多线程安全问题
- 为什么会出现多线程安全问题?
在多线程并发下, 假设有 A,B 两个线程同时操作 count = 0 这个公共变量, 在A线程中count++, 在B线程中count++, 正常来说结果应该是 count = 2, 可是同时在A, B两个线程中拿到 count = 0 , 并且都执行count++赋值, 结果就变成了 count = 1 - 解决办法?
- 原子操作类: AtomicLong, AtomicInteger,
LongAdder(java8以上并发量大的情况下推荐) - 锁:
Lock: ReentrantLock, synchronized
- 原子操作类: AtomicLong, AtomicInteger,
1 Volatile关键字
解决多线程内存不可见问题, 对于一写多读可以解决变量同步问题, 多些则无法解决线程安全问题.
2 CAS + 原子操作类
2.1 CAS是什么?
CAS是英文单词Compare And Swap的缩写,翻译过来就是`比较并替换`。
CAS性能优势分析:
主频 1GHz 的cpu: 2-3纳秒
一次上下文切换耗时2-8微妙
1秒 = 1000毫秒
1毫秒 = 1000微秒
1微秒 = 1000纳秒
2.2 AtomicLong实现
// 创建一个对象
AtomicLong atomicLong = new AtomicLong();
// 递增并获取最新的
long l = atomicLong.incrementAndGet();
public class AtomicLong extends Number implements java.io.Serializable {
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
// 获取一块内存地址的偏移量, 在内存地址的编号
valueOffset = unsafe.objectFieldOffset(AtomicLong.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
// 调用的是以下这个方法
public final long incrementAndGet() {
// 自身, 偏移量, 1L
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}
}
// AtomicLong, 偏移量, 1L
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
// 拿到内存中的最新值
var6 = this.getLongVolatile(var1, var2);
// 计算 var1(AtomicLong)在内存 var2(valueOffset)中的结果 是否等于old(var6)值
// == 返回var6
// !== 赋值var6+var4, 自旋 重新获取var6
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4)); // 这个是调用的c++然后使用汇编进行处理的, C++在多核cpu中也进行了锁处理
return var6;
}
2.3 ABA问题
-
ABA问题是什么?
ABA问题是三种状态,
在第一次获取时对象的属性值为A, 这时被其他线程进行修改成B, 又被修改成A, 在第二次判断比较的时候看到还是A, 所以就进行了计算, 可是实际上已经被修改过了, 在int, 等基础类型中,没有问题, 可是在对象Object中会出现问题.// 创建string类型的CAS对象 static AtomicReference<String> accessString = new AtomicReference<>("A"); public static void main(String[] args) throws InterruptedException { new Thread(()->{ // 是A的话更新成B boolean b1 = accessString.compareAndSet("A", "B"); // 是B的话更新成A boolean b2 = accessString.compareAndSet("B", "A"); System.err.println("ABA问题 = "+(b1&b2)); }).start(); Thread.sleep(1000); new Thread(()->{ boolean b3 = accessString.compareAndSet("A","C"); System.err.println("CAS结果 = " + b3); }).start(); }结果:
ABA问题 = trueCAS结果 = true -
解决方法
使用乐观锁机制, (时间戳, 版本号) + 自旋
// 创建包含记录的对象 static AtomicStampedReference<String> accessStampString = new AtomicStampedReference<>("A", 0); public static void main(String[] args) throws InterruptedException { int stamp = accessStampString.getStamp(); new Thread(()->{ // 是A的话更新成B, 判断时间戳是否是之前的, 是的话+1 boolean b1 = accessStampString.compareAndSet("A", "B", accessStampString.getStamp(), accessStampString.getStamp()+1); // 是B的话更新成A, 判断时间戳是否是之前的, 是的话+1 boolean b2 = accessStampString.compareAndSet("B", "A", accessStampString.getStamp(), accessStampString.getStamp()+1); System.err.println("ABA问题 = "+(b1&b2)); }).start(); Thread.sleep(1000); new Thread(()->{ boolean b3 = accessStampString.compareAndSet("A","C", stamp, stamp+1); System.err.println("CAS结果 = " + b3); }).start(); }结果:
ABA问题 = trueCAS结果 = false
3 AtomicLong 和 LongAdder
AtomicLong(1.8之前) 和 LongAdder(1.8及以后) 都能解决多线程问题, 那么我们用哪个?
