序言
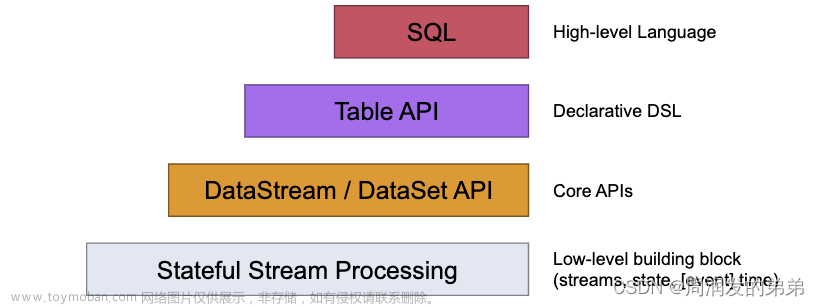
本次主要是弄清楚.批流统一 的处理方式,因为它是使用SQL来操作批流计算的.所以它怎么设置算子并行度?如何设置窗口?如何处理流式数据?等等 有很多疑问.
我还是觉得直接使用流计算的API更好.流批一体API最终也是转换成流式计算,最主要的是使用sql来设置算子或者窗口,并不直观. 本身就是转换流操作,我们可以知接使用流.另外,在1.12版本说的是流批一体并不成熟,现在到了1.17虽然没说不成熟,但是还是有BUG .截图如下

动态表 & 连续查询(Continuous Query)
先看批流一体与传统的区别
| 关系型数据库 | 流处理 |
|---|---|
| 关系(或表)是有界(多)元组集合。 | 流是一个无限元组序列。 |
| 对批数据(例如关系数据库中的表)执行的查询可以访问完整的输入数据。 | 流式查询在启动时不能访问所有数据,必须“等待”数据流入。 |
| 批处理查询在产生固定大小的结果后终止。 | 流查询不断地根据接收到的记录更新其结果,并且始终不会结束。 |
理解Flink官网说的 :
- 动态表 就是不断变化的表(包含了insert ,delete ,update多种操作),
- 连续查询就是说 持续的查询动态表的最新变化的数据.
动态表 是 Flink 的支持流数据的 Table API 和 SQL 的核心概念。与表示批处理数据的静态表不同,动态表是随时间变化的。可以像查询静态批处理表一样查询它们。
查询动态表将生成一个 连续查询 。一个连续查询永远不会终止,结果会生成一个动态表。查询不断更新其(动态)结果表,以反映其(动态)输入表上的更改。本质上,动态表上的连续查询非常类似于定义物化视图的查询。
需要注意的是,连续查询的结果在语义上总是等价于以批处理模式在输入表快照上执行的相同查询的结果。
下图显示了流、动态表和连续查询之间的关系:

- 将流转换为动态表。(动态输入表)
- 在动态表上计算一个连续查询,生成一个新的动态表。(动态结果表)
- 生成的动态表被转换回流。
流转动态表
首先定义个表结构
[
user: VARCHAR, // 用户名
cTime: TIMESTAMP, // 访问 URL 的时间
url: VARCHAR // 用户访问的 URL
]为了使用关系查询处理流,必须将其转换成 Table。从概念上讲,流的每条记录都被解释为对结果表的 INSERT 操作。本质上我们正在从一个 INSERT-only 的 changelog 流构建表。
下图显示了单击事件流(左侧)如何转换为表(右侧)。当插入更多的单击流记录时,结果表将不断增长。

注意: 在流上定义的表在内部没有物化。
连续查询
连续查询的SQL 决定了程序的好坏,这里的SQL直接影响了:.cuiyaonan2000@163.com
- 动态结果表是否需要有更新操作,如果只有新增效率就很高.
- 以及中间中间状态结果的存储空间大小,如果算点多了,则内存的占有就会变大.
举例说明一下SQL是如何影响效率的.
