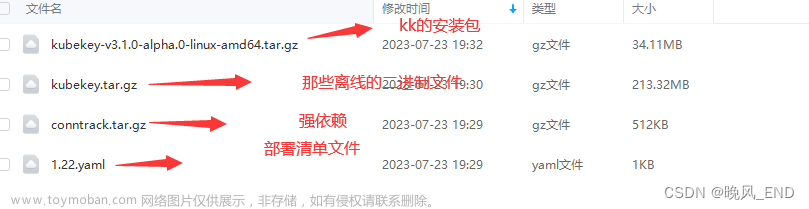
前言:
kubesphere的离线化部署指的是通过自己搭建的harbor私有仓库拉取镜像,完全不依赖于外部网络的方式部署。
我的kubernetes集群是一个单master节点,双工作节点,总计三个节点的版本为1.22.16的集群。
该集群只是初始化完成了,网络插件什么的都还没有安装,本文计划做一个整合,将metric server,网络插件,storageclass nfs存储插件的部署整合到这一个文章中来,在将kubesphere这些部署依赖安装完毕后,将镜像推送到自己搭建的一个带有证书的harbor私有仓库内,然后,通过私有仓库秒速完成kubesphere部署。
一,
集群环境介绍
master 192.168.123.11
slave1 192.168.123.12
slave2 192.168.123.13
集群是使用kubeadm安装部署的,etcd是使用的外部自建etcd集群,操作系统是centos7
离线的images下载地址:
链接:https://pan.baidu.com/s/1EjTX4gmhRb1c0JYMLWaL_w?pwd=xshe
提取码:xshe
harbor私有仓库 https://192.168.123.14
[root@centos1 ~]# kubectl get no -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
centos2 NotReady <none> 6d19h v1.22.16 192.168.123.12 <none> CentOS Linux 7 (Core) 5.16.9-1.el7.elrepo.x86_64 docker://20.10.7
centos3 NotReady <none> 6d19h v1.22.16 192.168.123.13 <none> CentOS Linux 7 (Core) 5.16.9-1.el7.elrepo.x86_64 docker://20.10.7
master NotReady control-plane,master 6d19h v1.22.16 192.168.123.11 <none> CentOS Linux 7 (Core) 5.16.9-1.el7.elrepo.x86_64 docker://20.10.7
[root@centos1 ~]# kubectl get po -A -owide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-7f6cbbb7b8-cndqt 0/1 Pending 0 6d19h <none> <none> <none> <none>
kube-system coredns-7f6cbbb7b8-pk4mv 0/1 Pending 0 6d19h <none> <none> <none> <none>
kube-system kube-apiserver-master 1/1 Running 6 (14m ago) 6d19h 192.168.123.11 master <none> <none>
kube-system kube-controller-manager-master 1/1 Running 6 (14m ago) 6d19h 192.168.123.11 master <none> <none>
kube-system kube-proxy-7bqs7 1/1 Running 3 (6d18h ago) 6d19h 192.168.123.13 centos3 <none> <none>
kube-system kube-proxy-8hkdn 1/1 Running 3 (6d18h ago) 6d19h 192.168.123.12 centos2 <none> <none>
kube-system kube-proxy-jkghf 1/1 Running 6 (14m ago) 6d19h 192.168.123.11 master <none> <none>
kube-system kube-scheduler-master 1/1 Running 6 (14m ago) 6d19h 192.168.123.11 master <none> <none>

二,
网络插件flannel的安装(三个kubernetes节点都执行)
####注,如果cidr不是10.244.0.0 那么需要更改为实际的
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
[root@centos1 ~]# tar Cvxf /opt/cni/bin/ cni-plugins-linux-amd64-v1.2.0.tgz
./
./loopback
./bandwidth
./ptp
./vlan
./host-device
./tuning
./vrf
./sbr
./dhcp
./static
./firewall
./macvlan
./dummy
./bridge
./ipvlan
./portmap
./host-local
kubectl apply -f kube-flannel.yml cat kube-flannel.yml
apiVersion: v1
kind: Namespace
metadata:
labels:
k8s-app: flannel
pod-security.kubernetes.io/enforce: privileged
name: kube-flannel
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: flannel
name: flannel
namespace: kube-flannel
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: flannel
name: flannel
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- networking.k8s.io
resources:
- clustercidrs
verbs:
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: flannel
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-flannel
---
apiVersion: v1
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
kind: ConfigMap
metadata:
labels:
app: flannel
k8s-app: flannel
tier: node
name: kube-flannel-cfg
namespace: kube-flannel
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: flannel
k8s-app: flannel
tier: node
name: kube-flannel-ds
namespace: kube-flannel
spec:
selector:
matchLabels:
app: flannel
k8s-app: flannel
template:
metadata:
labels:
app: flannel
k8s-app: flannel
tier: node
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
containers:
- args:
- --ip-masq
- --kube-subnet-mgr
command:
- /opt/bin/flanneld
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: EVENT_QUEUE_DEPTH
value: "5000"
image: docker.io/flannel/flannel:v0.22.0
name: kube-flannel
resources:
requests:
cpu: 100m
memory: 50Mi
securityContext:
capabilities:
add:
- NET_ADMIN
- NET_RAW
privileged: false
volumeMounts:
- mountPath: /run/flannel
name: run
- mountPath: /etc/kube-flannel/
name: flannel-cfg
- mountPath: /run/xtables.lock
name: xtables-lock
hostNetwork: true
initContainers:
- args:
- -f
- /flannel
- /opt/cni/bin/flannel
command:
- cp
