对比loss
对比学习的 loss(InfoNCE)即以最 大化互信息为目标推导而来。其核心是通过计算样本表示间的距离,拉近正样本, 拉远负样本,因而训练得到的模型能够区分正负例。
具体做法为:对一个 batch 输入的图片,随机用不同的数据增强方法生成两个 view,对他们用相同的网络 结构进行特征提取,得到 y 和 y’,来自同一张图像的两个不同的表示构成一对正样本对,来自不同图像任意表示对为一对负样本对。随后对上下两批表示两两计算 cosine similarity,得到 N*N 的矩阵,每一行的对角线位置代表 y 和 y’的相似 度,其余代表 y 和 N-1 个负样本对的相似度。计算公式如下(T 为超参):

MOCO(memory bank)
MOCO 的一个核心观点是,样本数量对于对比学习很重要。从 InfoNCE loss 我们可以看出,增加负例的数量可以防止过拟合,与此同时,负例越多,这个任务的难度就越大,因而通过增加负例的方式可作为一个优化方向。但是纯粹的增加 batch size 会使得 GPU 超负荷。一个可行的方法就是增加 memory bank,把之前编码好的样本存储起来,计算 loss 的时候随机采样负例。但是这样会存在一个问题,就是存储好的编码都是之前编码计算的,而 Xq 经过误差回传后一直在更新,样本缺乏一致性,影响目标优化。因而在此基础上 Moco 提出了一种动量对比 (Mometum contrast) 的方法提高每个 mini-batch 的负样本数量。
MOCO的改进方法:动量更新,主要是为了解决引入队列维护字典之后,字典的编码器无法通过梯度反传获得参数更新的问题。
Moco就提出Momentum Contrast的方法解决Memory Bank的缺点,该方法使用一个队列来存储和采样 negative 样本,队列中存储多个近期用于训练的 batch 的特征向量。队列容量要远小于 Memory Bank,但可以远大于 batch 的容量,如下图所示。这里momentum encoder可以和encoder完全一致参与梯度下降,也可以是对query encoder的平滑拷贝。
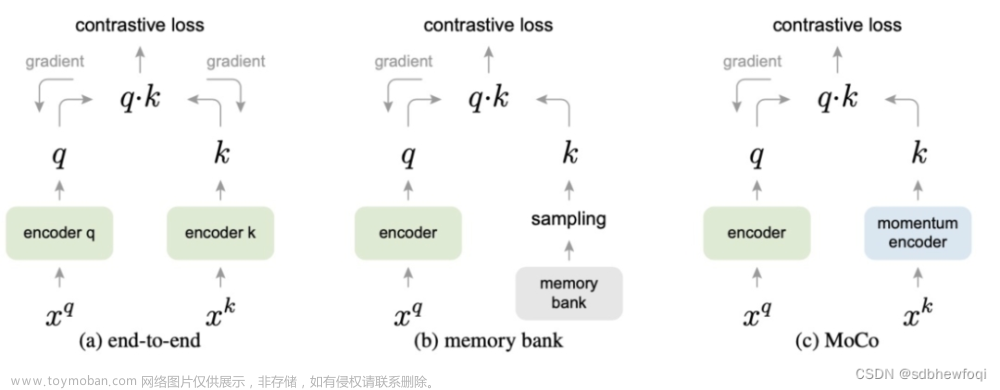
我的疑问:这样还有类似于memory bank的负采样吗?如果没有,那么bacthsize岂不是还是不能增大?这只是解决了encoder同步更新的问题。-----》以上下划线
SimCLR
在 encoder 之后增加了一个非线性映射。研究发现 encoder 编码后的 h 会保留和数据增强变换相关的信息,而非线性层的作用就是去掉这些信息,让表示回归数据的本质。
自监督学习速览 - 搬砖啦姜姜的文章 - 知乎文章来源:https://www.toymoban.com/news/detail-521114.html
经典论文学习笔记——13篇对比学习(Contrastive Learning)文章来源地址https://www.toymoban.com/news/detail-521114.html
到了这里,关于【计算机视觉】对比学习综述(自己的一些理解)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![深度学习进阶篇[9]:对抗生成网络GANs综述、代表变体模型、训练策略、GAN在计算机视觉应用和常见数据集介绍,以及前沿问题解决](https://imgs.yssmx.com/Uploads/2024/02/717842-1.png)
![深度学习应用篇-计算机视觉-语义分割综述[5]:FCN、SegNet、Deeplab等分割算法、常用二维三维半立体数据集汇总、前景展望等](https://imgs.yssmx.com/Uploads/2024/02/567599-1.png)
![深度学习应用篇-计算机视觉-OCR光学字符识别[7]:OCR综述、常用CRNN识别方法、DBNet、CTPN检测方法等、评估指标、应用场景](https://imgs.yssmx.com/Uploads/2024/02/705153-1.png)







