以下内容来自对《从前端到全栈》一书的学习记录~
学习的时候用的是
V16.20.0,18+之后的语法差别还是有的~
请求优化
我们在请求资源的时候,是需要做优化的,这里的优化涉及到了缓存。浏览器的缓存策略有两种:
- 强缓存
- 协商缓存
关于两者的区别可以看看之前的那篇《【HTTP】04_进阶》关于缓存的理解~
首先是强缓存的实现:
修改index.html,在里面引入我们的图片:
<body>
<h1>Hello World</h1>
<img src="./1.jpg" />
</body>
res.writeHead(200, {
'Content-Type': mime.getType(ext),
'Cache-Control': 'max-age=86400', // 缓存一天
});

再次访问:

index.html 页面是直接通过浏览器地址栏访问的。根据浏览器的标准,通过地址栏访问、以及强制刷新网页的时候,HTTP 请求头自动会带上Cache-Control: no-cache和Pragma: no-cache的信息。只要有这两个请求头之一,浏览器就会忽略响应头中的Cache-Control字段。
强缓存有个弊端就是,在未过期前更新静态资源(如果图片、css等文件,读取的还是旧文件)你可以在文件夹中修改图片,刷新页面发现还是旧图~
只有强制刷新(ctrl+F5)才能更新旧图,所以一般强缓存适用于不需要修改的资源,协商缓存用的比较多~
下面是协商缓存的实现:
const timeStamp = req.headers['if-modified-since'];
let status = 200;
// stats.mtimeMs表示文件的修改时间
if(timeStamp && Number(timeStamp) === stats.mtimeMs) {
// 如果timeStamp和stats.mtimeMS相等,说明文件内容没有修改,返回响应状态码 304
status = 304;
}
res.writeHead(status, {
'Content-Type': mime.getType(ext),
'Last-Modified': stats.mtimeMs, // 协商缓存响应头
});
if(status === 200) {
const fileStream = fs.createReadStream(filePath);
fileStream.pipe(res);
} else {
res.end(); // 如果状态码不是200,不用返回Body
}

协商缓存不止Last-Modified一种,还有一种协商缓存是Etag,它的机制和Last-Modified大同小异,只是把Last-Modified的时间戳换成Etag签名,相应地把If-Modified-Since字段换成If-None-Match字段。Etag的值可以用资源文件的 MD5 或 sha 签名。
协商缓存为什么要有两种呢?因为,有时候我们的网站是分布式部署在多台服务器上,一个资源文件可能在每台服务器上都有副本,相应地资源文件被修改时候,新的文件要同步到各个服务器上,导致各个文件副本的修改时间不一定相同。那么当用户一次访问请求的服务器和另一次访问请求的服务器不同时,就有可能因为两个文件副本的修改时间不同而使得
Last-Modified形式的协商缓存失效(还有可能是因为两次修改文件的间隙可以忽略不记,所以时间没有改变)。如果这种情况采用Etag形式的协商缓存,根据文件内容而不是修改时间来判断缓存,就不会有这个问题了。
如果浏览器被用户强制刷新,那么强缓存和协商缓存都会失效。因为强制刷新会带上
Cache-Control: no-cache和Pragma: no-cache请求头且不会带上If-Modified-Scene和If-None-Match请求头。
文件压缩
浏览器支持 gzip、deflate 和 br 这三种压缩算法,使用它们压缩文件,能够大大节省传输带宽,提升请求的响应速度,减少页面访问的延迟。
我们需要根据客户端的Accept-Encoding请求头字段实现多种压缩算法:
npm i zlib --save
import http from 'http';
import { fileURLToPath } from 'url';
import { dirname, resolve, join, parse } from 'path';
import fs from 'fs';
import mime from 'mime';
import zlib from 'zlib';
const __dirname = dirname(fileURLToPath(import.meta.url));
const server = http.createServer((req, res) => {
// 将想要获取的文件路径格式化一下,转成绝对路径
let filePath = resolve(__dirname, join('www', `${req.url}`));
// 判断文件是否存在
if(fs.existsSync(filePath)) {
// 判断是否是文件目录
const stats = fs.statSync(filePath);
const isDir = stats.isDirectory();
if(isDir) {
// 如果是目录,则访问的是index.html
filePath = join(filePath, 'index.html');
}
// 获取文件后缀
const { ext } = parse(filePath);
const timeStamp = req.headers['if-modified-since'];
let status = 200;
// stats.mtimeMs表示文件的修改时间
if(timeStamp && Number(timeStamp) === stats.mtimeMs) {
// 如果timeStamp和stats.mtimeMS相等,说明文件内容没有修改,返回响应状态码 304
status = 304;
}
// 获取文件后缀
const mimeType = mime.getType(ext);
// 这里同时采用了两者缓存策略
const responseHeaders = {
'Content-Type': mimeType,
'Cache-Control': 'max-age=86400', // 缓存一天
'Last-Modified': stats.mtimeMs,
};
// 获取请求头
const acceptEncoding = req.headers['accept-encoding'];
