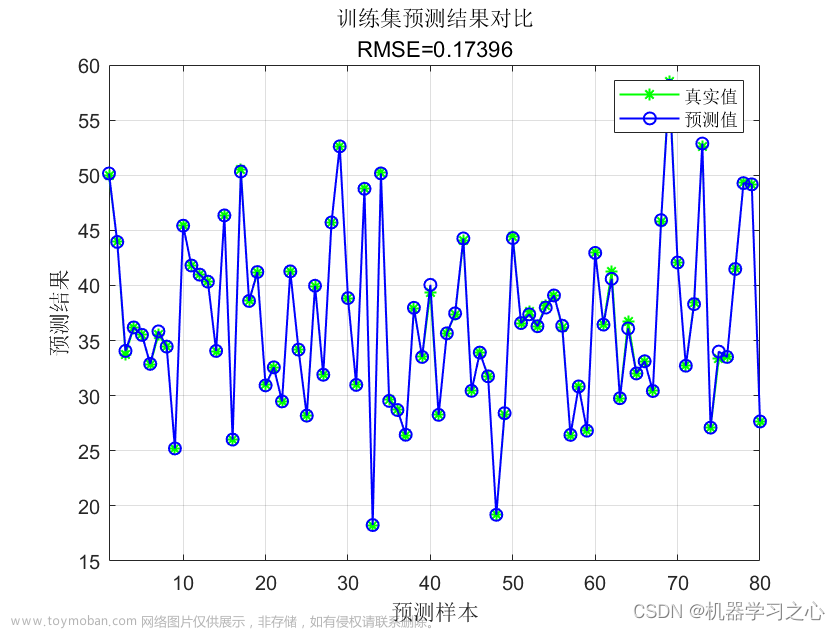
贝叶斯优化(Bayesian Optimization)是一种用于黑盒函数优化的序列模型优化方法。它在较少的函数评估次数下,尝试寻找全局最优解。
贝叶斯优化使用高斯过程(Gaussian Process)作为先验模型来建模未知的目标函数。通过对目标函数进行一系列评估和建模迭代,贝叶斯优化能够根据当前模型的置信度,选择下一个最有希望改善性能的输入点进行评估。这一过程称为采样策略(Sampling Strategy)或引导策略(Acquisition Function),常见的策略包括期望改进(Expected Improvement)、置信界限(Upper Confidence Bound)等。
贝叶斯优化算法通常由以下几个步骤组.:
- 定义待优化的目标函数。
- 选择高(Gaussian Process)作为目标函数的先验模型。
- 根据先验模型,确定下一个要评估的输入点(采样策略)。
- 在选择的输入点处评估目标函数,获取对应的输出值。
- 使用输入和输出数据更新高斯过程模型。
- 重复步骤3-5,直到达到预定义的停止条件(例如达到最大迭代次数或超时)。
- 输出在整个优过程中获得的最佳参数和相应的目标函数值。
贝叶斯优化算法具有一定的优势,尤其适用于高开销的黑盒函数优化(例如机器学习模型调参)。它能够根据已有数据和模型构建的置信度选择下一个采样点,从而实现高效且准确的全局优化。然而,该方法在大规模问题上可能会面临挑战,因为高斯过程的计算和更新复杂度较高。
在Python中,可以用scikit-optimize(skopt)、hyperopt等这些库来执行贝叶斯优化,并为用户提供了方便的接口来定义待优化的目标函数、设置参数空间、选择采样策略等。
支持向量机(Support Vector Machine,SVM)是一种强大的监督学习算法,主要用于二分类和多分类问题。SVM的目标是寻找一个最优超平面或者决策边界,能够将不同类别的样本点有效地分开。
SVM的基本原理是通过构建一个超平面,在特征空间中对样本进行划分。在二维平面上,这个超平面就是一条直线,可以将两类样本分隔开。在更高维度的空间中,超平面可以是一个超平面或者曲面,用于将样本进行分割。
SVM通过选择一个最大间隔超平面来实现最佳分类决策边界。最大间隔超平面是指离最近训练样本最远的样本点之间的距离最大这些样本点通常被称为支持向量。其优点是对噪声数据具有强大的鲁棒性,并且可以处理高维数据。此外,通过使用核函数,SVM还可以处理非线性分类问题,如将数据映射到高维特征空间进行分类。
SVM算法的步骤包括:
- 收集数据:收集包含已知类别标签的训练样本。
- 特征选择与预处理:选择合适的特征,并进行数据预处理,如根据任务需求,将问题定义为二分类或多分类。
- 构建模型:使用训练样本集构建SVM模型,选择合适的核函数和参数。
- 模型训练:优化SVM模型的目标函数,找到最佳超平面或决策边界。
- 预测与评估:对测试样本进行预测,并评估模型的性能指标,如准确率、精确率、召回率等。
SVM优化的目标是最大化间隔,但这个问题可以被表示为一个凸优化问题,其中包含约束和拉格朗日乘子。通过解这个凸优化问题,可以得到最优的分离超平面。
在实践中,可以使用各种库来实现SVM算法(例如scikit-learn)。SVM算法可应用于广泛的领域,包括文本分类、图像识别、生物医学等。但在使用SVM算法时,需要谨慎选择核函数和调整超参数,以获得最佳性能和泛化能力。
支持向量机回归(Support Vector Machine Regression,SVM Regression)是一种用于解决回归问题的算法。与传统回归算法不同,SVM回归的目标是找到一个拟合曲线,使得样本数据点尽可能地落在这条曲线的边界内。
