C编译过程
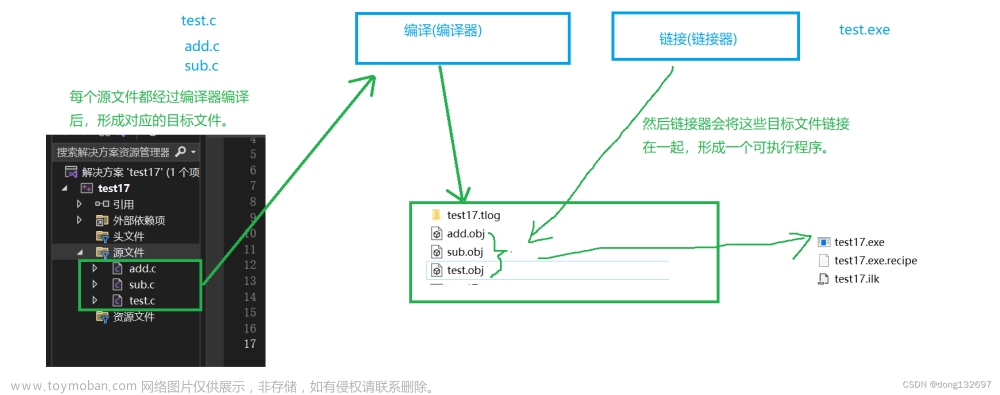
一个用C语言编写的高级语言程序是从编写到打包、再到编译执行的基本过程,我们知道在CPU上执行的是低级别的机器语言,从高级语言到低级别的机器语言肯定是要经过翻译过程,这个过程大体的过程如下图所示:
在Unix系统中,从源文件到可执行目标文件是由编译驱动程序完成的,如大名鼎鼎的 gcc,翻译过程包括图中的是个阶段;
-
预处理阶段
- 预处理器(cpp)根据以字符#开头的命令修给原始的C程序,结果得到另一个C程序,通常以.i作为文件扩展名。主要是进行
文本替换、宏展开、删除注释这类简单工作。 - 对应的命令:linux> gcc -E hello.c hello.i
- 预处理器(cpp)根据以字符#开头的命令修给原始的C程序,结果得到另一个C程序,通常以.i作为文件扩展名。主要是进行
-
编译阶段
- 编译器将文本文件 hello.i 翻译成 hello.s ,包含相应的汇编语言程序
- 对应的命令:linux> gcc -S hello.c hello.s
-
汇编阶段
-
将.s文件翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件.o中(把汇编语言翻译成机器语言的过程)。
-
把一个源程序翻译成目标程序的工作过程分为五个阶段:
词法分析;语法分析;语义检查和中间代码生成;代码优化;目标代码生成。主要是进行 词法分析 和 语法分析 ,又称为源程序分析,分析过程中发现有语法错误,给出提示信息。-
词法分析阶段是编译过程的第一个阶段。这个阶段的任务是从左到右一个字符一个字符地读入源程序,即
对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。词法分析程序实现这个任务。词法分析程序可以使用lex等工具自动生成。 -
语法分析是编译过程的一个逻辑阶段。语法分析的任务是
在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等.语法分析程序判断源程序在结构上是否正确.源程序的结构由上下文无关文法描述. -
语义分析是编译过程的一个逻辑阶段. 语义分析的任务是
对结构上正确的源程序进行上下文有关性质的审查, 进行类型审查.例如一个C程序片断:int arr[2], b;
b = arr * 10;
源程序的结构是正确的.
语义分析将审查类型并报告错误:不能在表达式中使用一个数组变量,赋值语句的右端和左端的类型不匹配.