image: docker.io/flannel/flannel-cni-plugin:v1.1.2
name: install-cni-plugin
volumeMounts:
- mountPath: /opt/cni/bin
name: cni-plugin
- args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
command:
- cp
image: docker.io/flannel/flannel:v0.22.0
name: install-cni
volumeMounts:
- mountPath: /etc/cni/net.d
name: cni
- mountPath: /etc/kube-flannel/
name: flannel-cfg
priorityClassName: system-node-critical
serviceAccountName: flannel
tolerations:
- effect: NoSchedule
operator: Exists
volumes:
- hostPath:
path: /run/flannel
name: run
- hostPath:
path: /opt/cni/bin
name: cni-plugin
- hostPath:
path: /etc/cni/net.d
name: cni
- configMap:
name: kube-flannel-cfg
name: flannel-cfg
- hostPath:
path: /run/xtables.lock
type: FileOrCreate
name: xtables-lock
等待片刻后,就可以看到整个集群正常了。
[root@centos1 ~]# kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-5c6qs 1/1 Running 0 119s
kube-flannel kube-flannel-ds-gf966 1/1 Running 0 119s
kube-flannel kube-flannel-ds-pklq5 1/1 Running 0 119s
kube-system coredns-7f6cbbb7b8-cndqt 1/1 Running 0 6d19h
kube-system coredns-7f6cbbb7b8-pk4mv 1/1 Running 0 6d19h
kube-system kube-apiserver-master 1/1 Running 6 (21m ago) 6d19h
kube-system kube-controller-manager-master 1/1 Running 6 (22m ago) 6d19h
kube-system kube-proxy-7bqs7 1/1 Running 3 (6d18h ago) 6d19h
kube-system kube-proxy-8hkdn 1/1 Running 3 (6d18h ago) 6d19h
kube-system kube-proxy-jkghf 1/1 Running 6 (22m ago) 6d19h
kube-system kube-scheduler-master 1/1 Running 6 (22m ago) 6d19h
三,
metric server的安装部署
编辑 vim /etc/kubernetes/manifests/kube-apiserver.yaml这个文件,在此文件内添加 - --enable-aggregator-routing=true 这个字段即可,apiserver会自动重启生效网络聚合功能。
具体插入位置建议在enable下面,示例如下:
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=192.168.123.11
- --allow-privileged=true
- --authorization-mode=Node,RBAC
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --enable-admission-plugins=NodeRestriction
- --enable-bootstrap-token-auth=true
- --enable-aggregator-routing=true
- --etcd-cafile=/etc/kubernetes/pki/etcd/ca.pem
部署文件内容如下:
[root@centos1 ~]# cat components-metrics.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
- configmaps
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP #删掉 ExternalIP,Hostname这两个,这里已经改好了
- --kubelet-use-node-status-port
- --kubelet-insecure-tls #加上该启动参数
image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.4.1
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
periodSeconds: 10
securityContext:
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
执行结果如下:
[root@centos1 ~]# kubectl apply -f components-metrics.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
稍等片刻,等pod启动后,验证metric server是否部署成功:
[root@centos1 ~]# kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-5c6qs 1/1 Running 0 9m34s
kube-flannel kube-flannel-ds-gf966 1/1 Running 0 9m34s
kube-flannel kube-flannel-ds-pklq5 1/1 Running 0 9m34s
kube-system coredns-7f6cbbb7b8-cndqt 1/1 Running 0 6d19h
kube-system coredns-7f6cbbb7b8-pk4mv 1/1 Running 0 6d19h
kube-system kube-apiserver-master 1/1 Running 0 3m7s
kube-system kube-controller-manager-master 1/1 Running 0 3m6s
kube-system kube-proxy-7bqs7 1/1 Running 3 (6d18h ago) 6d19h
kube-system kube-proxy-8hkdn 1/1 Running 3 (6d18h ago) 6d19h
kube-system kube-proxy-jkghf 1/1 Running 6 (29m ago) 6d19h
kube-system kube-scheduler-master 1/1 Running 0 3m6s
kube-system metrics-server-55b9b69769-gdgvp 1/1 Running 0 84s
[root@centos1 ~]# kubectl top no
\NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
centos2 44m 1% 428Mi 5%
centos3 42m 1% 444Mi 5%
master 82m 2% 938Mi 11%
四,
nfs storageclass存储插件的安装
三个kubernetes节点都执行:
yum install nfs-utils rpcbind -y
systemctl enable nfs rpcbind && systemctl start nfs rpcbind计划nfs服务是安装在master节点,因此,在master节点执行:
####注,nfs服务的配置文件内的IP网段需要根据实际修改哦,这些千万不要忘了修改。
[root@centos1 ~]# mkdir -p /data/nfs-sc
[root@centos1 ~]# cat /etc/exports
/data/nfs-sc 10.244.0.0/16(rw,no_root_squash,no_subtree_check) 192.168.123.11(rw,no_root_squash,no_subtree_check) 192.168.123.0/24(rw,no_root_squash,no_subtree_check)
