文章来源地址https://www.toymoban.com/news/detail-519479.html
文章来源:https://www.toymoban.com/news/detail-519479.html
到了这里,关于[算法前沿]--008- AIGC和LLM下的Prompt Tuning微调范式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
这篇具有很好参考价值的文章主要介绍了[算法前沿]--008- AIGC和LLM下的Prompt Tuning微调范式。希望对大家有所帮助。如果存在错误或未考虑完全的地方,请大家不吝赐教,您也可以点击"举报违法"按钮提交疑问。
文章来源地址https://www.toymoban.com/news/detail-519479.html
文章来源:https://www.toymoban.com/news/detail-519479.html
到了这里,关于[算法前沿]--008- AIGC和LLM下的Prompt Tuning微调范式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处: 如若内容造成侵权/违法违规/事实不符,请点击违法举报进行投诉反馈,一经查实,立即删除!
🔥 下面我只是分析讲解下这些方法的原理以及具体代码是怎么实现的,不对效果进行评价,毕竟不同任务不同数据集效果差别还是挺大的。 hard prompt (离散):即人类写的自然语言式的prompt。 soft prompt (连续):可训练的权重,可以理解为伪prompt。【毕竟nn是连续的模型,在连续
前三章我们分别介绍了思维链的使用,原理和在小模型上的使用。这一章我们正式进入应用层面,聊聊如何把思维链和工具使用结合得到人工智能代理。 要回答我们为什么需要AI代理?代理可以解决哪些问题?可以有以下两个视角 首先是我们赋能模型,如果说 LLM是大脑,那
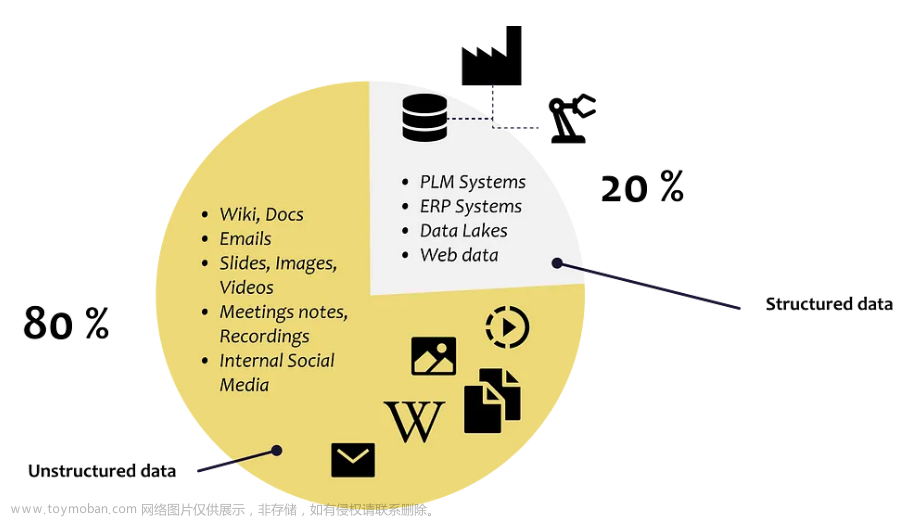
随着,ChatGPT 迅速爆火,引发了大模型的时代变革。然而对于普通大众来说,进行大模型的预训练或者全量微调遥不可及。由此,催生了各种参数高效微调技术,让科研人员或者普通开发者有机会尝试微调大模型。 因此,该技术值得我们进行深入分析其背后的机理,本系列大
大家都是希望让预训练语言模型和下游任务靠的更近,只是实现的方式不一样。Fine-tuning中:是预训练语言模型“迁就“各种下游任务;Prompting中,是各种下游任务“迁就“预训练语言模型。 微调(fine-tuning)和prompt是自然语言处理领域中常用的两个术语,它们都是指训练和

在机器学习中,Prompt通常指的是一种生成模型的输入方式。生成模型可以接收一个Prompt作为输入,并生成与该输入相对应的输出。Prompt可以是一段文本、一个问题或者一个片段,用于指导生成模型生成相应的响应、续写文本等。 一般大模型蕴含的训练数据量往往是百亿级别甚

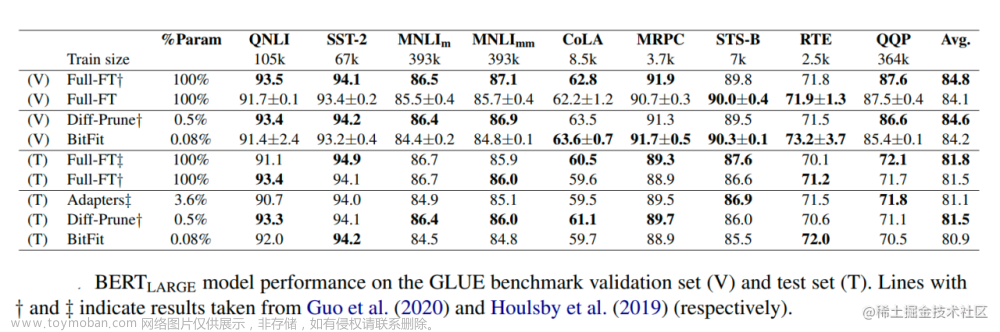
【论文极速读】Prompt Tuning——一种高效的LLM模型下游任务适配方式 FesianXu 20230928 at Baidu Search Team Prompt Tuning是一种PEFT方法(Parameter-Efficient FineTune),旨在以高效的方式对LLM模型进行下游任务适配,本文简要介绍Prompt Tuning方法,希望对读者有所帮助。如有谬误请见谅并联系指

1 指令微调数据集形式“花样”太多 大家有没有分析过 prompt对模型训练或者推理的影响?之前推理的时候,发现不加训练的时候prompt,直接输入模型性能会变差的,这个倒是可以理解。假如不加prompt直接训练,是不是测试的时候不加prompt也可以?还有一个就是多轮prompt和单轮
![[NLP]LLM---大模型指令微调中的“Prompt”](https://imgs.yssmx.com/Uploads/2024/02/703660-1.png)
大家有没有分析过 prompt对模型训练或者推理的影响?之前推理的时候,发现不加训练的时候prompt,直接输入模型性能会变差的,这个倒是可以理解。假如不加prompt直接训练,是不是测试的时候不加prompt也可以?还有一个就是多轮prompt和单轮prompt怎么构造的问题?好多模型训练
本文是Hugging Face 上 NLP的一篇代码教程,通过imdb数据集, Fine-tuning微调 Bert预训练模型。 涉及包括: MLM, Bert, Fine-tuning, IMDB, Huggingface Repo 微调的方式是通过调整训练模型的学习率来重新训练模型,这个来自 早期 ACL 2018的一篇paper: 《Universal Language Model Fine-tuning for Text

上一章我们介绍了基于Prompt范式的工具调用方案,这一章介绍基于模型微调,支持任意多工具组合调用,复杂调用的方案。多工具调用核心需要解决3个问题,在哪个位置进行工具调用(where), 从众多工具中选择哪一个(Which), 工具的输入是什么(What)。Where + Which + What,我称之为