比如我们以kafka为source ,那在写sql的时候如果用了group 统计,则会在动态结果表中产生update的操作信息,所以需要sink的服务支持能进行update的操作,如果不支持就会报错.另外什么情况会产生update操作可以查看SQL的api说明cuiyaonan2000@163.com
比如执行语句
Table table = tEnv.sqlQuery("SELECT id ,count(name) as mycount FROM jjjk group by id ");
2");
table.execute().print();打印信息是:

-是 撤回,+是操作后,I是插入,U是更新,D是删除
如 -U是撤回前的数据,+U是更新后的数据
如上的changelog 这种结果也可以通过版本表的查询操作来优化只获取最终结果,总之要和版本表一起看,你就会发现新大陆cuiyaonan2000@163.com
官方的例子
第一个查询是一个简单的 GROUP-BY COUNT 聚合查询。它基于 user 字段对 clicks 表进行分组,并统计访问的 URL 的数量。下面的图显示了当 clicks 表被附加的行更新时,查询是如何被评估的。

当查询开始,clicks 表(左侧)是空的。当第一行数据被插入到 clicks 表时,查询开始计算结果表。第一行数据 [Mary,./home] 插入后,结果表(右侧,上部)由一行 [Mary, 1] 组成。当第二行 [Bob, ./cart] 插入到 clicks 表时,查询会更新结果表并插入了一行新数据 [Bob, 1]。第三行 [Mary, ./prod?id=1] 将产生已计算的结果行的更新,[Mary, 1] 更新成 [Mary, 2]。最后,当第四行数据加入 clicks 表时,查询将第三行 [Liz, 1] 插入到结果表中。
第二条查询与第一条类似,但是除了用户属性之外,还将 clicks 分组至每小时滚动窗口中,然后计算 url 数量(基于时间的计算,例如基于特定时间属性的窗口,后面会讨论)。同样,该图显示了不同时间点的输入和输出,以可视化动态表的变化特性。

与前面一样,左边显示了输入表 clicks。查询每小时持续计算结果并更新结果表。clicks表包含四行带有时间戳(cTime)的数据,时间戳在 12:00:00 和 12:59:59 之间。查询从这个输入,后计算出两个结果行(每个 user 一个),并将它们附加到结果表中。对于 13:00:00 和 13:59:59 之间的下一个窗口,clicks 表包含三行,这将导致另外两行被追加到结果表。随着时间的推移,更多的行被添加到 click 中,结果表将被更新。----如此这般就不像第一个sql那样有更新操作,这里有有根据时间的窗口的插入操作cuiyaonan2000@163.com
如上连个查询的区别
- 第一个查询更新先前输出的结果,即定义结果表的 changelog 流包含
INSERT和UPDATE操作。 - 第二个查询只附加到结果表,即结果表的 changelog 流只包含
INSERT操作。
查询限制 #
- 状态大小: 连续查询在无界流上计算,通常应该运行数周或数月。因此,连续查询处理的数据总量可能非常大。必须更新先前输出的结果的查询需要维护所有输出的行,以便能够更新它们。例如,第一个查询示例需要存储每个用户的 URL 计数,以便能够增加该计数并在输入表接收新行时发送新结果。如果只跟踪注册用户,则要维护的计数数量可能不会太高。但是,如果未注册的用户分配了一个惟一的用户名,那么要维护的计数数量将随着时间增长,并可能最终导致查询失败。
-
计算更新: 有些查询需要重新计算和更新大量已输出的结果行,即使只添加或更新一条输入记录。显然,这样的查询不适合作为连续查询执行。下面的查询就是一个例子,它根据最后一次单击的时间为每个用户计算一个
RANK。一旦click表接收到一个新行,用户的lastAction就会更新,并必须计算一个新的排名。然而,由于两行不能具有相同的排名,所以所有较低排名的行也需要更新。
表到流的转换 #
有意思么,直接用流吧
具体参考动态表 (Dynamic Table) | Apache Flink
不确定性
引用 SQL 标准中对确定性的描述:“如果一个操作在重复相同的输入值时能保证计算出相同的结果,那么该操作就是确定性的”。
显然易见 Flink没法做到确定性, 同时批处理或者说传统数据库也没法做到确定性,比如查询最新的两条记录,虽然是同一条SQL但是,数据在一直插入,所以批处理也没法做到确定性cuiyaonan2000@163.com
如何减小Filnk的不确定性(最终还是要使用watermarket)
流查询中的不确定更新(NDU)问题通常不是直观的,可能较复杂的查询中一个微小条件的改动就可能产生 NDU 问题风险,从 1.16 版本开始,Flink SQL (FLINK-27849)引入了实验性的 NDU 问题处理机制 ’table.optimizer.non-deterministic-update.strategy’, 当开启
TRY_RESOLVE模式时,会检查流查询中是否存在 NDU 问题,并尝试消除由 Lookup Join 产生的不确定更新问题(内部会增加物化处理),如果还存在上述第 1 或 第 3 点因素无法自动消除,Flink SQL 会给出尽量详细的错误信息提示用户调整 SQL 来避免引入不确定性(考虑到物化带来的高成本和算子复杂性,目前还没有支持对应的自动解决机制)。
时间属性 #
参考流式计算的watermarket
Flink 可以基于几种不同的 时间 概念来处理数据。
-
处理时间 指的是执行具体操作时的机器时间(大家熟知的绝对时间, 例如 Java的
System.currentTimeMillis()) ) - 事件时间 指的是数据本身携带的时间。这个时间是在事件产生时的时间。
- 摄入时间 指的是数据进入 Flink 的时间;在系统内部,会把它当做事件时间来处理。
每种类型的表都可以有时间属性,可以在用:
- CREATE TABLE DDL创建表的时候指定、
- 可以在
DataStream中指定、 - 可以在定义
TableSource时指定。
一旦时间属性定义好,它就可以像普通列一样使用,也可以在时间相关的操作中使用。(因为是以SQl操作字段的方式来操作cuiyaonan)
只要时间属性没有被修改,而是简单地从一个表传递到另一个表,它就仍然是一个有效的时间属性。时间属性可以像普通的时间戳的列一样被使用和计算。一旦时间属性被用在了计算中,它就会被物化,进而变成一个普通的时间戳。普通的时间戳是无法跟 Flink 的时间以及watermark等一起使用的,所以普通的时间戳就无法用在时间相关的操作中。----即要用时间字段作为窗口使用,则不能参与到计算中cuiyaonan2000@163.com
处理时间 #
创建方式方法查看:
时间属性 | Apache Flink
事件时间 #
创建方式方法查看:
时间属性 | Apache Flink
时态表(Temporal Tables) #
时态表包含表的一个或多个有版本的表快照,跟踪所有变更记录时态表可以是一张的表(例如数据库表的 changelog,包含多个表快照),也可以是物化所有变更之后的表(例如数据库表,只有最新表快照)。-----像redis的备份一样,既可以是所有操作的集合 ,也可以是最终内存结果备份cuiyaonan2000@163.com
时态表是我们创建表的更细化的分类,主要应用于业务场景.是常规标与虚拟表的下层的分类.