[root@centos1 ~]# systemctl restart nfs rpcbind
在14服务器上执行:
####注,这一步是在kubernetes节点启用harbor的客户端,因为登录的时候需要读取相关证书。
[root@centos4 harbor]# scp -r /etc/docker/certs.d/ 192.168.123.11:/etc/docker/
root@192.168.123.11's password:
192.168.123.14.cert 100% 2057 1.8MB/s 00:00
192.168.123.14.key 100% 3243 3.4MB/s 00:00
ca.crt 100% 2033 2.2MB/s 00:00
[root@centos4 harbor]# scp -r /etc/docker/certs.d/ 192.168.123.12:/etc/docker/
root@192.168.123.12's password:
192.168.123.14.cert 100% 2057 2.4MB/s 00:00
192.168.123.14.key 100% 3243 4.0MB/s 00:00
ca.crt 100% 2033 2.7MB/s 00:00
[root@centos4 harbor]# scp -r /etc/docker/certs.d/ 192.168.123.13:/etc/docker/
root@192.168.123.13's password:
192.168.123.14.cert 100% 2057 2.4MB/s 00:00
192.168.123.14.key 100% 3243 4.5MB/s 00:00
ca.crt 回到master服务器执行:
#####注,这一步是为了生成harbor仓库的登录信息,可以看到输出表明登录信息是保存到了 /root/.docker/config.json这个文件内
[root@centos1 ~]# docker login https://192.168.123.14
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
将密钥进行base64加密
####注,加密登录信息,以提供给secret使用
cat /root/.docker/config.json | base64 -w 0新建secret部署文件,保存上述生成的密钥
####注,一定要准确复制上面的加密信息,填写到此文件内
[root@centos1 ~]# cat harbor_secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: harbor-login
type: kubernetes.io/dockerconfigjson
data:
# 这里添加上述base64加密后的密钥
.dockerconfigjson: ewoJImF1dGhzIjogewoJCSIxOTIuMTY4LjEyMy4xNCI6IHsKCQkJImF1dGgiOiAiWVdSdGFXNDZVMmhwWjNWaGJtZGZNekk9IgoJCX0KCX0KfQ==
[root@centos1 ~]# kubectl apply -f harbor_secret.yaml
secret/harbor-login created
nfs存储插件的部署文件(三个文件按顺序执行,里面的相关ip,secret等等根据自己的实际修改):
####注,第一个文件没什么说的,不需要做任何更改,第二个文件使用的是harbor私有仓库,也算是提前测试了一下harbor是否功能正常,这个文件内的IP什么的一定要仔细修改
[root@centos1 ~]# cat serviceacount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
namespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["get", "list", "watch","create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: kube-system
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: kube-system
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: kube-system
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: kube-system
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
[root@centos1 ~]# cat deploy-nfs.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-client-provisioner
namespace: kube-system
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: 192.168.123.14/library/registry.cn-shanghai.aliyuncs.com/c7n/nfs-client-provisioner:v3.1.0-k8s1.11
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: fuseim.pri/ifs
- name: NFS_SERVER
value: 192.168.123.11
- name: NFS_PATH
value: /data/nfs-sc
volumes:
- name: nfs-client-root
nfs:
server: 192.168.123.11
path: /data/nfs-sc
imagePullSecrets:
- name: harbor-login
[root@centos1 ~]# cat storageclass-nfs.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage
annotations:
storageclass.beta.kubernetes.io/is-default-class: "true"
provisioner: fuseim.pri/ifs
reclaimPolicy: Delete
allowVolumeExpansion: True #允许pvc创建后扩容
初步验证:
[root@centos1 ~]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
managed-nfs-storage (default) fuseim.pri/ifs Delete Immediate true 10m
五,
命令补全的设置
考虑到后面的操作需要使用命令行的场景就非常多了,为了方便后续操作,设置命令补全
yum -y install bash-completion
source /usr/share/bash-completion/bash_completion
echo "source <(kubectl completion bash)" >>/etc/profile
echo "source /usr/share/bash-completion/bash_completion" >>/etc/profile
kubectl completion bash | sudo tee /etc/bash_completion.d/kubectl > /dev/null使用别名k代替kubectl命令
####注,这个没什么好说的了,干就行了
echo "alias k=kubectl">>/etc/profile
echo "complete -F __start_kubectl k">>/etc/profile
source /etc/profile六,
外部etcd证书的处理
####注,一般外部etcd基本都是和我的部署目录一样,没什么好说的,注意证书的对应关系。
[root@centos1 ~]# cp /opt/etcd/ssl/server.pem /etc/kubernetes/pki/etcd/healthcheck-client.crt
[root@centos1 ~]# cp /opt/etcd/ssl/server-key.pem /etc/kubernetes/pki/etcd/healthcheck-client.key
[root@centos1 ~]# cp /opt/etcd/ssl/ca.pem /etc/kubernetes/pki/etcd/ca.crt
[root@centos1 data]# scp -r /etc/kubernetes/pki/etcd/* slave1:/etc/kubernetes/pki/etcd/
