Transformer
1. Transformer的结构
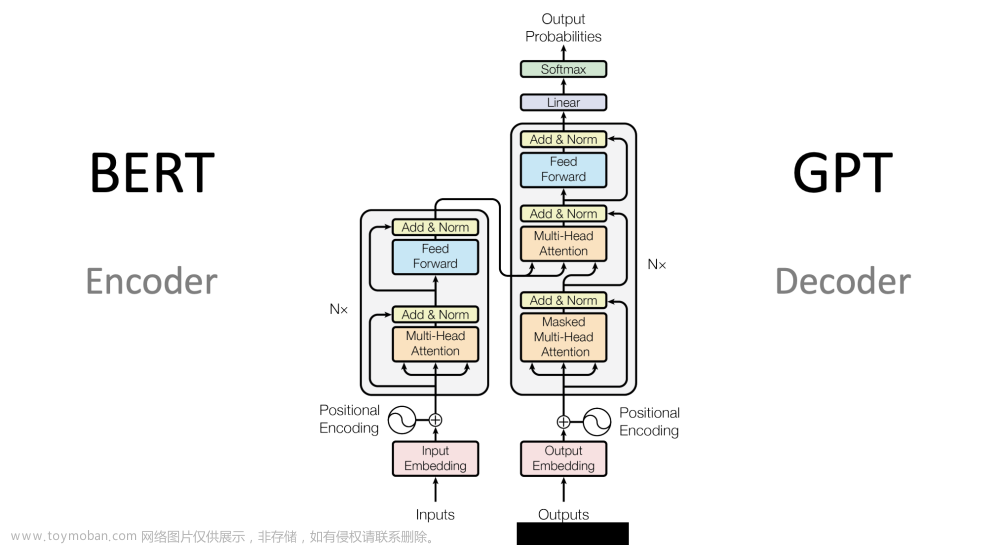
先看 Transformer 的整体框架:
可能看起来很复杂,但其实还是 Encoder 和 Decoder {seq2seq}的框架。默认NX=6 ,6层 Encoder 和 6层 Decoder 嵌套中嵌套了上次讲的 Self-Attention ,再进行多次非线性变换。

上图的框架很复杂,由于 Transformer 最初是作为翻译模型,我们举例先带大家理解用途。

Transformer 相当于一个黑箱,左边输入 “Je suis etudiant”,右边会得到一个翻译结果 “I am a student”。

我们穿插描述下 Encoder-Decoder 框架的模型是如何进行文本翻译的:

Transformer 也是一个 Seq2Seq 模型(Encoder-Decoder 框架的模型),左边一个 Encoders 把输入读进去,右边一个 Decoders 得到输出,Encodes 和 Decoders 默认是有 6 层的,如下图所示:
从上图可以看到,Encoders 的输出,会和每一层的 Decoder 进行结合原因是: Encoder 向每层的 Decoder 输入 KV ,Decoder 产生的Q 从Encoder KV 里 查询信息(下文会讲)
我们取其中一层展示:
2. Seq2seq 从 RNN 到 transformer (举例理解)
例 1:Seq2seq——语音识别,机器翻译

例 2:Seq2seq——输入电视剧的 音频与字幕, 训练一个语音识别模型

例 3:Seq2seq——输入文本,输出语音

例 4:Seq2seq——输入对话模版,训练聊天机器人

例 4:Seq2seq——图像特征提取

例 4:Seq2seq——Transformer

3. Encoder
Encoder 编码器在干嘛?
词向量、图片向量,总而言之,编码器就是通过 词向量 让计算机能够更合理地(不确定性的)认识人类世界客观存在的一些东西。
Encoder 从而言之一句话,变换出更优秀的词向量(K、V)!

有了上述那么多知识的铺垫,我们知道 Eecoders 是 N=6 层,通过上图我们可以看到每层 Encoder 包括两个 sub-layers:
- 第一个 sub-layer 是 multi-head self-attention,用来计算输入的 self-attention;
- 第二个 sub-layer 是简单的前馈神经网络层 Feed Forward;
- 注意:在每个 sub-layer 我们都模拟了残差网络(下文细讲),每个sub-layer的输出都是 LayerNorm (x + Sub_layer(x)),其中 sub_layer 表示的是该层的上一层的输出;
现在我们一步步剖析 Encoder 的数据流示意图:


- 深绿色的 x1 表示 Embedding 层的输出,加上 Positional Embedding 的向量后,得到最后输入 Encoder 中的特征向量,也就是 浅绿色向量 x1;
- 浅绿色向量 x1 表示单词 “Thinking” 的特征向量,其中 x1 经过 Self-Attention 层,变成浅粉色向量 z1;
- x1 作为残差结构的直连向量,直接和 z1 相加,即【w3(w2(w1x+b1)+b2)+b3+x】,然后进行 Layer Norm 操作,得到粉色向量 z1;
- 残差结构的作用:避免出现梯度消失的情况,w3(w2(w1x+b1)+b2)+b3,如果 w1,w2,w3 特别小,0.0000000……1,x 趋近于0,
- Layer Norm的作用 :为了保证数据特征分布的稳定性,并且可以加速模型的收敛
- z1 经过前馈神经网络(Feed Forward)层,再经过残差结构与自身相加,之后又经过 Layer Norm 层,得到一个输出向量 r1;该前馈神经网络包括两个线性变换和一个ReLU激活函数: FFN(x) = max(0, xW1 + b1)W2 + b2 ;
- 前馈神经网络(Feed Forward) 的作用:前面每一步都在做线性变换,wx+b,线性变化的叠加永远都是线性变化(线性变化就是空间中平移和扩大缩小),通过 Feed Forward中的 Relu 做一次非线性变换,这样的空间变换可以无限拟合任何一种状态了
- 由于Transformer 的 Encoders 具有 6 个 Encoder,r1 也将会作为下一层 Encoder 的输入,代替 x1 的角色,如此循环,直至最后一层 Encoder;
听不懂没关系,上面所有操作都是在做词向量,只不过这个词向量更加优秀,更能够精准的表示这个单词、这句话(source)
4. Decoder
Decoder 解码器会接收编码器生成的词向量(K、V),然后通过这个 “词向量” 去生成翻译的结果。


