一、双向链表

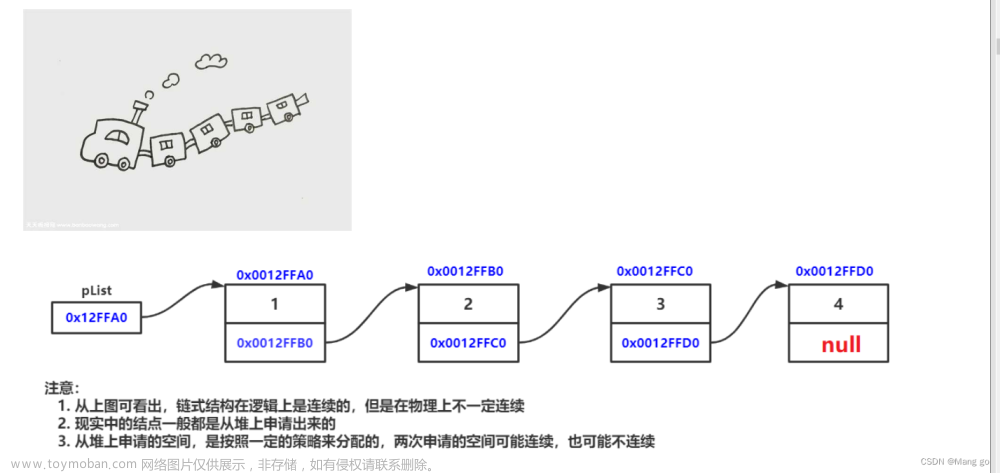
🎁 单链表的节点中只有一个 next 指针引用着下一个节点的地址
🎁 当要获取单链表中的最后一个元素的时候,需要从头节点开始遍历到最后
🎁 单链表一开始的时候有 first 头指针引用着头节点的地址
💰 双向链表可以提升链表的综合性能
💰 双向链表的节点中有 prev 指针引用着上一个节点的地址,有 next 指针引用着下一个节点的地址
💰 双向链表中一开始的时候有 first 头指针引用着头节点的地址,有 last 尾指针引用着尾节点的地址
💰 ① 当需要获取双向链表靠后的节点【index >= (size / 2)】的时候从尾节点开始遍历;② 当需要获取双向链表靠前的节点【index < (size / 2)】的时候从头节点开始遍历
🎄 头节点的 prev 为 null
🎄 尾节点的 next 为 null
二、node(int index) 根据索引找节点
/**
* 根据索引找节点
*/
private Node<E> node(int index) {
rangeCheck(index);
if (index < (index >> 1)) { // 找左边的节点
Node<E> node = first;
for (int i = 0; i < index; i++) {
node = node.next;
}
return node;
} else {
Node<E> node = last;
for (int i = size - 1; i > index; i--) {
node = node.prev;
}
return node;
}
}
三、clear()
@Override
public void clear() {
size = 0;
first = null;
last = null;
}
只有被【gc root 对象】引用的对象才不会被垃圾回收器回收:
🍃 被栈指针(局部变量)引用的对象是 gc root 对象

四、add(int, E)

🎄 ① 当往索引 0 处插入节点的时候
🎄 ② 当往最后插入节点的时候
🎄 ③ 当一个节点都没有(插入第一个节点)的时候


@Override
public void add(int index, E element) {
rangeCheck4Add(index);
if (size == 0 || (first == null && last == null)) { // 添加第一个节点
// 新节点的 prev 和 next 都指向 null
first = new Node<>(element, null, null);
// 头指针和尾指针都指向新节点
last = first;
} else {
if (index == size) { // 往最后插入新节点
Node<E> oldLast = last;
last = new Node<>(element, oldLast, null);
oldLast.next = last;
} else {
// 找到 index 索引处的节点(该节点是新节点的下一个节点)
Node<E> next = node(index);
// 前一个节点(假如是往索引为 0 的位置插入节点的话, prev 是 null)
Node<E> prev = next.prev;
// 新节点的 prev 指向【前一个节点】
// 新节点的 next 指向【后一个节点】
Node<E> newNode = new Node<>(element, prev, next);
// 后一个节点的 prev 指向新节点
next.prev = newNode;
/* 往索引为 0 处插入新节点 */
if (prev == null) { // 往索引为 0 的位置插入新节点(插入新节点到头节点的位置)
first = newNode; // 头指针指向新节点
} else {
// 前一个节点的 next 指向新节点
prev.next = newNode;
}
}
}
size++;
}

五、remove(int index)

自己写的代码(测试成功的):
@Override
public E remove(int index) {
rangeCheck(index);
// 拿到 index 位置的节点
Node<E> oldNode = node(index);
if (index == 0) { // 删除头节点
// 拿到头节点
first = oldNode.next;
first.prev = null;
} else {
oldNode.prev.next = oldNode.next;
if (oldNode.next == null) { // 删除尾节点
last = oldNode.prev;
} else {
oldNode.next.prev = oldNode.prev;
}
}
size--;
return oldNode.element;
}
老师的代码:
@Override
public E remove(int index) {
rangeCheck(index);
Node<E> node = node(index);
Node<E> prev = node.prev;
Node<E> next = node.next;
if (prev == null) { // 删除头节点
first = next;
} else {
prev.next = next;
}
if (next == null) { // 删除尾节点
last = prev;
} else {
next.prev = prev;
}
size--;
return node.element;
}

六、双向链表和单链表

🎉 双向链表相比单向链表操作数量缩减一半
七、双向链表和动态数组
🌱 动态数组:开辟、销毁内存空间的次数相对较少但可能造成内存空间浪费(可以通过缩容解决)
🌱 双向链表:开辟、销毁内存空间的次数相对较多(每次添加元素都会创建新的内存空间 ),但不会造成内存空间的浪费
🌿 如果需要频繁在尾部进行添加、删除操作,动态数组、双向链表 均可选择
- 动态数组在尾部添加和删除都是
O(1)级别的- 双向链表由于有尾指针
last的存在,在尾部添加和删除的操作也是O(1)级别的
🌿 如果需要频繁在头部进行添加、删除操作,建议选择使用 双向链表
- 动态数组头部的添加和删除操作需要进行大量的元素挪动
- 双向链表有头指针
first的存在,在头部进行添加、删除操作效率很高
🌿 如果需要频繁地(在任意位置)进行添加、删除操作,建议选择使用双向链表
- 动态数组有最坏情况(假如是在头部添加或删除几乎需要挪动全部元素)
- 双向链表最多就遍历
n/2次(n 是元素数量)
🌿 如果有频繁的查询操作(随机访问操作),建议选择使用动态数组
- 动态数组的随机访问是
O(1)级别的,通过下标 index 可以直接定位到元素的内存地址- 双向链表每次查询都需要遍历,最坏情况要遍历 size 次(size 是元素个数)
❓ 相比单链表,双向链表效率很高。哪有了双向链表,单向链表是否就没有任何用处了呢 ❓
🌿 哈希表的设计中就用到了单链表 😀
八、jdk 官方的 LinkedList 的 clear() 方法
 文章来源:https://www.toymoban.com/news/detail-520570.html
文章来源:https://www.toymoban.com/news/detail-520570.html
- 我学习数据结构与算法的全部代码:https://gitee.com/zgq666good/datastructureandalgorithm.git
- 学习资料来自于我偶像 ~ 李明杰(小码哥教育)
🌿如有错误,请不吝赐教🌿文章来源地址https://www.toymoban.com/news/detail-520570.html
到了这里,关于【数据结构与算法】4、双向链表(学习 jdk 的 LinkedList 部分源码)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!