100% 1675 1.1MB/s 00:00
apiserver-etcd-client.pem 100% 1338 1.3MB/s 00:00
ca.crt 100% 1265 2.0MB/s 00:00
ca.pem 100% 1265 1.6MB/s 00:00
healthcheck-client.crt 100% 1338 2.6MB/s 00:00
healthcheck-client.key 100% 1675 2.6MB/s 00:00
[root@centos1 data]# scp -r /etc/kubernetes/pki/etcd/* slave2:/etc/kubernetes/pki/etcd/
100% 1675 1.0MB/s 00:00
apiserver-etcd-client.pem 100% 1338 2.0MB/s 00:00
ca.crt 100% 1265 2.3MB/s 00:00
ca.pem 100% 1265 2.0MB/s 00:00
healthcheck-client.crt 100% 1338 2.6MB/s 00:00
healthcheck-client.key
#### 注:提前创建了namespace
[root@centos1 ~]# kubectl create ns kubesphere-monitoring-system
namespace/kubesphere-monitoring-system created
[root@centos1 ~]# kubectl -n kubesphere-monitoring-system create secret generic kube-etcd-client-certs --from-file=etcd-client-ca.crt=/etc/kubernetes/pki/etcd/ca.crt --from-file=etcd-client.crt=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=etcd-client.key=/etc/kubernetes/pki/etcd/healthcheck-client.key
secret/kube-etcd-client-certs created
七,
上传离线镜像到harbor私有仓库
1,
百度云的镜像是我收集的,从百度云下载下来后,随便找一个有Docker环境的服务器,将离线镜像导入服务器,本例是使用的kubernetes的master节点(虽然违规,但方便):
for i in `ls /root/image/*`;do docker load <$i;done输出大概是这样的:
7f4c27344f24: Loading layer [==================================================>] 3.072kB/3.072kB
Loaded image: quay.io/argoproj/argocd:v2.3.3
f424150e7bdd: Loading layer [==================================================>] 12.29kB/12.29kB
af2908c6d8d4: Loading layer [==================================================>] 2.192MB/2.192MB
eb1df1609b52: Loading layer [==================================================>] 22.53MB/22.53MB
9dc4b900734e: Loading layer [==================================================>] 2.048kB/2.048kB
658356a2e199: Loading layer [==================================================>] 3.584kB/3.584kB
Loaded image: redis:5.0.14-alpine
a0d30d692d38: Loading layer [==================================================>] 25.52MB/25.52MB
ea119ba57232: Loading layer [==================================================>] 2.048kB/2.048kB
4093453af757: Loading layer [==================================================>] 3.584kB/3.584kB
Loaded image: redis:6.2.6-alpine
Loaded image: registry.aliyuncs.com/google_containers/coredns:v1.8.4
Loaded image: registry.aliyuncs.com/google_containers/kube-apiserver:v1.22.16
Loaded image: registry.aliyuncs.com/google_containers/kube-controller-manager:v1.22.16
Loaded image: registry.aliyuncs.com/google_containers/kube-proxy:v1.22.16
Loaded image: registry.aliyuncs.com/google_containers/kube-scheduler:v1.22.16
Loaded image: registry.aliyuncs.com/google_containers/pause:3.5
2,
将离线镜像以镜像名称:镜像版本号的形式保存到文本文件内,那么,脚本应该如下:
#!/bin/bash
docker images|while read i t _;do
[[ "${t}" == "TAG" ]] && continue
echo $i:$t
done通过重定向命令导入到指定文件内:
bash 脚本名 > images-list-new.txt文件内容如下:
[root@centos1 ~]# cat images-list-new.txt
flannel/flannel:v0.22.0
kubesphere/ks-installer:v3.3.2
kubesphere/ks-controller-manager:v3.3.2
kubesphere/ks-console:v3.3.2
kubesphere/ks-apiserver:v3.3.2
kubesphere/devops-controller:ks-v3.3.2
kubesphere/devops-tools:ks-v3.3.2
kubesphere/devops-apiserver:ks-v3.3.2
kubesphere/openpitrix-jobs:v3.3.2
kubesphere/log-sidecar-injector:v1.2.0
flannel/flannel-cni-plugin:v1.1.2
registry.aliyuncs.com/google_containers/kube-apiserver:v1.22.16
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.22.16
registry.aliyuncs.com/google_containers/kube-proxy:v1.22.16
registry.aliyuncs.com/google_containers/kube-scheduler:v1.22.16
kubesphere/kube-state-metrics:v2.5.0
kubesphere/ks-jenkins:v3.3.0-2.319.1
kubesphere/fluent-bit:v1.8.11
kubesphere/s2ioperator:v3.2.1
quay.io/argoproj/argocd:v2.3.3
kubesphere/prometheus-config-reloader:v0.55.1
kubesphere/prometheus-operator:v0.55.1
thanosio/thanos:v0.25.2
prom/prometheus:v2.34.0
kubesphere/fluentbit-operator:v0.13.0
quay.io/argoproj/argocd-applicationset:v0.4.1
kubesphere/kube-events-ruler:v0.4.0
kubesphere/kube-events-operator:v0.4.0
kubesphere/kube-events-exporter:v0.4.0
