工作位置
注意:
我们可以部署多个网络解决方案,但是对于CNI来说,只会有一个生效。如果网络信息过多会导致冲突

方案解读
CNI插件
根据我们刚才对pod通信的回顾,多节点内的pod通信,k8s是通过CNI接口来实现网络通信的。CNI基本思想:创建容器时,先创建好网络名称空间,然后调用CNI插件配置这个网络,而后启动容器内的进程
CNI插件类别:main、meta、ipam
main,实现某种特定的网络功能,如loopback、bridge、macvlan、ipvlan
meta,自身不提供任何网络实现,而是调用其他插件,如flannel
ipam,仅用于分配IP地址,不提供网络实现
常见方案
Flannel
提供叠加网络,基于linux TUN/TAP,使用UDP封装IP报文来创建叠加网络,并借助etcd维护网络分配情况
Calico
基于BGP的三层网络,支持网络策略实现网络的访问控制。在每台机器上运行一个vRouter,利用内核转发数据包,并借助iptables实现防火墙等功能
kube-router
K8s网络一体化解决方案,可取代kube-proxy实现基于ipvs的Service,支持网络策略、完美兼容BGP的高级特性
其他网络解决方案:
Canal: 由Flannel和Calico联合发布的一个统一网络插件,支持网络策略
Weave Net: 多主机容器的网络方案,支持去中心化的控制平面
Contiv:思科方案,直接提供多租户网络,支持L2(VLAN)、L3(BGP)、Overlay(VXLAN)
更多的解决方案,大家可以参考:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
小结
1.3.2 flannel
学习目标
这一节,我们从 信息查看、原理解读、小结 三个方面来学习。
信息查看
查看网络配置
[root@kubernetes-master1 ~]# cat /etc/kubernetes/manifests/kube-controller-manager.yaml
apiVersion: v1
...
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
...
- --cluster-cidr=10.244.0.0/16
配置解析:
allocate-node-cidrs属性表示,每增加一个新的节点,都从cluster-cidr子网中切分一个新的子网网段分配给对应的节点上。
这些相关的网络状态属性信息,会经过 kube-apiserver 存储到etcd中。
CNI配置
使用CNI插件编排网络,Pod初始化或删除时,kubelet会调用默认CNI插件,创建虚拟设备接口附加到相关的底层网络,设置IP、路由并映射到Pod对象网络名称空间.
kubelet在/etc/cni/net.d目录查找cni json配置文件,基于type属性到/opt/cni/bin中查找相关插件的二进制文件,然后调用相应插件设置网络
网段配置
查看网段配置
[root@kubernetes-master1 ~]# cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
网段分配原理
分配原理解读
集群的 kube-controller-manager 负责控制每个节点的网段分配
集群的 etcd 负责存储所有节点的网络配置存储
集群的 flannel 负责各个节点的路由表定制及其数据包的拆分和封装
-- 所以flannel各个节点是平等的,仅负责数据平面的操作。网络功能相对来说比较简单。
另外一种插件 calico相对于flannel来说,多了一个控制节点,来管控所有的网络节点的服务进程。
flannel网络
pod效果
[root@kubernetes-master1 ~]# kubectl get pod -n kube-flannel -o wide
NAME READY STATUS ... IP NODE ...
kube-flannel-ds-b6hxm 1/1 Running ... 10.0.0.15 kubernetes-node1 ...
kube-flannel-ds-bx7rq 1/1 Running ... 10.0.0.12 kubernetes-master1 ...
kube-flannel-ds-hqwrk 1/1 Running ... 10.0.0.13 kubernetes-master2 ...
kube-flannel-ds-npcw6 1/1 Running ... 10.0.0.17 kubernetes-node3 ...
kube-flannel-ds-sx427 1/1 Running ... 10.0.0.14 kubernetes-master3 ...
kube-flannel-ds-v5f4p 1/1 Running ... 10.0.0.16 kubernetes-node2 ...