// 判断是哪种压缩算法
const compress = acceptEncoding && /^(text|application)\//.test(mimeType);
if(compress) {
// 判断客户端是否支持 gzip、deflate、或者 br 中的一种压缩算法
acceptEncoding.split(/\s*,\s*/).some((encoding) => {
if(encoding === 'gzip') {
responseHeaders['Content-Encoding'] = 'gzip';
return true;
}
if(encoding === 'deflate') {
responseHeaders['Content-Encoding'] = 'deflate';
return true;
}
if(encoding === 'br') {
responseHeaders['Content-Encoding'] = 'br';
return true;
}
return false;
});
}
const compressionEncoding = responseHeaders['Content-Encoding']; // 获取选中的压缩方式
// 设置响应头
res.writeHead(status, responseHeaders);
if(status === 200) {
const fileStream = fs.createReadStream(filePath);
if(compress && compressionEncoding) {
let comp;
// 使用指定的压缩方式压缩文件
if(compressionEncoding === 'gzip') {
comp = zlib.createGzip();
} else if(compressionEncoding === 'deflate') {
comp = zlib.createDeflate();
} else {
comp = zlib.createBrotliCompress();
}
fileStream.pipe(comp).pipe(res);
} else {
fileStream.pipe(res);
}
} else {
res.end();
}
}else {
res.writeHead(404, {'Content-Type': 'text/html'});
res.end('<h1>Not Found</h1>');
}
});
server.on('clientError', (err, socket) => {
socket.end('HTTP/1.1 400 Bad Request\r\n\r\n');
});
server.listen(8080, () => {
console.log('opened server on', server.address());
});

拦截器
之前学习koa的时候会接触到一个概念:洋葱模型,当我们访问一个路由的时候,会层层进入洋葱,每一层都会做一些处理,然后再一层层出来:

这里的拦截器,就跟上面的作用差不多~
// lib/interceptor.js
class Interceptor {
constructor() {
// 存储中间件函数
this.aspects = [];
}
use(functor) {
// 注册中间件函数
this.aspects.push(functor);
return this;
}
async run(context) {
const aspects = this.aspects;
// 执行中间函数,执行规则跟洋葱模型一样~
const proc = aspects.reduceRight(function (a, b) { // eslint-disable-line
return async () => {
await b(context, a);
};
}, () => Promise.resolve());
try {
await proc();
} catch (ex) {
console.error(ex.message);
}
return context;
}
}
module.exports = Interceptor;
封装一下Http服务器,使用拦截器:
// lib/server.js
import http from 'http';
import Interceptor from './interceptor.js';
class Server{
constructor() {
const interceptor = new Interceptor();
this.server = http.createServer(async (req, res) => {
// 执行注册的拦截函数
await interceptor.run({req, res});
if(!res.writableFinished) {
let body = res.body || '200 OK';
if(body.pipe) {
body.pipe(res);
} else {
if(typeof body !== 'string' && res.getHeader('Content-Type') === 'application/json') {
body = JSON.stringify(body);
}
res.end(body);
}
}
});
this.server.on('clientError', (err, socket) => {
socket.end('HTTP/1.1 400 Bad Request\r\n\r\n');
});
this.interceptor = interceptor;
}
// 监听
listen(opts, cb = () => {}) {
if(typeof opts === 'number') opts = {port: opts};
opts.host = opts.host || 'localhost';
console.log(`Starting up http-server http://${opts.host}:${opts.port}`);
this.server.listen(opts, () => cb(this.server));
}
// 注册中间件
use(aspect) {
return this.interceptor.use(aspect);
}
}
export default Server;
