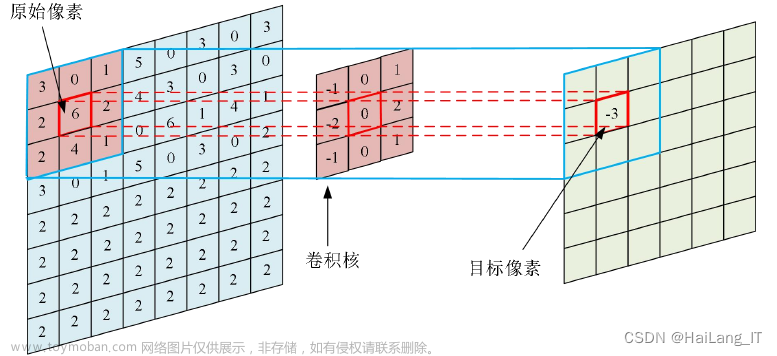
目录
卷积神经网络与全连接神经网络
前向后向传播推导
通用手写体识别模型
人脸识别模型
电影评论情感分析模型
卷积神经网络与全连接神经网络
卷积神经网络(Convolutional Neural Network,CNN)和全连接神经网络(Fully Connected Neural Network,FCN)都是深度学习领域中常见的神经网络模型。下面是二者的比较。
(1)相同点
①都是前馈神经网络模型,由多个神经元构成。
②都可以通过反向传播算法进行训练,优化网络参数以达到最小化损失函数的目的。
③都可以使用多层堆叠的方式来构建深度网络,提高模型的表达能力。
④都可以处理各种类型的数据,如图像、语音、文本、时间序列等。
(2)不同点
①结构不同:
CNN 是由卷积层、池化层和全连接层组成的,其中卷积层和池化层是卷积运算和子采样运算,可以提取出图像中的局部特征。CNN 的结构参数小,具有较强的抗噪声能力。
FCN是由多个全连接层组成的,每个神经元都与上一层的所有神经元相连。这种结构使得全连接网络可以学习到非常复杂的函数映射,但是参数量非常大,容易过拟合。
②权重共享不同:
在FCN中,每个神经元都有独立的权值和偏置。而CNN的卷积层和池化层具有权值共享的特点,这使得模型的参数量大大降低,同时也提高了模型的泛化能力。
③可解释性不同:
FCN是一种黑盒子模型,输入和输出之间的映射关系不可解释,无法获得特征的空间分布情况,难以进行特征可视化。而在CNN中,由于卷积核的权值共享和局部连接性,它们在提取特征时具有一定的可解释性,可以更好地理解特征提取过程。
前向后向传播推导
深度神经网络中的误差逆传播算法(backpropagation,BP算法)是一种用于训练神经网络的反向传播算法。它利用梯度下降法来调整网络参数,使得网络的输出尽可能接近目标输出。
首先,我们需要定义一个损失函数(loss function)。在训练过程中,我们需要将该损失函数最小化,以使网络输出和目标输出的差异最小化。一般情况下,我们会使用均方误差(MSE)或交叉熵(Cross-Entropy)作为损失函数。
接着,利用前向传播算法计算网络的输出值。前向传播算法是指输入数据从输入层到输出层的正向传播过程,整个过程中的每一个神经元都会进行一次乘加运算。
然后,我们需要根据输出误差对每个参数进行更新。这里使用反向传播算法来计算参数的梯度,从而实现参数更新。反向传播算法的核心思想是将误差从输出层一直传递到输入层,并根据每个参数的贡献程度来分配误差值。具体来说,误差的传递由两部分组成:前向传播和反向传播。
在前向传播时,我们通过正向计算来得到输出值;在反向传播时,我们先计算输出误差,再将误差反向传递,并根据每个参数的贡献程度来分配误差值。最后,我们可以使用梯度下降法来调整网络参数,使得网络的输出尽可能接近目标输出。
(1)前向传播

(2)后向传播

通用手写体识别模型
使用的数据集为MNIST手写数字识别数据集,包含了0到9这10个数字的灰度图片,一共有 60,000 张训练图片和 10,000 张测试图片,每张图片的大小为 28 x 28 像素。
我们用一个3×3的卷积层来提取图像的特征,激活函数为ReLU函数,接着用一个2×2的最大池化层降低采样,减少参数数量,最后添加一个全连接层,激活函数为softmax函数,给予10个输出神经元,表示0到9的数字分类。
使用了1个卷积核,训练了5轮,训练过程如图7所示。