- AtomicLong 底层中, 是对一个base对象进行操作, 多线程中, 第一个写入, 第二个第三个写入失败则CAS重试,导致CPU开销高
- LongAdder 底层中, 如果是单线程,则跟AtomicLong没有太大区别, 对base值进行计算, 如果是多线程环境则实行
分片机制, 多线程进行写入时, 默认会创建两个cell进行计算, 每个cell分一些线程进入, 如果线程写入失败, 则创建更多的cell, 最后使用sum() = base + cell[0] + cell[1]+...方法进行计算
在线程数量少的时候, 使用AtomicLong的时间更快, 在线程量多的话, 使用LongAdder更快, 线程数量越多,两个的差别越大

4 ReentrantLock 可重入锁 与 Synchronized
static Lock lock = new ReentrantLock();
int count = 0;
public static void main(String[] args) {
lock.lock(); //加锁
try {
// 业务代码
count++;
}finally {
lock.unlock(); // 释放锁
}
}
4.1 手写MyLock
import org.jetbrains.annotations.NotNull;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicReference;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.LockSupport;
/**
* @author xyy
* @DateTime 2023/7/3 13:20
* @ClassName MyLock
*/
public class MyLock implements Lock {
/**
* 实现CAS比较对象
* 锁的持有者
*/
AtomicReference<Thread> atomicReference = new AtomicReference<>();
/**
* 阻塞队列
*/
LinkedBlockingQueue<Thread> linkedBlockingQueue = new LinkedBlockingQueue<>();
@Override
public void lock() {
// 如果里面是空则成功写入
while (!atomicReference.compareAndSet(null, Thread.currentThread())){
// 有锁被占用, 写入阻塞队列
linkedBlockingQueue.add(Thread.currentThread());
//让当前线程阻塞, 相当于打上断点!!!打断点!!!调试的时候的断点!!!
// 在lock时进行停车阻塞, 在unlock时继续执行这里的代码!!!
LockSupport.park();
// 删除阻塞队列中的本线程, 重新竞争lock, 必须要删除!!!否则容易内存泄漏
linkedBlockingQueue.remove(Thread.currentThread());
}
}
@Override
public void unlock() {
// 只有当前锁的线程才能释放锁(CAS)
if(atomicReference.compareAndSet(Thread.currentThread(), null)){
// 将阻塞队列中的数据进行开放
for (Thread thread : linkedBlockingQueue) {
// unpark方法不一定能唤醒, 所以从这里删除阻塞队列不行
LockSupport.unpark(thread);
}
}
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public boolean tryLock() {
return false;
}
@Override
public boolean tryLock(long time, @NotNull TimeUnit unit) throws InterruptedException {
return false;
}
@NotNull
@Override
public Condition newCondition() {
return null;
}
}
4.2 synchronized
在 jdk1.6之前 synchronized是一把重量级锁, 跟 4.1 一样的,(在线程的上下文切换中非常耗时, 线程A上文记录, 恢复线程B的上文继续执行B的下文)
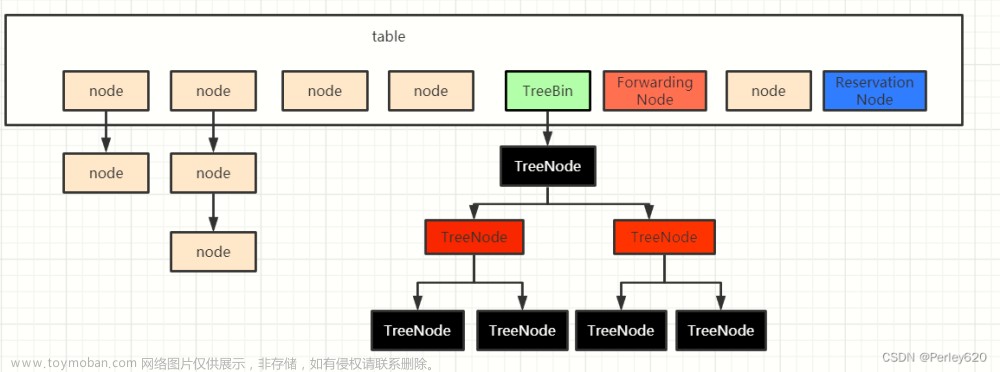
6 ConcurrentHashMap 并发
ConcurrentHashMap 其实底层是初始16个HashMap, 在扩容时乘以2, 保证数组长度是2的幂次方, 减少hash冲突,数组下标计算方式(n-1) & hash, 而2的幂次方-1的二级制数都是1, hash冲突可能性最小.文章来源:https://www.toymoban.com/news/detail-518684.html
在多线程中, put会进行hash计算, 然后加锁写入相应的hashMap中, 因为初始有16个hashmap, 则可以同时处理多线程的问题文章来源地址https://www.toymoban.com/news/detail-518684.html
到了这里,关于CAS + 自旋 锁底层的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![java八股文面试[多线程]——Synchronized的底层实现原理](https://imgs.yssmx.com/Uploads/2024/02/682990-1.png)
![java八股文面试[多线程]——ThreadLocal底层原理和使用场景](https://imgs.yssmx.com/Uploads/2024/02/695582-1.png)