这样我们在index.js中应该这样创建服务器:
import Server from './lib/server.js';
const app = new Server();
app.listen({
port: 9090,
host: '0.0.0.0',
})
先来测试一下拦截器,访问的时候页面返回Hello World~
import Server from './lib/server.js';
const app = new Server();
// 注册中间件
app.use(async ({ res }, next) => {
res.setHeader('Content-Type', 'text/html');
res.body = '<h1>Hello world</h1>';
await next();
})
app.listen(9090)
路由
koa-router这个中间件本质上就是一个拦截器,来实现路由~
// middleware/router.js
import url from 'url';
import path from 'path';
/**
* 利用正则表达式检查真正的路径和路由规则是否匹配
* @param {*} rule 如:/test/:course/:lecture
* @param {*} pathname 如:/test/123/abc
* @returns
*/
function check(rule, pathname) {
// window下需要替换一下
rule = rule.replace(/\\/g, '/');
const paraMatched = rule.match(/:[^/]+/g);
const ruleExp = new RegExp(`^${rule.replace(/:([^/]+)/g, '([^/]+)')}$`);
const ruleMatched = pathname.match(ruleExp);
if(ruleMatched) {
const ret = {};
if(paraMatched) {
for(let i = 0; i < paraMatched.length; i++) {
ret[paraMatched[i].slice(1)] = ruleMatched[i + 1];
}
}
// 最后得到的结果为 ret = {course: 123, lecture: abc}
return ret;
}
return null;
}
function route(method, rule, aspect) {
return async(ctx, next) => {
const req = ctx.req;
if(!ctx.url) ctx.url = url.parse(`http://${req.headers.host}${req.url}`);
const checked = check(rule, ctx.url.pathname);
if(!ctx.route && (method === '*' || req.method === method)
&& !!checked) {
ctx.route = checked;
await aspect(ctx, next);
} else {
await next();
}
}
}
class Router {
constructor(base = '') {
this.baseURL = base;
}
get(rule, aspect) {
return route('GET', path.join(this.baseURL, rule), aspect);
}
post(rule, aspect) {
return route('POST', path.join(this.baseURL, rule), aspect);
}
put(rule, aspect) {
return route('PUT', path.join(this.baseURL, rule), aspect);
}
delete(rule, aspect) {
return route('DELETE', path.join(this.baseURL, rule), aspect);
}
all(rule, aspect) {
return route('*', path.join(this.baseURL, rule), aspect);
}
}
export default Router;
// index.js
import Server from './lib/server.js';
import Router from './middleware/router.js';
const app = new Server();
const router = new Router();
// 请求指定路由
app.use(router.all('/test/:course/:lecture', async ({route, res}, next) => {
res.setHeader('Content-Type', 'application/json');
res.body = route;
await next();
}));
// 默认路由
app.use(router.all('.*', async ({req, res}, next) => {
res.setHeader('Content-Type', 'text/html');
res.body = '<h1>Hello world</h1>';
await next();
}));
app.listen(9090)
获取GET请求参数
常用的格式包括application/x-www-form-urlencoded、multipart/form-data、application/json等。
// aspect/param.js
import url from 'url';
import querystring from 'querystring';
export default async(ctx, next) => {
const { req } = ctx;
const {query} = url.parse(`http://${req.headers.host}${req.url}`);
ctx.params = querystring.parse(query);
console.log(ctx.params);
await next();
}
// index.js
import params from './aspect/param.js'
// ...