版本: 时态表可以划分成一系列带版本的表快照集合,表快照中的版本代表了快照中所有记录的有效区间,有效区间的开始时间和结束时间可以通过用户指定,根据时态表是否可以追踪自身的历史版本与否,时态表可以分为 版本表 和 普通表。
- 版本表: 如果时态表中的记录可以追踪和并访问它的历史版本,这种表我们称之为版本表,来自数据库的 changelog 可以定义成版本表。 ---根据主键和时间来区分版本
- 普通表: 如果时态表中的记录仅仅可以追踪并和它的最新版本,这种表我们称之为普通表,来自数据库 或 HBase 的表可以定义成普通表。---最终的结果表
版本表说明
以订单流关联产品表这个场景举例,orders 表包含了来自 Kafka 的实时订单流,product_changelog 表来自数据库表 products 的 changelog , 产品的价格在数据库表 products 中是随时间实时变化的。
SELECT * FROM product_changelog;
(changelog kind) update_time product_id product_name price
================= =========== ========== ============ =====
+(INSERT) 00:01:00 p_001 scooter 11.11
+(INSERT) 00:02:00 p_002 basketball 23.11
-(UPDATE_BEFORE) 12:00:00 p_001 scooter 11.11
+(UPDATE_AFTER) 12:00:00 p_001 scooter 12.99
-(UPDATE_BEFORE) 12:00:00 p_002 basketball 23.11
+(UPDATE_AFTER) 12:00:00 p_002 basketball 19.99
-(DELETE) 18:00:00 p_001 scooter 12.99
表 product_changelog 表示数据库表 products不断增长的 changelog, 比如,产品 scooter 在时间点 00:01:00的初始价格是 11.11, 在 12:00:00 的时候涨价到了 12.99, 在 18:00:00 的时候这条产品价格记录被删除。
如果我们想输出 product_changelog 表在 10:00:00 对应的版本,表的内容如下所示(如此这般很好的能够帮助我们解决如何处理中间结果的问题,即changelog 中间的新增修改操作如何屏蔽cuiyaonan2000@163.com):
update_time product_id product_name price
=========== ========== ============ =====
00:01:00 p_001 scooter 11.11
00:02:00 p_002 basketball 23.11
如果我们想输出 product_changelog 表在 13:00:00 对应的版本,表的内容如下所示:
update_time product_id product_name price
=========== ========== ============ =====
12:00:00 p_001 scooter 12.99
12:00:00 p_002 basketball 19.99
上述例子中,products 表的版本是通过 update_time 和 product_id 进行追踪的,product_id 对应 product_changelog 表的主键,update_time 对应事件时间。
普通表说明
另一方面,某些用户案列需要连接变化的维表,该表是外部数据库表。
假设 LatestRates 是一个物化的最新汇率表 (比如:一张 HBase 表),LatestRates 总是表示 HBase 表 Rates 的最新内容。
我们在 10:15:00 时查询到的内容如下所示:
10:15:00 > SELECT * FROM LatestRates;
currency rate
========= ====
US Dollar 102
Euro 114
Yen 1
我们在 11:00:00 时查询到的内容如下所示:
11:00:00 > SELECT * FROM LatestRates;
currency rate
========= ====
US Dollar 102
Euro 116
Yen 1创建时态表
Flink 使用主键约束和事件时间来定义一张版本表和版本视图。
创建版本表举例
在 Flink 中,定义了主键约束和事件时间属性的表就是版本表。
-- 定义一张版本表
CREATE TABLE product_changelog (
product_id STRING,
product_name STRING,
product_price DECIMAL(10, 4),
update_time TIMESTAMP(3) METADATA FROM 'value.source.timestamp' VIRTUAL,
PRIMARY KEY(product_id) NOT ENFORCED, -- (1) 定义主键约束
WATERMARK FOR update_time AS update_time -- (2) 通过 watermark 定义事件时间
) WITH (
'connector' = 'kafka',
'topic' = 'products',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'localhost:9092',
'value.format' = 'debezium-json'
);
行 (1) 为表 product_changelog 定义了主键, 行 (2) 把 update_time 定义为表 product_changelog 的事件时间,因此 product_changelog 是一张版本表。