kubesphere/elasticsearch-oss:6.8.22
prom/node-exporter:v1.3.1
redis:5.0.14-alpine
redis:6.2.6-alpine
haproxy:2.0.25-alpine
ghcr.io/dexidp/dex:v2.30.2
alpine:3.14
kubesphere/kubectl:v1.22.0
kubesphere/notification-manager:v1.4.0
jaegertracing/jaeger-operator:1.27
jaegertracing/jaeger-es-index-cleaner:1.27
jaegertracing/jaeger-query:1.27
jaegertracing/jaeger-collector:1.27
jaegertracing/jaeger-agent:1.27
kubesphere/notification-tenant-sidecar:v3.2.0
kubesphere/notification-manager-operator:v1.4.0
prom/alertmanager:v0.23.0
istio/proxyv2:1.11.1
istio/install-cni:1.11.1
istio/pilot:1.11.1
kubesphere/kube-auditing-operator:v0.2.0
kubesphere/kube-auditing-webhook:v0.2.0
kubesphere/kube-rbac-proxy:v0.11.0
kubesphere/kiali-operator:v1.38.1
kubesphere/kiali:v1.38
kubesphere/ks-installer:v3.1.1
registry.aliyuncs.com/google_containers/coredns:v1.8.4
docker:19.03
nginx:1.18
registry.aliyuncs.com/google_containers/pause:3.5
jimmidyson/configmap-reload:v0.5.0
csiplugin/snapshot-controller:v4.0.0
registry.cn-shanghai.aliyuncs.com/c7n/nfs-client-provisioner:v3.1.0-k8s1.11
registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.4.1
kubesphere/kube-rbac-proxy:v0.8.0
osixia/openldap:1.3.0
kubesphere/elasticsearch-curator:v5.7.6
minio/mc:RELEASE.2019-08-07T23-14-43Z
minio/minio:RELEASE.2019-08-07T01-59-21Z
tomcat:8.5.41-alpine
mirrorgooglecontainers/defaultbackend-amd64:1.4
ananwaresystems/webarchive:1.0
根据上面步骤生成的镜像信息,修改所有镜像标签,并推送到私有Harbor仓库。
vim push-images.sh
#!/bin/bash
for i in `cat images-list-new.txt`;
do
docker tag $i 192.168.123.14/library/$i
echo "tag xiu gai chengong"
docker push 192.168.123.14/library/$i
echo "push chenggong"
done
输出如下:
push chenggong
tag xiu gai chengong
The push refers to repository [192.168.123.14/library/ananwaresystems/webarchive]
5f70bf18a086: Layer already exists
bcd447c7ceca: Pushed
3973dc7c145c: Pushed
f8245f5490d6: Pushed
7f02483a9752: Pushed
1.0: digest: sha256:bd4ef0cff8106548b898b77c5c2d9b2a8b3b312efd236a84c354218e2445aa52 size: 1767
push chenggong
部分镜像修正,重新推送:
docker tag 192.168.123.14/library/docker:19.03 192.168.123.14/library/library/docker:19.03
docker push 192.168.123.14/library/library/docker:19.03
docker tag redis:5.0.14-alpine 192.168.123.14/library/library/redis:5.0.14-alpine
docker push 192.168.123.14/library/library/redis:5.0.14-alpine
docker tag 192.168.123.14/library/redis:6.2.6-alpine 192.168.123.14/library/library/redis:6.2.6-alpine
docker push 192.168.123.14/library/library/redis:6.2.6-alpine
docker tag 192.168.123.14/library/quay.io/argoproj/argocd-applicationset:v0.4.1 192.168.123.14/library/argoproj/argocd-applicationset:v0.4.1
docker push 192.168.123.14/library/argoproj/argocd-applicationset:v0.4.1
docker tag 192.168.123.14/library/ghcr.io/dexidp/dex:v2.30.2 192.168.123.14/library/dexidp/dex:v2.30.2
docker push 192.168.123.14/library/dexidp/dex:v2.30.2
docker tag 192.168.123.14/library/alpine:3.14 192.168.123.14/library/library/alpine:3.14
docker push 192.168.123.14/library/library/alpine:3.14
八,
开始正式部署(部署时间大概为5分钟,非常迅速)
###注,kubesphere-install这个文件使用的是私有仓库,因此,image修改了,并加了拉取secret。
[root@centos1 ~]# cat kubesphere-installer.yaml
---
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: clusterconfigurations.installer.kubesphere.io
spec:
group: installer.kubesphere.io
versions:
- name: v1alpha1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
x-kubernetes-preserve-unknown-fields: true
status:
type: object
x-kubernetes-preserve-unknown-fields: true
scope: Namespaced
names:
plural: clusterconfigurations
singular: clusterconfiguration
kind: ClusterConfiguration
shortNames:
- cc
---
apiVersion: v1
kind: Namespace
metadata:
name: kubesphere-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: ks-installer
namespace: kubesphere-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: ks-installer
rules:
- apiGroups:
- ""
resources:
- '*'
verbs:
- '*'
- apiGroups:
- apps
resources:
- '*'
verbs:
- '*'
- apiGroups:
- extensions
resources:
- '*'
verbs:
- '*'