图7手写体MNIST训练过程
训练出的手写体识别模型在测试集上的识别率和损失随训练的轮次的变化如图8所示。

图8 手写体MNIST识别率
具体数据如表4所示。

表4 手写体MNIST
由结果可以看出,训练出来的手写体识别模型,其拟合效果和泛化效果都比较好。
具体代码实现请看: Keras-深度学习-神经网络-手写数字识别模型_一片叶子在深大的博客-CSDN博客
人脸识别模型
我们首先通过python的PIL库读取图片数据,将所有图片数据存储在numpy数组中,将人脸数据处理成一堆张量,并分成训练集和测试集,然后构建出图片的标签张量。
接着构建深度神经网络,这里我们构建的是卷积神经网络,(Convolutional Neural Network, CNN)模型。这个模型包含了一个卷积层、一个池化层、一个全连接层。其中卷积层用来提取图片中的特征,池化层用来降低数据量,全连接层实现了分类任务。这里我们使用的是3X3的卷积层,激活函数使用的ReLU激活函数,还有2X2的最大池化层,全连接层的激活函数为softmax激活函数。
以下是python构建的卷积神经网络在ORL、FERET和YaleFace三个人脸数据集的训练和表现情况。
- ORL人脸数据集
ORL人脸数据集有40个人的人脸数据,每个人10张照片,一共400张照片,照片的维数是46×56。我们将每个人的前5张照片作为训练集,共200张,剩下的5张作为测试集,最后的全连接层采用40个神经元作为模型的输出,使用了64个卷积核,训练了20轮,训练过程如图1所示。

图1 ORL训练过程
训练出的人脸识别模型在测试集上的识别率随训练的轮次的变化如图2所示。

图2 ORL识别率
具体数据如表1所示。

表1 ORL
由结果可以看出,ORL数据集训练出来的模型,其拟合效果和泛化效果都比较好。
- FERET人脸数据集
FERET人脸数据集有200个人的人脸数据,每个人7张照片,一共1400张照片,照片的维数是80×80。我们将每个人的前4张照片作为训练集,共800张,剩下的3张作为测试集,最后的全连接层采用200个神经元作为模型的输出,使用了4个卷积核,训练了20轮,训练过程如图3所示。

图3 FERET训练过程
训练出的人脸识别模型在测试集上的识别率随训练的轮次的变化如图4所示。

图4 FERET识别率
具体数据如表2所示。

表2 FERET
由结果可以知道,FERET数据集训练出来的模型,其拟合效果很好,但泛化效果并不理想,分析原因可能是因为训练的数据过少,加上FERET的噪声影响比较大,最后一张照片光线很暗,导致了测试集的识别率不高。
- Yale Face人脸数据集
Yale Face人脸数据集有15个人的人脸数据,每个人11张照片,一共165张照片,照片的维数是80×100。我们将每个人的前6张照片作为训练集,共90张,剩下的5张作为测试集,最后的全连接层采用15个神经元作为模型的输出,使用了16个卷积核,训练了20轮,训练过程如图5所示。

图5 Yale Face训练过程
训练出的人脸识别模型在测试集上的识别率随训练的轮次的变化如图6所示。

图6 Yale Face识别率
具体数据如表3所示。

表3 Yale Face
由结果可以看出,Yale Face数据集训练出来的模型,其拟合效果和泛化效果都比较好。
具体代码实现请看: Keras-深度学习-神经网络-人脸识别模型_一片叶子在深大的博客-CSDN博客
电影评论情感分析模型
使用到的数据集为IMDB电影评论情感分类数据集,该数据集包含 50,000 条电影评论,其中 25,000 条用于训练,25,000 条用于测试。每条评论被标记为正面或负面情感,因此该数据集是一个二分类问题。
我们构建一个包含嵌入层、全局平均池化层和输出层的神经网络,输入数据是一组英文电影评论,输出结果是二分类标签,即正面评价或负面评价。
其中,嵌入层将单词索引序列编码为连续的实数向量表示;全局平均池化层将这些向量取平均值去除位置信息,并将其映射到固定长度的向量中;输出层则使用 sigmoid 激活函数进行二分类预测。使用 Adam 优化器和二元交叉熵损失函数进行模型训练,并以准确率作为评估指标,共训练10轮,训练过程如图9所示。

图9 IMDB电影评论情感分析训练过程
训练出的电影评论情感分析模型在测试集上的准确率和损失随训练的轮次的变化如图10所示。

图10情感分析 准确率
具体数据如表5所示。

表5 情感分析
由结果可以知道,我们训练出来的电影评论情感分析模型,其数据的拟合效果和测试的泛化效果都比较理想。文章来源:https://www.toymoban.com/news/detail-518688.html
具体代码实现请看:Keras-深度学习-神经网络-电影评论情感分析模型_一片叶子在深大的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-518688.html
到了这里,关于机器学习之深度神经网络的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!