Decoders 也是 N=6 层,通过上图我们可以看到每层 Decoder 包括 3 个 sub-layers:
- 第一个 sub-layer 是 Masked multi-head self-attention,也是计算输入的 self-attention;
- 这里先不解释为什么要做 Masked,在 “Transformer 动态流程展示” 这一小节会解释。
- 第二个 sub-layer 是 Encoder-Decoder Attention 计算,对 Encoder 的输入和 Decoder的Masked multi-head self-attention 的输出进行 attention 计算;
- 这里也不解释为什么要对 Encoder 和 Decoder 的输出一同做 Cross attention 计算,在 “Transformer 动态流程展示” 这一小节会解释
- 第三个 sub-layer 是前馈神经网络层,与 Encoder 相同;
Decoder 的输入:

Decoder 把自己的前一个时间点的输出(即,查询向量 Q)又与 Encode 输出的特征向量(K、V)点积成为新的输入;
即 Encoder 提供了 Ke、Ve 矩阵,Decoder 提供了 Qd 矩阵;
为什么 Encoder 给予 Decoders 的是 K、V 矩阵?
- Q 来源 Decoder (解码器),K=V 来源于 Encoder (编码器);
- Q 是查询变量,Q 是已经生成的词; K=V 是源语句
- 当我们生成这个词的时候,通过 Decoder 已经生成的词作为 Q 和源语句提供的 K、V
做Self-Attention,就是确定源语句中哪些词对接下来的词的生成更有作用,进而生成下个词继续作为Q。
举个例子:“我爱中国” 翻译为 “I love China”
当我们翻译 “I” 的时候,由于 Decoder 提供了 Q矩阵,通过与 Ke、Ve 矩阵的计算,它可以在 “我爱中国”这四个字中找到对 “I” 翻译最有用的单词是哪几个,并以此为依据翻译出 “I” 这个单词,这就很好的体现了注意力机制想要达到的目的,把焦点放在对自己而言更为重要的信息上。
5. Transformer 输出结果
以上讲完了 Transformer 编码和解码两大模块,那么我们回归最初的问题,将 “机器学习” 翻译成 “machine learing”,解码器的输出是一个浮点型的向量,怎么转化成 “machine learing” 这两个词呢?让我们来看看 Encoders 和 Decoders 交互的过程寻找答案:

从上图可以看出,Transformer 最后的工作是让解码器的输出通过线性层 Linear 后接上一个 softmax
- 其中线性层是一个简单的全连接神经网络,它将解码器产生的向量 A 投影到一个更高维度的向量 B 上,假设我们模型的词汇表是10000个词,那么向量 B 就有10000个维度,每个维度对应一个惟一的词的得分。
- 然后 softmax 层将这些分数转换为概率。选择概率最大的维度,并对应地生成与之关联的单词作为此时间步的输出就是最终的输出啦!
6. Transformer 动态流程演示

假设上图是训练模型的某一个阶段,我们来结合 Transformer 的完整框架描述下这个动态的流程图:
现在我们来解释为什么 Decoder 需要做 Mask:
答案: 为了解决训练阶段和测试阶段的 gap(不匹配)
举例1:机器翻译: 源语句(我爱中国),目标语句(I love China)
- 训练阶段:解码器会有输入,这个输入是目标语句,就是 I love China,通过已经生成的词,去让解码器更好的生成(每一次都会把所有信息告诉解码器)
- work阶段:解码器也会有输入,但是此时,测试的时候是不知道目标语句是什么的,这个时候,你每生成一个词,就会有多一个词放入目标语句中,每次生成的时候,都是已经生成的词(测试阶段只会把已经生成的词告诉解码器)
为了匹配,为了解决这个 gap,masked Self-Attention 就登场了,我在训练阶段,我就做一个 masked,当你生成第一个词,我啥也不告诉你,当你生成第二个词,我告诉第一个词

举例2:
输出的答案和正确答案的交叉熵越小越好:

但又有一个问题:
训练的时候有正确答案,work的时候没有正确答案。测试的时 Decoder 接收的是自己的输出,可能有错误的;训练时,Decoder接收的是完全正确的; 测试和训练不一致的现象叫 “exposure bias”。
假设 Decoder 在训练时看到的都是正确的信息,那在测试时 它如果收到了错误的信息,它会一步错步步错,放大错误。
所以在训练的时候,给 Decoder 一些错误的信息,反倒会提升模型精确度。文章来源:https://www.toymoban.com/news/detail-519027.html
至此,Transformer 的所有讲解到此结束,参考资料如下:文章来源地址https://www.toymoban.com/news/detail-519027.html
- 台大李宏毅自注意力机制和Transformer详解
- 预训练语言模型的前世今生
到了这里,关于Transformer [全网最详细的Transformer讲解]的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!