网卡效果
[root@kubernetes-master1 ~]# for i in {12..17};do ssh root@10.0.0.$i ifconfig | grep -A1 flannel ;done
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.0 netmask 255.255.255.255 broadcast 0.0.0.0
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.4.0 netmask 255.255.255.255 broadcast 0.0.0.0
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.5.0 netmask 255.255.255.255 broadcast 0.0.0.0
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.1.0 netmask 255.255.255.255 broadcast 0.0.0.0
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.2.0 netmask 255.255.255.255 broadcast 0.0.0.0
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.3.0 netmask 255.255.255.255 broadcast 0.0.0.0
注意:
flannel.1 后面的.1 就是 vxlan的网络标识。便于隧道正常通信。
路由效果
[root@kubernetes-master1 ~]# ip route list | grep flannel
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink
10.244.3.0/24 via 10.244.3.0 dev flannel.1 onlink
10.244.4.0/24 via 10.244.4.0 dev flannel.1 onlink
10.244.5.0/24 via 10.244.5.0 dev flannel.1 onlink
原理解读
flannel模型
vxlan模型
pod与Pod经由隧道封装后通信,各节点彼此间能通信就行,不要求在同一个二层网络
这是默认采用的方式
host-gw模型
Pod与Pod不经隧道封装而直接通信,要求各节点位于同一个二层网络
vxlan directrouting模型
它是vxlan和host-gw自由组合的一种模型
位于同一个二层网络上的、但不同节点上的Pod间通信,无须隧道封装;但非同一个二层网络上的节点上的Pod间通信,仍须隧道封装

vxlan原理
1 节点上的pod通过虚拟网卡对,连接到cni0的虚拟网络交换机上
当有外部网络通信的时候,借助于 flannel.1网卡向外发出数据包
2 经过 flannel.1 网卡的数据包,借助于flanneld实现数据包的封装和解封
最后送给宿主机的物理接口,发送出去
3 对于pod来说,它以为是通过 flannel.x -> vxlan tunnel -> flannel.x 实现数据通信
因为它们的隧道标识都是".1",所以认为是一个vxlan,直接路由过去了,没有意识到底层的通信机制。
注意:
由于这种方式,是对数据报文进行了多次的封装,降低了当个数据包的有效载荷。所以效率降低了
host-gw原理
1 节点上的pod通过虚拟网卡对,连接到cni0的虚拟网络交换机上。
2 pod向外通信的时候,到达CNI0的时候,不再直接交给flannel.1由flanneld来进行打包处理了。
3 cni0直接借助于内核中的路由表,通过宿主机的网卡交给同网段的其他主机节点
4 对端节点查看内核中的路由表,发现目标就是当前节点,所以交给对应的cni0,进而找到对应的pod。
小结
1.3.3 主机网络
学习目标
这一节,我们从 配置解读、简单实践、小结 三个方面来学习。
配置解读
配置文件
我们在部署flannel的时候,有一个配置文件,在这个配置文件中的configmap中就定义了虚拟网络的接入功能。
[root@kubernetes-master1 /data/kubernetes/flannel]# cat kube-flannel.yml
kind: ConfigMap
...
data:
cni-conf.json: | cni插件的功能配置
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel", 基于flannel实现网络通信
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap", 来实现端口映射的功能
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: | flannel的网址分配
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan" 来新节点的时候,基于vxlan从network中获取子网
}
}
路由表信息
[root@kubernetes-master1 ~]# ip route list | grep flannel
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink
10.244.3.0/24 via 10.244.3.0 dev flannel.1 onlink
10.244.4.0/24 via 10.244.4.0 dev flannel.1 onlink
10.244.5.0/24 via 10.244.5.0 dev flannel.1 onlink
结果显示:
如果数据包的目标是当前节点,这直接通过cni来进行处理
如果数据包的目标是其他节点,这根据路由配置,交给对应节点上的flannel.1网卡来进行处理
然后交给配套的flanneld对数据包进行封装
数据包转发解析
发现目标地址
[root@kubernetes-master1 /data/kubernetes/flannel]# ip neigh | grep flannel
10.244.2.0 dev flannel.1 lladdr ca:d2:1b:08:40:c2 PERMANENT
10.244.5.0 dev flannel.1 lladdr 92:d8:04:76:cf:af PERMANENT
10.244.1.0 dev flannel.1 lladdr ae:08:68:7d:fa:31 PERMANENT
10.244.4.0 dev flannel.1 lladdr c2:ef:c2:a6:aa:04 PERMANENT
10.244.3.0 dev flannel.1 lladdr ee:dd:92:60:41:8a PERMANENT
转发给指定主机
[root@kubernetes-master1 /data/kubernetes/flannel]# bridge fdb show flannel.1 | grep flannel.1
ee:dd:92:60:41:8a dev flannel.1 dst 10.0.0.17 self permanent
ae:08:68:7d:fa:31 dev flannel.1 dst 10.0.0.15 self permanent
c2:ef:c2:a6:aa:04 dev flannel.1 dst 10.0.0.13 self permanent
ca:d2:1b:08:40:c2 dev flannel.1 dst 10.0.0.16 self permanent
92:d8:04:76:cf:af dev flannel.1 dst 10.0.0.14 self permanent
测试效果
准备工作
[root@kubernetes-master1 ~]# kubectl scale deployment nginx --replicas=1
deployment.apps/nginx scaled
开启测试容器
[root@kubernetes-master1 ~]# kubectl run flannel-test --image="kubernetes-register.superopsmsb.com/superopsmsb/busybox:1.28" -it --rm --command -- /bin/sh
pod现状
[root@kubernetes-master1 ~]# kubectl get pod -o wide
NAME ... IP NODE ...