- apiGroups:
- batch
resources:
- '*'
verbs:
- '*'
- apiGroups:
- rbac.authorization.k8s.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- apiregistration.k8s.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- apiextensions.k8s.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- tenant.kubesphere.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- certificates.k8s.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- devops.kubesphere.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- monitoring.coreos.com
resources:
- '*'
verbs:
- '*'
- apiGroups:
- logging.kubesphere.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- jaegertracing.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- storage.k8s.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- admissionregistration.k8s.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- policy
resources:
- '*'
verbs:
- '*'
- apiGroups:
- autoscaling
resources:
- '*'
verbs:
- '*'
- apiGroups:
- networking.istio.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- config.istio.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- iam.kubesphere.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- notification.kubesphere.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- auditing.kubesphere.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- events.kubesphere.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- core.kubefed.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- installer.kubesphere.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- storage.kubesphere.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- security.istio.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- monitoring.kiali.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- kiali.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- networking.k8s.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- edgeruntime.kubesphere.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- types.kubefed.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- monitoring.kubesphere.io
resources:
- '*'
verbs:
- '*'
- apiGroups:
- application.kubesphere.io
resources:
- '*'
verbs:
- '*'
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: ks-installer
subjects:
- kind: ServiceAccount
name: ks-installer
namespace: kubesphere-system
roleRef:
kind: ClusterRole
name: ks-installer
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: ks-installer
namespace: kubesphere-system
labels:
app: ks-installer
spec:
replicas: 1
selector:
matchLabels:
app: ks-installer
template:
metadata:
labels:
app: ks-installer
spec:
serviceAccountName: ks-installer
containers:
- name: installer
image: 192.168.123.14/library/kubesphere/ks-installer:v3.3.2
imagePullPolicy: "Always"
resources:
limits:
cpu: "1"
memory: 1Gi
requests:
cpu: 20m
memory: 100Mi
volumeMounts:
- mountPath: /etc/localtime
name: host-time
readOnly: true
volumes:
- hostPath:
path: /etc/localtime
type: ""
name: host-time
imagePullSecrets:
- name: harbor-login
部署执行文件,该文件内的IP地址和etcd的检查点需要根据实际情况填写,由于前面推送的是library,因此,local_registry: 192.168.123.14/library
[root@centos1 ~]# cat cluster-configuration.yaml
---
apiVersion: installer.kubesphere.io/v1alpha1
kind: ClusterConfiguration
metadata:
name: ks-installer
namespace: kubesphere-system
labels:
version: v3.3.2
spec:
persistence:
storageClass: "" # If there is no default StorageClass in your cluster, you need to specify an existing StorageClass here.
authentication:
# adminPassword: "" # Custom password of the admin user. If the parameter exists but the value is empty, a random password is generated. If the parameter does not exist, P@88w0rd is used.
jwtSecret: "" # Keep the jwtSecret consistent with the Host Cluster. Retrieve the jwtSecret by executing "kubectl -n kubesphere-system get cm kubesphere-config -o yaml | grep -v "apiVersion" | grep jwtSecret" on the Host Cluster.
local_registry: 192.168.123.14/library # Add your private registry address if it is needed.