SVM回归算法的基本思想与SVM分类相似,但其用于回归问题时的目标是最小化预测值与实际观测值之间的差距。SVM回归使用支持向量来定义一个"边界带",其中包含了一部分样本点。这个边界带的宽度由模型参数控制,并且旨在容纳尽可能多的观测值SVM回归寻求在尽可能遵循大多数样本趋势同时,保持较小的预测误差。
SVM回归算法的步骤如下:
- 收集数据:收集包含输入特征和对应输出标签的训练样本。
- 特征选择与预处理:选择适当的特征,并进行必要的数据预处理,如归一化或标准化。
- 构建模型:使用训练样本集构建SVM回归模型,并选择合适的核函数和参数。
- 模型训练:优化SVM回归模型的目测与评估:对测试样本进行预测,并评估模型的性能指标,如均方误差、决定系数等。
SVM回归算法可通过支持向量机中的不同核函数(线性、多项式、径向基函数等)来适应不同类型的数据集。通过调整模型的超参数,例如惩罚参数C和核函数的参数,可以改变模的灵活性和拟合能力。
SVM回归算法在许多领域中具有广泛的应用,例如金融预测、销售预测、风险分析等。然而,与任何机器学习算法一样,选择适当的模型参数和核函数以及正确处理数据是确保SVM回归算法成功的关键要素。
文章来源:https://www.toymoban.com/news/detail-518907.html
数据集采用第三方数据集,可以替换成自己的数据集,如用excel等,具体操作在前几期的博客中有相应介绍,欢迎查看。文章来源地址https://www.toymoban.com/news/detail-518907.html
import numpy as np
from sklearn.datasets import load_iris
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from hyperopt import fmin, tpe, hp
# 加载鸢尾花数据集
data = load_iris()
X = data.data
y = data.target
# 定义超参数搜索空间
space = {
'C': hp.loguniform('C', np.log(0.1), np.log(10)),
'gamma': hp.loguniform('gamma', np.log(1e-6), np.log(1e+1))
}
# 定义目标函数
def objective(params):
svm = SVC(C=params['C'], gamma=params['gamma'])
accuracy = np.mean(cross_val_score(svm, X, y, cv=5))
return -accuracy # 目标是最大化准确率,因此取其相反数
# 运行贝叶斯优化算法
best = fmin(objective, space, algo=tpe.suggest, max_evals=50)
# 输出最佳参数值和最佳准确率
best_params = {'C': best['C'], 'gamma': best['gamma']}
best_accuracy = -objective(best)
print("最佳参数:", best_params)
print("最佳准确率:", best_accuracy)
到了这里,关于【python】Bayesian Optimization(贝叶斯优化)优化svm回归问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!