-
在进行了语法分析和语义分析阶段的工作之后,有的编译程序将源程序变成一种内部表示形式,这种内部表示形式叫做中间语言或中间表示或中间代码。
所谓“中间代码”是一种结构简单、含义明确的记号系统,这种记号系统复杂性介于源程序语言和机器语言之间,容易将它翻译成目标代码。另外,还可以在中间代码一级进行与机器无关的优化。 -
想详细了解编译过程,请看:编译原理(douban.com)
-
-
对应的命令:linux> gcc -c hello.c hello.o
-
-
链接阶段
- 此时hello程序调用了printf函数。 printf函数存在于一个名为printf.o的单独的预编译目标文件中。 链接器(ld)就负责处理把这个文件并入到hello.o程序中,结果得到hello文件,一个可执行文件。
- 最后可执行文件加载到储存器后由系统负责执行, 函数库一般分为静态库和动态库两种。
- 静态库是指
编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为.a。 - 动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是
在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为.so,gcc在编译时默认使用动态库。
- 静态库是指
- 想详细了解链接脚本,请看:链接脚本(Linker Scripts)语法和规则解析(自官方手册) - BSP-路人甲 - 博客园 (cnblogs.com)
ELF文件
由上面的过程,我们可以看出在经过汇编器和连接器作用后都会输出一个目标文件,那这两个目标文件有什么样的区别呢?说到这里我们先引入目标文件的形式。
-
ELF(Executable Linkble Format)是一种Unix-like系统上的二进制文件格式标准。
-
ELF标准中定义的采用 ELF 格式的文件分为4类:
ELF文件类型 说明 实例 可重定位文件(Relocatable File) 内容包含了代码和数据,可以被链接成可执行文件或共享目标文件。 Linux上的 .o 文件 可执行文件(Executable File) 可以直接执行的程序 Linux上的 a.out 共享目标文件(Shared Object File) 内容包含了代码和数据,可以作为链接器的输入,在链接阶段和其他的 Relocatable File 或者 Shared Object File 一起链接成新的 Object File;或者在运行阶段,作为动态连接器的输入,和Executable File 结合,作为进程的一部分来运行。 Linux上的 .so 核心转储文件(Core Dump File) 进程意外终止时,系统可以将该进程的部分内容和终止时的状态信息保存到该文件中以供调试分析。 Linux 上的 core 文件 
文件格式
ELF文件格式提供了两种不同的视角,在汇编器和链接器看来,ELF文件是由Section Header Table描述的一系列Section的集合,而执行一个ELF文件时,在加载器(Loader)看来它是由Program Header Table描述的一系列Segment的集合
左边是从汇编器和链接器的视角来看这个文件,开头的 ELF Header 描述了体系结构和操作系统等基本信息,并指出 Section Header Table 和 Program Header Table 在文件中的什么位置,Program Header Table在汇编和链接过程中没有用到,所以是可有可无的,Section Header Table 中保存了所有 Section 的描述信息。
右边是从加载器的视角来看这个文件,开头是 ELF Header,Program Header Table 中保存了所有 Segment 的描述信息,Section Header Table 在加载过程中没有用到,所以是可有可无的。注意 Section Header Table 和 Program Header Table 并不是一定要位于文件开头和结尾的,其位置由 ELF Header 指出,上图这么画只是为了清晰。
我们在汇编程序中用 .section 声明的 Section 会成为目标文件中的Section,此外汇编器还会自动添加一些 Section(比如符号表)。Segment 是指在程序运行时加载到内存的具有相同属性的区域,由一个或多个 Section 组成,比如有两个 Section 都要求加载到内存后可读可写,就属于同一个 Segment。有些 Section 只对汇编器和链接器有意义,在运行时用不到,也不需要加载到内存,那么就不属于任何Segment。
目标文件需要链接器做进一步处理,所以一定有 Section Header Table;可执行文件需要加载运行,所以一定有 Program Header Table;而共享库既要加载运行,又要在加载时做动态链接,所以既有Section Header Table 又有 Program Header Table。
ELF可重定位文件
下面用 readelf 工具读出目标文件 max.o 的 ELF Header 和 Section Header Table,然后我们逐段分析。
接下来我们来看 Section Header Table 格式
从 Section Header 中读出各 Section 的描述信息,其中 .text 和 .data 是我们在汇编程序中声明的 Section,而其它 Section 是汇编器自动添加的。Addr是这些段加载到内存中的地址(我们讲过程序中的地址都是虚拟地址),加载地址要在链接时填写,现在空缺,所以是全0。Off和Size两列指出了各Section的文件地址,比如.data从文件地址0x60开始,一共0x38个字节,回去翻一下程序,.data中定义了14个4字节的整数,一共是56个字节,也就是0x38个。根据以上信息可以描绘出整个目标文件的布局。