app.use(params);
访问http://localhost:9090/?name=test会在控制台打印{ name: 'test' }
使用Mock
后端大佬只给了接口文档,还没开发完接口的时候,我们可以借助Mock照着文档造数据,然后模拟请求~
这里直接使用虚拟数据,新建mock/data.json存放假数据,文件地址:data.json
// module/mock.js
import fs from 'fs';
import path from 'path';
import url from 'url';
let dataCache = null;
function loadData() {
if(!dataCache) {
const __dirname = path.dirname(url.fileURLToPath(import.meta.url));
const file = path.resolve(__dirname, '..', 'mock/data.json');
const data = JSON.parse(fs.readFileSync(file, {encoding: 'utf-8'}));
const reports = data.dailyReports; // 数组格式的数据
dataCache = {};
// 把数组数据转换成以日期为key的JSON格式并缓存起来
reports.forEach((report) => {
dataCache[report.updatedDate] = report;
});
}
return dataCache;
}
// 获取所有有疫情记录的日期
export function getCoronavirusKeyIndex() {
return Object.keys(loadData());
}
// 获取当前日期对应的疫情数据
export function getCoronavirusByDate(date) {
const dailyData = loadData()[date] || {};
if(dailyData.countries) {
// 按照各国确诊人数排序
dailyData.countries.sort((a, b) => {
return b.confirmed - a.confirmed;
});
}
return dailyData;
}
修改index.js:
import Server from './lib/server.js';
import Router from './middleware/router.js';
import params from './aspect/param.js'
import { getCoronavirusKeyIndex, getCoronavirusByDate } from './module/mock.js'
const app = new Server();
const router = new Router();
// 在服务器的控制台上就能知道用户访问了哪个 URL
app.use(({req}, next) => {
console.log(`${req.method} ${req.url}`);
next();
});
// 解析 GET 参数的拦截切面
app.use(params);
// 获取所有有疫情记录的日期
app.use(router.get('/coronavirus/index', async ({route, res}, next) => {
const index = getCoronavirusKeyIndex();
res.setHeader('Content-Type', 'application/json');
res.body = {data: index};
await next();
}));
// 获取当前日期对应的疫情数据
app.use(router.get('/coronavirus/:date', async ({route, res}, next) => {
const data = getCoronavirusByDate(route.date);
res.setHeader('Content-Type', 'application/json');
res.body = {data};
await next();
}));
// 默认路由
app.use(router.all('.*', async ({req, res}, next) => {
res.setHeader('Content-Type', 'text/html');
res.body = '<h1>Hello world</h1>';
await next();
}));
app.listen(9090)
这样我们访问http://localhost:9090/coronavirus/index可以获得日期的 JSON 数据,访问http://localhost:9090/coronavirus/2020-01-22可以获得 2020 年 1 月 22 日当天的疫情 JSON 数据
服务端渲染
对网页渲染速度敏感、依赖 SEO,或是比较简单,都适合使用服务端渲染,服务器将数据在页面上填充完整之后再将页面返回~
这里需要借助目标引擎,该书中使用的handlebars
npm install handlebars --save
新建view/coronavirus_date.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>疫情数据</title>
<style>
td:not(:first-child) {
text-align: right;
}
td:nth-child(3) {
color: red;
}
td:nth-child(4) {
color: green;
}
</style>
</head>
<body>
<table>
<thead>
<tr><th>国家</th><th>确诊</th><th>死亡</th><th>治愈</th></tr>
</thead>
<tbody>
{{#each data.countries ~}}
<tr><td>{{country}}</td><td>{{confirmed}}</td><td>{{recovered}}</td><td>{{deaths}}</td></tr>
{{~/each}}
</tbody>
</table>
</body>
</html>
新建view/coronavirus_index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>疫情目录</title>
</head>
<body>
<ul>
{{#each data ~}}
<li><a href="./{{this}}">{{this}}</a></li>
{{~/each}}
</ul>
</body>
</html>
然后分别修改我们的路由中间件,确保每次请求都是返回渲染好的html:
import { fileURLToPath } from 'url';
import { dirname, resolve, join, parse } from 'path';
import fs from 'fs';
import handlebars from 'handlebars';
// ...
const __dirname = dirname(fileURLToPath(import.meta.url));
// ...