# dev_tag: "" # Add your kubesphere image tag you want to install, by default it's same as ks-installer release version.
etcd:
monitoring: true # Enable or disable etcd monitoring dashboard installation. You have to create a Secret for etcd before you enable it.
endpointIps: 192.168.123.11 # etcd cluster EndpointIps. It can be a bunch of IPs here.
port: 2379 # etcd port.
tlsEnable: true
common:
core:
console:
enableMultiLogin: true # Enable or disable simultaneous logins. It allows different users to log in with the same account at the same time.
port: 30880
type: NodePort
# apiserver: # Enlarge the apiserver and controller manager's resource requests and limits for the large cluster
# resources: {}
# controllerManager:
# resources: {}
redis:
enabled: true
enableHA: false
volumeSize: 2Gi # Redis PVC size.
openldap:
enabled: true
volumeSize: 2Gi # openldap PVC size.
minio:
volumeSize: 20Gi # Minio PVC size.
monitoring:
# type: external # Whether to specify the external prometheus stack, and need to modify the endpoint at the next line.
endpoint: http://prometheus-operated.kubesphere-monitoring-system.svc:9090 # Prometheus endpoint to get metrics data.
GPUMonitoring: # Enable or disable the GPU-related metrics. If you enable this switch but have no GPU resources, Kubesphere will set it to zero.
enabled: false
gpu: # Install GPUKinds. The default GPU kind is nvidia.com/gpu. Other GPU kinds can be added here according to your needs.
kinds:
- resourceName: "nvidia.com/gpu"
resourceType: "GPU"
default: true
es: # Storage backend for logging, events and auditing.
# master:
# volumeSize: 4Gi # The volume size of Elasticsearch master nodes.
# replicas: 1 # The total number of master nodes. Even numbers are not allowed.
# resources: {}
# data:
# volumeSize: 20Gi # The volume size of Elasticsearch data nodes.
# replicas: 1 # The total number of data nodes.
# resources: {}
logMaxAge: 7 # Log retention time in built-in Elasticsearch. It is 7 days by default.
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log.
basicAuth:
enabled: false
username: ""
password: ""
externalElasticsearchHost: ""
externalElasticsearchPort: ""
alerting: # (CPU: 0.1 Core, Memory: 100 MiB) It enables users to customize alerting policies to send messages to receivers in time with different time intervals and alerting levels to choose from.
enabled: true # Enable or disable the KubeSphere Alerting System.
# thanosruler:
# replicas: 1
# resources: {}
auditing: # Provide a security-relevant chronological set of records,recording the sequence of activities happening on the platform, initiated by different tenants.
enabled: true # Enable or disable the KubeSphere Auditing Log System.
# operator:
# resources: {}
# webhook:
# resources: {}
devops: # (CPU: 0.47 Core, Memory: 8.6 G) Provide an out-of-the-box CI/CD system based on Jenkins, and automated workflow tools including Source-to-Image & Binary-to-Image.
enabled: true # Enable or disable the KubeSphere DevOps System.
# resources: {}
jenkinsMemoryLim: 4Gi # Jenkins memory limit.
jenkinsMemoryReq: 2Gi # Jenkins memory request.
jenkinsVolumeSize: 8Gi # Jenkins volume size.
events: # Provide a graphical web console for Kubernetes Events exporting, filtering and alerting in multi-tenant Kubernetes clusters.
enabled: true # Enable or disable the KubeSphere Events System.
# operator:
# resources: {}
# exporter:
# resources: {}
# ruler:
# enabled: true
# replicas: 2
# resources: {}
logging: # (CPU: 57 m, Memory: 2.76 G) Flexible logging functions are provided for log query, collection and management in a unified console. Additional log collectors can be added, such as Elasticsearch, Kafka and Fluentd.
enabled: true # Enable or disable the KubeSphere Logging System.
logsidecar:
enabled: true
replicas: 2
# resources: {}
metrics_server: # (CPU: 56 m, Memory: 44.35 MiB) It enables HPA (Horizontal Pod Autoscaler).
enabled: false # Enable or disable metrics-server.
monitoring:
storageClass: "" # If there is an independent StorageClass you need for Prometheus, you can specify it here. The default StorageClass is used by default.
node_exporter:
port: 9100
# resources: {}
# kube_rbac_proxy:
# resources: {}
# kube_state_metrics:
# resources: {}
# prometheus:
# replicas: 1 # Prometheus replicas are responsible for monitoring different segments of data source and providing high availability.