| 起始文件地址 | Section或Header |
|---|---|
| 0 | ELF Header |
| 0x34 | .text |
| 0x60 | .data |
| 0x98 | .bss(此段为空) |
| 0x98 | .shstrtab |
| 0xc8 | Section Header Table |
| 0x208 | .symtab |
| 0x288 | .strtab |
| 0x2b0 | .rel.text |
这个文件不大,我们直接用hexdump或者使用010 Editor工具把目标文件的字节全部打印出来看。
.shstrtab和.strtab
.shstrtab 和 .strtab 这两个 Section 中存放的都是 ASCII 码:
可见 .shstrtab中保存着各Section的名字, .strtab中保存着程序中用到的符号的名字 。每个名字都是以’\0’结尾的字符串。
我们知道,C语言的全局变量如果在代码中没有初始化,就会在程序加载时用0初始化。这种数据属于.bss段,在加载时它和.data段一样都是可读可写的数据,但是在ELF文件中 .data 段需要占用一部分空间保存初始值,而 .bss 段则不需要。也就是说,.bss 段在文件中只占一个 Section Header 而没有对应的 Section,程序加载时 .bss 段占多大内存空间在 Section Header 中描述。在我们这个例子中没有用到 .bss 段,以后我们会看到这样的例子。
.rel.text和.symtab
我们继续分析 readelf 输出的最后一部分,是从 .rel.text 和 .symtab 这两个 Section 中读出的信息。
.rel.text 告诉链接器指令中的哪些地方需要重定位,我们在下一节讨论。
.symtab 是符号表。Ndx 列是每个符号所在的 Section 编号,例如 data_items 在第 3 个 Section 里(也就是 .data ),各 Section 的编号见 Section Header Table 。Value 列是每个符号所代表的地址,在目标文件中,符号地址都是相对于该符号所在Section的相对地址,比如 data_items 位于 .data 段的开头,所以地址是0,_start 位于 .text 段的开头,所以地址也是0,但是 start_loop 和 loop_exit 相对于 .text 段的地址就不是0了。从 Bind 这一列可以看出 _start 这个符号是 GLOBAL 的,而其它符号是 LOCAL 的,GLOBAL 符号是在汇编程序中用 .globl 指示声明过的符号。
.text节
通过使用 objdump 工具可以把程序中的机器指令进行反汇编(Disassemble),得到其汇编代码
ELF可执行文件
先看可执行文件header的变化
在看section header的变化
.text和.data的加载地址分别改成了 0x08048074 和 0x080490a0 。.bss段没有用到,所以被删掉了。.rel.text段就是用于链接过程的,链接完了就没用了,所以也删掉了。
在看多出来的两个program header
多出来的Program Header Table描述了两个Segment的信息。.text段和前面的 ELFHeader、Program Header Table 一起组成一个 Segment(FileSiz指出总长度是0x9e),.data段组成另一个Segment(总长度是0x38)。VirtAddr列指出第一个Segment加载到虚拟地址0x0804 8000(注意在x86平台上后面的PhysAddr列是没有意义的),第二个Segment加载到地址0x0804 90a0。Flg列指出第一个Segment的访问权限是可读可执行,第二个Segment的访问权限是可读可写。最后一列Align的值0x1000(4K)是x86平台的内存页面大小。在加载时要求文件中的一页对应内存中的一页,对应关系如下图所示。
这个可执行文件很小,总共也不超过一页大小,但是两个Segment 必须加载到内存中两个不同的页面,因为 MMU 的权限保护机制是以页为单位的,一个页面只能设置一种权限。此外还规定每个Segment在文件页面内偏移多少加载到内存页面仍然偏移多少,比如第二个Segment在文件中的偏移是0xa0,在内存页面0x0804 9000中的偏移仍然是0xa0,所以是从0x0804 90a0开始,这样规定是为了简化链接器和加载器的实现。从上图也可以看出.text段的加载地址应该是0x0804 8074,也正是_start符号的地址和程序的入口地址。
原来目标文件符号表中的Value都是相对地址,现在都改成绝对地址了。此外还多了三个符号 __bss_start、 _edata 和 _end,这些是在链接过程中添进去的,加载器可以利用这些信息把 .bss段初始化为0。
再看一下反汇编的结果:
参考
ELF文件详解—初步认识_code&poetry的博客-CSDN博客文章来源:https://www.toymoban.com/news/detail-519332.html
词法分析、语法分析、语义分析 - JackYang - 博客园 (cnblogs.com)文章来源地址https://www.toymoban.com/news/detail-519332.html
到了这里,关于C编译过程 以及 ELF文件(学习笔记)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!