注意: METADATA FROM 'value.source.timestamp' VIRTUAL 语法的意思是从每条 changelog 中抽取 changelog 对应的数据库表中操作的执行时间,强烈推荐使用数据库表中操作的 执行时间作为事件时间 ,否则通过时间抽取的版本可能和数据库中的版本不匹配。
声明版本视图 #
Flink 也支持定义版本视图只要一个视图包含主键和事件时间便是一个版本视图。
假设我们有表 RatesHistory 如下所示:
-- 定义一张 append-only 表
CREATE TABLE RatesHistory (
currency_time TIMESTAMP(3),
currency STRING,
rate DECIMAL(38, 10),
WATERMARK FOR currency_time AS currency_time -- 定义事件时间
) WITH (
'connector' = 'kafka',
'topic' = 'rates',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json' -- 普通的 append-only 流
)
表 RatesHistory 代表一个兑换日元货币汇率表(日元汇率为1),该表是不断增长的 append-only 表。 例如,欧元 兑换 日元 从 09:00:00 到 10:45:00 的汇率为 114。从 10:45:00 到 11:15:00 的汇率为 116。
SELECT * FROM RatesHistory;
currency_time currency rate
============= ========= ====
09:00:00 US Dollar 102
09:00:00 Euro 114
09:00:00 Yen 1
10:45:00 Euro 116
11:15:00 Euro 119
11:49:00 Pounds 108
为了在 RatesHistory 上定义版本表,Flink 支持通过去重查询定义版本视图, 去重查询可以产出一个有序的 changelog 流,去重查询能够推断主键并保留原始数据流的事件时间属性。
CREATE VIEW versioned_rates AS
SELECT currency, rate, currency_time -- (1) `currency_time` 保留了事件时间
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY currency -- (2) `currency` 是去重 query 的 unique key,可以作为主键
ORDER BY currency_time DESC) AS rowNum
FROM RatesHistory )
WHERE rowNum = 1;
-- 视图 `versioned_rates` 将会产出如下的 changelog:
(changelog kind) currency_time currency rate
================ ============= ========= ====
+(INSERT) 09:00:00 US Dollar 102
+(INSERT) 09:00:00 Euro 114
+(INSERT) 09:00:00 Yen 1
+(UPDATE_AFTER) 10:45:00 Euro 116
+(UPDATE_AFTER) 11:15:00 Euro 119
+(INSERT) 11:49:00 Pounds 108
行 (1) 保留了事件时间作为视图 versioned_rates 的事件时间,行 (2) 使得视图 versioned_rates 有了主键, 因此视图 versioned_rates 是一个版本视图。
视图中的去重 query 会被 Flink 优化并高效地产出 changelog stream, 产出的 changelog 保留了主键约束和事件时间。
如果我们想输出 versioned_rates 表在 11:00:00 对应的版本,表的内容如下所示:
currency_time currency rate
============= ========== ====
09:00:00 US Dollar 102
09:00:00 Yen 1
10:45:00 Euro 116
如果我们想输出 versioned_rates 表在 12:00:00 对应的版本,表的内容如下所示:文章来源:https://www.toymoban.com/news/detail-517875.html
currency_time currency rate
============= ========== ====
09:00:00 US Dollar 102
09:00:00 Yen 1
10:45:00 Euro 119
11:49:00 Pounds 108
声明普通表 #
普通表的声明和 Flink 建表 DDL 一致,参考 create table 页面获取更多如何建表的信息。文章来源地址https://www.toymoban.com/news/detail-517875.html
-- 用 DDL 定义一张 HBase 表,然后我们可以在 SQL 中将其当作一张时态表使用
-- 'currency' 列是 HBase 表中的 rowKey
CREATE TABLE LatestRates (
currency STRING,
fam1 ROW<rate DOUBLE>
) WITH (
'connector' = 'hbase-1.4',
'table-name' = 'rates',
'zookeeper.quorum' = 'localhost:2181'
);到了这里,关于Flink TableAPI Window and Watermarket的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!