// 获取所有有疫情记录的日期
app.use(router.get('/coronavirus/index', async ({route, res}, next) => {
// 获取文件路径
const filePath = resolve(__dirname, 'view/coronavirus_index.html');
// 获取模板文件
const tpl = fs.readFileSync(filePath, {encoding: 'utf-8'});
// 编译模板
const template = handlebars.compile(tpl);
// 获取数据
const index = getCoronavirusKeyIndex();
// 将数据与模板结合
const result = template({data: index});
res.setHeader('Content-Type', 'text/html');
res.body = result;
await next();
}));
// 获取当前日期对应的疫情数据
app.use(router.get('/coronavirus/:date', async ({route, res}, next) => {
// 获取文件路径
const filePath = resolve(__dirname, 'view/coronavirus_date.html');
// 获取模板文件
const tpl = fs.readFileSync(filePath, {encoding: 'utf-8'});
// 编译模板
const template = handlebars.compile(tpl);
const data = getCoronavirusByDate(route.date);
// 将数据与模板结合
const result = template({data});
res.setHeader('Content-Type', 'text/html');
res.body = result;
await next();
}));
//...
持久化存储
终于到了链接数据库的时候~该书中用的是SQLite (为啥不是MySQL或者MonogoDB啥的… Orz…)
万变不离其宗,MySQL和MonogoDB在Node的使用很早前接触过了,所以这一块笔记就不做了~
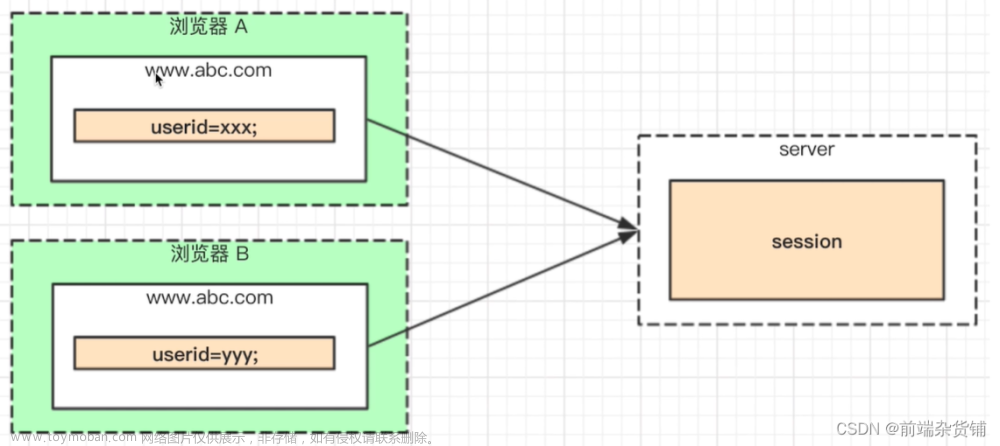
Cookie
在《session和token的登录机制》一文中提到了session的实现原理,就是借助了Cookie。所以Cookie的作用就不写了,直接看看node如何操作Cookie~
在返回的页面中,设置Cookie:
app.use(router.get('/', async ({route, res}, next) => {
res.setHeader('Content-Type', 'text/html;charset=utf-8');
res.setHeader('Set-Cookie', 'mycookie=foobar');
res.body = '<h1>你好!</h1>';
await next();
}));
Cookie是有时效性的,不添加的化,关闭浏览器就会消失,这里给它添加一个过期时间:
res.setHeader('Set-Cookie', `'mycookie=foobar; Max-Age=86400`);
每次浏览器向服务器发送请求的时候,会自动判断这个 Cookie 是否超过了 expires 的时间:如果超时了,则请求中就不带有 Cookie 字段;如果没有超时,则将这个 Cookie 带上。
在这个例子里,由于每次请求时,服务器都会返回一个新的 Max-Age 等于一天的 Cookie,所以只要你每天都访问这个网页,这个 Cookie 就不失效。如果你隔 24 小时再访问这个网页,那这个 Cookie 也就超时失效了。
关于Cookie的规则设置,还有其他类型:
-
Path:表示Cookie只在指定的URL请求中有效;
// 假设现在拦截的路由是/foo/bar
// 正确
res.setHeader('Set-Cookie', `interceptor_js=${id}; Path=/`);
res.setHeader('Set-Cookie', `interceptor_js=${id}; Path=/foo`);
res.setHeader('Set-Cookie', `interceptor_js=${id}; Path=/bar`);
// 错误:因为/abc不在当前请求路径内
res.setHeader('Set-Cookie', `interceptor_js=${id}; Path=/abc`);
-
Domain:表示Cookie在设置的Domain和它的子域名下都有效;
// 若当前域名是study.junyux.com
// 正确
res.setHeader('Set-Cookie', `interceptor_js=${id}; Domain=study.junyux.com`);
res.setHeader('Set-Cookie', `interceptor_js=${id}; Domain=junyux.com`);
// 无效