# volumeSize: 20Gi # Prometheus PVC size.
# resources: {}
# operator:
# resources: {}
# alertmanager:
# replicas: 1 # AlertManager Replicas.
# resources: {}
# notification_manager:
# resources: {}
# operator:
# resources: {}
# proxy:
# resources: {}
gpu: # GPU monitoring-related plug-in installation.
nvidia_dcgm_exporter: # Ensure that gpu resources on your hosts can be used normally, otherwise this plug-in will not work properly.
enabled: false # Check whether the labels on the GPU hosts contain "nvidia.com/gpu.present=true" to ensure that the DCGM pod is scheduled to these nodes.
# resources: {}
multicluster:
clusterRole: none # host | member | none # You can install a solo cluster, or specify it as the Host or Member Cluster.
network:
networkpolicy: # Network policies allow network isolation within the same cluster, which means firewalls can be set up between certain instances (Pods).
# Make sure that the CNI network plugin used by the cluster supports NetworkPolicy. There are a number of CNI network plugins that support NetworkPolicy, including Calico, Cilium, Kube-router, Romana and Weave Net.
enabled: false # Enable or disable network policies.
ippool: # Use Pod IP Pools to manage the Pod network address space. Pods to be created can be assigned IP addresses from a Pod IP Pool.
type: none # Specify "calico" for this field if Calico is used as your CNI plugin. "none" means that Pod IP Pools are disabled.
topology: # Use Service Topology to view Service-to-Service communication based on Weave Scope.
type: none # Specify "weave-scope" for this field to enable Service Topology. "none" means that Service Topology is disabled.
openpitrix: # An App Store that is accessible to all platform tenants. You can use it to manage apps across their entire lifecycle.
store:
enabled: true # Enable or disable the KubeSphere App Store.
servicemesh: # (0.3 Core, 300 MiB) Provide fine-grained traffic management, observability and tracing, and visualized traffic topology.
enabled: true # Base component (pilot). Enable or disable KubeSphere Service Mesh (Istio-based).
istio: # Customizing the istio installation configuration, refer to https://istio.io/latest/docs/setup/additional-setup/customize-installation/
components:
ingressGateways:
- name: istio-ingressgateway
enabled: true
cni:
enabled: true
edgeruntime: # Add edge nodes to your cluster and deploy workloads on edge nodes.
enabled: false
kubeedge: # kubeedge configurations
enabled: false
cloudCore:
cloudHub:
advertiseAddress: # At least a public IP address or an IP address which can be accessed by edge nodes must be provided.
- "" # Note that once KubeEdge is enabled, CloudCore will malfunction if the address is not provided.
service:
cloudhubNodePort: "30000"
cloudhubQuicNodePort: "30001"
cloudhubHttpsNodePort: "30002"
cloudstreamNodePort: "30003"
tunnelNodePort: "30004"
# resources: {}
# hostNetWork: false
iptables-manager:
enabled: true
mode: "external"
# resources: {}
# edgeService:
# resources: {}
gatekeeper: # Provide admission policy and rule management, A validating (mutating TBA) webhook that enforces CRD-based policies executed by Open Policy Agent.
enabled: false # Enable or disable Gatekeeper.
# controller_manager:
# resources: {}
# audit:
# resources: {}
terminal:
# image: 'alpine:3.15' # There must be an nsenter program in the image
查看部署日志:
[root@centos1 ~]# k logs -n kubesphere-system ks-installer-85dcff96b4-7qpl5 -f
末尾输出如下:
Collecting installation results ...
#####################################################
### Welcome to KubeSphere! ###
#####################################################
Console: http://192.168.123.12:30880
Account: admin
Password: P@88w0rd
NOTES:
1. After you log into the console, please check the
monitoring status of service components in
"Cluster Management". If any service is not
ready, please wait patiently until all components
are up and running.
2. Please change the default password after login.
#####################################################
https://kubesphere.io 2023-06-30 18:35:27
#####################################################
最终安装完成后的web界面:


两个web界面的初始密码都是P@88w0rd,账号统一为admin文章来源:https://www.toymoban.com/news/detail-520144.html
离线部署kubesphere完成!!!!!!!!!!!文章来源地址https://www.toymoban.com/news/detail-520144.html
到了这里,关于云原生|kubernetes|centos7下离线化部署kubesphere-3.3.2---基于kubernetes-1.22.16(从网络插件开始记录)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!