flannel-test ... 10.244.1.4 kubernetes-node1 ...
nginx-fd669dcb-h5d9d ... 10.244.3.2 kubernetes-node3 ...
测试容器发送测试数据
[root@kubernetes-master1 ~]# kubectl run flannel-test --image="kubernetes-register.superopsmsb.com/superopsmsb/busybox:1.28" -it --rm --command -- /bin/sh
If you don't see a command prompt, try pressing enter.
/ # ping -c 1 10.244.3.2
PING 10.244.3.2 (10.244.3.2): 56 data bytes
64 bytes from 10.244.3.2: seq=0 ttl=62 time=1.479 ms
...
Flannel默认使用8285端口作为UDP封装报文的端口,VxLan使用8472端口,我们在node3上抓取node1的数据包
[root@kubernetes-node3 ~]# tcpdump -i eth0 -en host 10.0.0.15 and udp port 8472
...
07:46:40.104526 00:50:56:37:14:42 > 00:50:56:37:ed:73, ethertype IPv4 (0x0800), length 148: 10.0.0.17.53162 > 10.0.0.15.otv: OTV, flags [I] (0x08), overlay 0, instance 1
ee:dd:92:60:41:8a > ae:08:68:7d:fa:31, ethertype IPv4 (0x0800), length 98: 10.244.3.2 > 10.244.1.4: ICMP echo reply, id 1792, seq 0, length 64
结果显示:
这里面每一条数据,都包括了两层ip数据包
host-gw实践
修改flannel的配置文件,将其转换为 host-gw 模型。
[root@kubernetes-master1 ~]# kubectl get cm -n kube-flannel
NAME DATA AGE
kube-flannel-cfg 2 82m
修改资源配置文件
[root@kubernetes-master1 ~]# kubectl edit cm kube-flannel-cfg -n kube-flannel
...
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "host-gw"
}
}
重启pod
[root@kubernetes-master1 ~]# kubectl delete pod -n kube-flannel -l app
[root@kubernetes-master1 ~]# kubectl get pod -n kube-flannel
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-5dw2r 1/1 Running 0 21s
kube-flannel-ds-d9bh2 1/1 Running 0 21s
kube-flannel-ds-jvn2f 1/1 Running 0 21s
kube-flannel-ds-kcrb4 1/1 Running 0 22s
kube-flannel-ds-ptlx8 1/1 Running 0 21s
kube-flannel-ds-wxqd7 1/1 Running 0 22s
检查信息文章来源:https://www.toymoban.com/news/detail-517473.html
查看路由信息
[root@kubernetes-master1 ~]# ip route list | grep 244
10.244.1.0/24 via 10.0.0.15 dev eth0
10.244.2.0/24 via 10.0.0.16 dev eth0
10.244.3.0/24 via 10.0.0.17 dev eth0
10.244.4.0/24 via 10.0.0.13 dev eth0
10.244.5.0/24 via 10.0.0.14 dev eth0
在flannel-test中继续wget测试
/ # wget 10.244.3.2
Connecting to 10.244.3.2 (10.244.3.2:80)
index.html 100% |***| 41 0:00:00 ETA
在node3中继续抓包
[root@kubernetes-node3 ~]# tcpdump -i eth0 -nn host 10.244.1.4 and tcp port 80
...
08:01:46.930340 IP 10.244.3.2.80 > 10.244.1.4.59026: Flags [FP.], seq 232:273, ack 74, win 56, length 41: HTTP
08:01:46.930481 IP 10.244.1.4.59026 > 10.244.3.2.80: Flags [.], ack 232, win 58, length 0
08:01:46.931619 IP 10.244.1.4.59026 > 10.244.3.2.80: Flags [F.], seq 74, ack 274, win 58, length 0
08:01:46.931685 IP 10.244.3.2.80 > 10.244.1.4.59026: Flags [.], ack 75, win 56, length 0
结果显示:
两个pod形成了直接的通信效果。
小结文章来源地址https://www.toymoban.com/news/detail-517473.html
到了这里,关于K8S网络管理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!