res.setHeader('Set-Cookie', `interceptor_js=${id}; Domain=dev.study.junyux.com`);
res.setHeader('Set-Cookie', `interceptor_js=${id}; Domain=test.junyux.com`);
-
Secure:表示Cookie只有使用HTTPS/SSL请求时有效; -
SameSite:可以用来限制第三方发来的Cookie;-
Strict表示严格,完全禁止了第三方网站向我们的服务器发送我们网站的 Cookie,缺点就是从第三方跳转到该网站得一直登录; -
Lax只允许第三方网站通过 GET 请求跳转到我们的服务器,并带上我们网站的 Cookie; -
None就表示没有限制。
-
-
HttpOnly:若为true那在页面上,JavaScript无法通过document.cookie获取到该Cookie,这增加了应用的安全性。
Cookie的读取,我们封装成一个文件~
// aspect/cookie.js
export default async(ctx, next) => {
const { req } = ctx;
const cookieStr = decodeURIComponent(req.headers.cookie);
const cookies = cookieStr.split(/\s*;\s*/);
ctx.cookies = {};
cookies.forEach((cookie) => {
const [key, value] = cookie.split('=');
ctx.cookies[key] = value;
});
await next();
}
可以借助Cookie来创建 Session,这个过程一般发生在用户首次登录或者 Session 过期,或者用户需要再次登录时。创建 Session 的流程一般为:
- 用户在客户端提交包含个人信息(如用户名)以及密码的表单;
- 服务器获取客户端发来的
Cookie,如果没有,则创建一个新Cookie; - 利用用户的信息和
Cookie,向Session表新增或更新用户的Session; -
Session创建成功,返回用户信息对象。
Cluster为多进程优化性能
Node.js是单线程非阻塞的,避免了系统分配多线程以及多线程间通信时的开销,高效利用CPU、降低内存的好用。缺点就是无法充分利用现在绝大多数电脑支持的多核 CPU,以及一旦出现错误就会导致服务崩溃。
使用Cluster,可以开启多进程,用主进程管理子进程~
修改lib/server.js,在内部写入多进程的相关代码:
// lib/server.js
import http from 'http';
import cluster from 'cluster';
import os from 'os';
import Interceptor from './interceptor.js';
// 获取cpu数目
const cpuNums = os.cpus().length;
class Server{
constructor(instances = 0, enableCluster = true) {
// 指定启动进程数
this.instances = instances || cpuNums;
// 是否开启多进程
this.enableCluster = enableCluster;
const interceptor = new Interceptor();
this.server = http.createServer(async (req, res) => {
// ...
});
// ...
}
// 监听
listen(opts, cb = () => {}) {
if(typeof opts === 'number') opts = {port: opts};
opts.host = opts.host || 'localhost';
const instances = this.instances;
// 如果是主进程,创建instance个子进程
if(this.enableCluster && cluster.isMaster) {
for(let i = 0; i < instances; i++) {
cluster.fork();
}
// 主进程监听exit事件,如果发现有某个子进程停止了,那么重新创建一个子进程
cluster.on('exit', (worker, code, signal) => {
console.log('worker %d died (%s). restarting...',
worker.process.pid, signal || code);
cluster.fork();
});
}else {
// 如果是子进程
// 由于 Cluster 做了处理,监听是由主进程进行,再由主进程将 HTTP 请求分发给每个子进程,
// 所以子进程尽管监听端口相同,也并不会造成端口冲突
this.worker = cluster.worker;
console.log(`Starting up http-server http://${opts.host}:${opts.port}`);
this.server.listen(opts, () => cb(this.server));
}
}
// ...
