1.构建搜索引擎系统
下图中描述的体系结构包括三个部分:结合本体库的网络爬虫,索引及检索模块以及知识图谱模块。其中爬虫及索引模块主要负责从网络中爬取原始数据并通过解析得到实体相关信息以及建立索引;搜索模块结合本体库Query解析检索语句得到搜索关键词,通过检索器得到结果并返回用户;知识图谱模块首先根据爬虫获取的实体,通过实体知识融合以及实体对齐获取所有实体,并利用实体之间的语义关系构成知识图谱,知识图谱完成检索器的信息请求并通过对检索结果进行分析,推荐相关信息并给出最终的排序结果。
2.构建智能问答系统
在搭建系统之前,第一步的任务是准备数据。
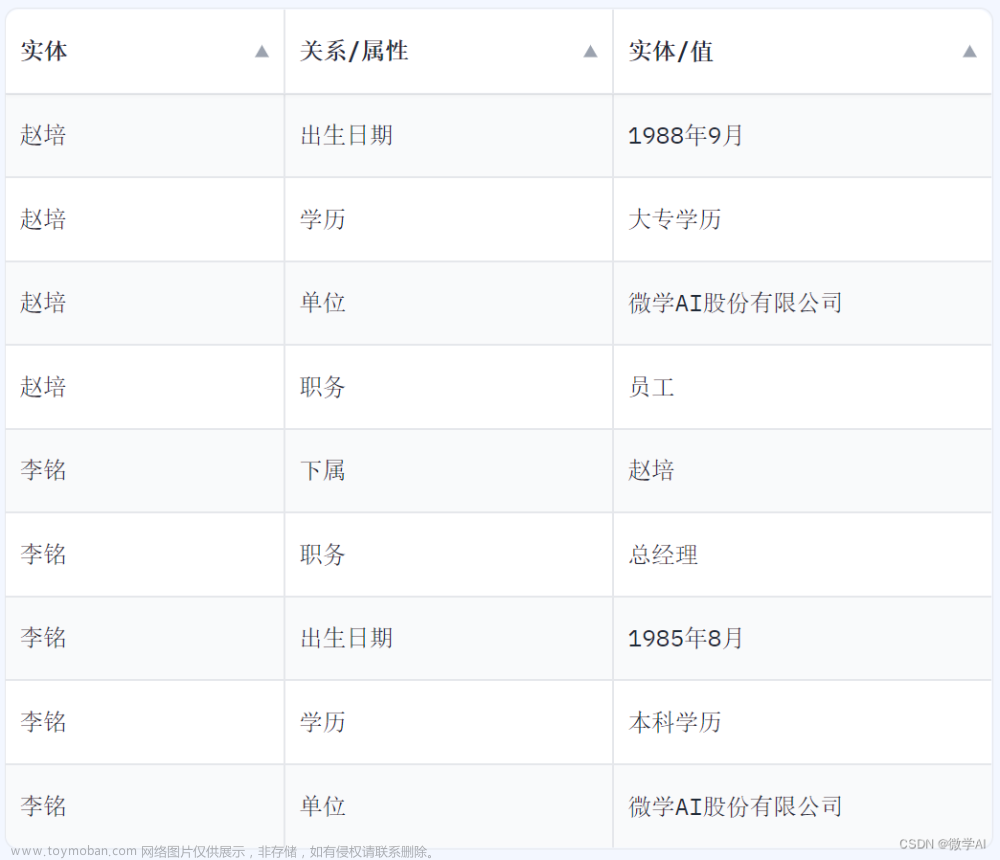
准备好数据之后,将数据整理成RDF文档的格式。比如采用手工的方式在protégé中构建本体以及知识图谱。本体作为模式层,声明n个类;声明了n种关系,也叫objectProperty;声明了n种数据属性,也叫DataProperty。将上述准备好的数据以individual和dataProperty的形式写进知识图谱。至此,就准备好了我们的RDF/OWL文件了。
接着,为了使用RDF查询语言SPARQL做后续的查询操作,使用Apache Jena的TDB和Fuseki组件。TDB是Jena用于存储RDF的组件,是属于存储层面的技术。Fuseki是Jena提供的SPARQL服务器,也就是SPARQL endpoint。这一步中,首先利用Jena将RDF文件转换为tdb数据。接着对fuseki进行配置并打开SPARQL服务器,就可以通过查询语句完成对知识图谱的查询。
最后,将自然语言问题转换成SPARQL查询语句。首先使用结巴分词将自然语言问题进行分词以及词性标注。对于不同类型的问题,我们将问题匹配给不同的查询语句生成函数从而得到正确的查询语句。将查询语句作为请求参数和Fuseki服务器通信就能得到相应的问题结果。上述工作流程图如图所示。 文章来源:https://www.toymoban.com/news/detail-520666.html
文章来源:https://www.toymoban.com/news/detail-520666.html
3.构建智能推荐系统
基于知识图谱的推荐系统主要是利用知识图谱对多源异构数据的整合性,可以对大数据环境下互联网上的数据进行知识抽取,得到更加细粒度的用户和项目的特征信息,从而更精准的计算用户与用户、用户与项目以及项目与项目之间的相关性,最后为用户做出推荐。
该推荐有3个组成要素:用户知识图谱、项目知识图谱、推荐方法。在此基础上,给出基于知识图谱的一个推荐系统模型,如图所示。该模型分为客户端和服务器端,客户端收集用户的原始数据(包括浏览数据、上下文数据如时间、用户状态等)上传至服务器端进行处理。服务器端一方面从各个垂直网站及百科网站中进行相关数据搜集,构建项目知识图谱;另一方面,对用户偏好进行获取,建立用户知识图谱;此外,通过分析推理的方法获取上下文信息,利用GPS定位来获取当前用户地理位置信息等。最后,综合上述信息,通过推荐产生器向目标用户推送其感兴趣的项目,并基于用户反馈对推荐性能进行评估,进一步调整推荐产生器,以适应用户偏好。 文章来源地址https://www.toymoban.com/news/detail-520666.html
文章来源地址https://www.toymoban.com/news/detail-520666.html
到了这里,关于如何基于知识图谱技术构建现代搜索引擎系统、智能问答系统、智能推荐系统?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!