}
export default Server;
这时候再次执行index.js的话,会默认采用cup的个数开启N个进程~然后,我们开启两个浏览器窗口分别访问localhost:9090。这里我们可以看到,Cluster 将请求分配到了不同的进程去处理。
Starting up http-server http://localhost:9090
Starting up http-server http://localhost:9090
Starting up http-server http://localhost:9090
Starting up http-server http://localhost:9090
Starting up http-server http://localhost:9090
Starting up http-server http://localhost:9090
接下来要解决的是不同进程间的通讯。
和线程不同,进程是彼此独立的,它们之间并不能通过共享同样的内存而共享数据。
Node.js 提供的process.send方法允许我们在进程间传递消息:
// index.js
// 统计访问次数
app.use(async (ctx, next) => {
process.send('count');
await next();
});
这样我们每次访问http://localhost:9090/都会向进程发送一次消息~
worker.on('message', callback)可以让子进程监听接收到的消息。这样,我们就可以在主进程中监听子进程发送的消息。做法就是在lib/server.js的主进程中,遍历cluster.workers,让每个子进程调用worker.on('message', callback)监听消息。
if(this.enableCluster && cluster.isMaster) {
// ...
Object.entries(cluster.workers).forEach(([id, worker]) => {
worker.on('message', (msg) => {
// TODO
})
})
// ...
}
实时热更新服务器
在多进程模型中,我们可以在主进程监听JS文件变化,如果JS文件发生改变,那么可以结束之前的子进程,在开发模式下热更新服务器。
// lib/server.js
import http from 'http';
import cluster from 'cluster';
import os from 'os';
import fs from 'fs';
import Interceptor from './interceptor.js';
// 获取cpu数目
const cpuNums = os.cpus().length;
class Server{
constructor({ instances = 0, enableCluster = true, mode='production' } = {}) {
// 新增mode,可以取值为development或者production
if(mode === 'development') {
instances = 1;
enableCluster = true;
}
// ...
}
// 监听
listen(opts, cb = () => {}) {
// ...
// 在开发模式下监听文件变化,如果变化直接杀死所有子进程并按顺序重新创建一个
// 如果是生成模式,则不变,发现有某个子进程停止了,那么重新创建一个子进程
if(this.mode === 'development') {
fs.watch('.', { recursive: true }, (eventType) => {
Object.entries(cluster.workers).forEach(([id, worker]) => {
console.log('kill worker %d', id);
worker.kill();
});
cluster.fork();
})
} else {
// 主进程监听exit事件,如果发现有某个子进程停止了,那么重新创建一个子进程
cluster.on('exit', (worker, code, signal) => {
console.log('worker %d died (%s). restarting...',
worker.process.pid, signal || code);
cluster.fork();
});
}
}else {
// 如果是子进程
// 由于 Cluster 做了处理,监听是由主进程进行,再由主进程将 HTTP 请求分发给每个子进程,
// 所以子进程尽管监听端口相同,也并不会造成端口冲突
this.worker = cluster.worker;
console.log(`Starting up http-server http://${opts.host}:${opts.port}`);
this.server.listen(opts, () => cb(this.server));
}
}
// ...
}
export default Server;
总结
学习了搭建HTTP服务之后中间件的开发、性能的优化、常见的Cookie、数据库、多进程的操作~
参考链接
从前端到全栈文章来源:https://www.toymoban.com/news/detail-518707.html
如果错误欢迎指出,感谢阅读~文章来源地址https://www.toymoban.com/news/detail-518707.html
到了这里,关于Node.js知识梳理(二)——进阶的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!