(单选30 判断10 简答10 操作30 编程20)
编程掌握:
HDFS文件操作
MapReduce程序
HBase数据库命令操作
U1
大数据的4v特征
数据量大、处理快、数据类型多、价值密度低
大数据完全颠覆了传统的思维方式:
全样而非抽样、
效率而非精确、
相关而非因果
第三次信息化浪潮:云计算,物联网和大数据
大数据的两大核心技术
分布式存储:GFS/HDFS、BigTable/HBase、NoSQL
分布式处理:MapReduce
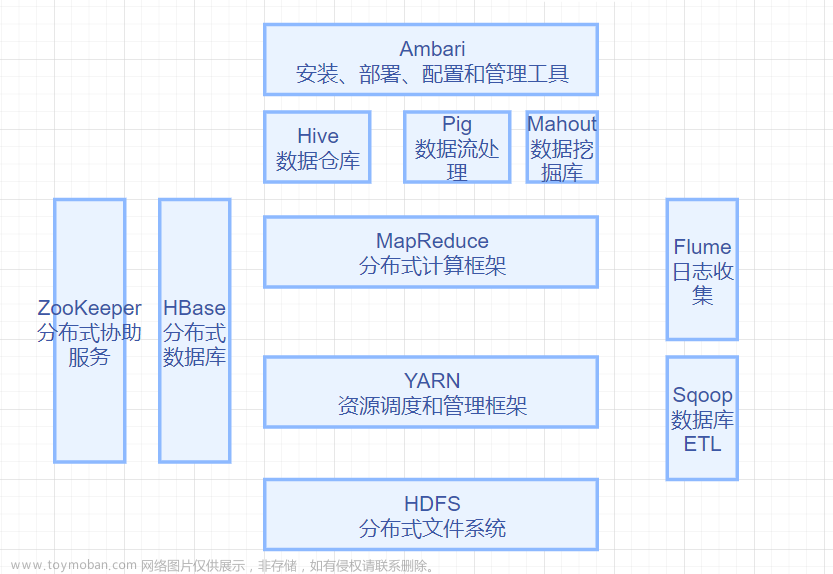
Hadoop相关组件
MapReduce:分布式并行编程模型
HBase:非关系型分布式数据库
YARN:资源管理调度器
Hive:数据仓库
Pig:语言+环境
Sqoop:数据传输
Zookeeper:协同工作系统,提供协调一致服务
Flume:日志系统
Storm:流计算框架
Tez:支持DAG作业的计算框架
Spark:通用并行框架
Kafka:分布式发布订阅消息系统
==批处理计算:MapReduce、Spark==
查询分析计算:Dremel、Hive
流计算:Storm、Flume
Apache最重要的三大分布式计算系统开源项目包括(ABC)
A. Hadoop
B. Storm
C. Spark
U2 Hadoop
Hadoop是开源分布式平台,具有很好的跨平台性
核心是HDFS(Hadoop Distributed File System)和MapReduce
Hadoop的特性:
高可靠性、高效性、高可扩展性、高容错性、成本低、运行在LinuxOS、支持多种编程语言
Hadoop1.0/2.0
两代比较:
1.0:单一NameNode存在单点故障问题
2.0:HDFS HA,提供NameNode热备份机制
HA集群设置两个名称节点,“==活跃==(Active)”和“==待命==(Standby)”,两种名称节点的状态同步
1.0:无法实现资源隔离
2.0:HDFS Federetion 管理多个命名空间
Federation中,设计了多个相互独立的NameNode,相互之间是联盟关系,不需要彼此协调。
Federation中,所有NameNode会共享底层的DataNode存储资源,DataNode向所有NameNode汇报。
Federation并不能解决单点故障问题,需要为每个NameNode部署一个后备NameNode
属于同一个命名空间的块构成一个“块池
1.0:资源管理效率低
2.0:资源管理框架YARN
MapReduce1.0中的资源管理调度功能被单独分离出来形成了YARN,是一个纯粹的资源调度框架
U3 HDFS
廉价兼容的硬件、流数据集、
简单文件模型:'==一次写入、多次读取==',且仅能写入一次,仅允许追加
跨平台:支持JVM的都可以运行
无法高效存储大量小文件
不支持多用户写入及任意修改文件
不适合低延迟数据访问
一个磁盘块512字节,是文件读写的最小单位
文件以块(Block)为单位进行存储,块通常是磁盘块的整数倍
HDFS默认一个块64MB
不同的文件块可以被分发到不同的节点上
块概念的优点:
支持大规模文件存储
简化系统设计
适合数据备份
主节点(Master Node)也叫NameNode
NameNode作为中心服务器,管理NameSpace及Client文件访问
负责文件和目录的操作,管理DataNode和文件块的映射关系,Client只有访问NameNode才能找到Block位置
从节点(Slave Node)也叫DataNode
DataNode负责数据存取、处理客户端请求
NameNode分配存储位置,Client将数据直接写入DataNode
一个HDFS包括唯一NameNode和若干个DataNode
NameNode :存储元数据、保存在内存
DataNode:存储文件内容、保存在磁盘
JobTracker:协调数据计算任务
TaskTracker:负责执行由JobTracker指派的任务
SecondaryNameNode:
完成Editlog和FsImage合并操作,减小Editlog文件大小
减少NameNode重启时间
作为NameNode检查点,保存NameNode中对HDFS元数据的备份
一般是单独运行在一台机器上
NameNode
负责管理HDFS的命名空间(Namespace),保存了两个核心的数据结构:FsImage,EditLog
NameNode记录了每个文件中各个块所在的DataNode的位置信息
FsImage用于维护文件树以及所有的文件元数据。由NameNode把文件块的映射信息保存在内存中
FsImage 文件没有记录文件包含哪些块以及每个块存储在哪个数据节点。 而是由NameNode把这些映射信息保留在内存中
操作日志文件EditLog中记录了所有文件操作。
DataNode
HDFS的工作节点,负责数据存取
向NameNode定期发送自己所存储的块的列表
数据保存在各自节点的本地Linux文件系统中
客户端
用户操作 HDFS 最常用的方式,HDFS 在部署时都提供了客户端
HDFS 客户端是一个库,暴露了 HDFS 文件系统接口
严格来说,客户端并不算是 HDFS 的一部分
HDFS命名空间
包含目录、文件、块
一个HDFS只有一个NameSpace
NameNode和DataNode之间则使用DataNode协议进行交互。
客户端与DataNode的交互通过RPC
唯一的NameNode局限性:
命名空间限制
性能瓶颈
隔离问题
集群可用性
冗余存储:多副本
加快传输速度
容易检查错误
可靠性
数据存放:以机架Rack为基础
HDFS默认一个文件块保存3个副本
数据复制:流水线复制
HDFS 具有较高的容错性:
NameNode出错
DataNode出错
数据出错
HDFS常用命令
三种Shell命令方式:
hadoop fs:适用于任何文件系统
hadoop/hdfs dfs:只适用于HDFS文件系统
#启动
start-dfs.sh
#创建用户目录
–mkdir –p /user/hadoop
#列出根目录中的内容
–ls
#递归列出多层文件夹的内容
-ls -R
#显示目录信息
-ls /sanguo
#统计/test/kb16/hadoop/下文件大小
-du /test/hadoop/
#输出文件内容
-cat /sanguo/shuguo.txt
#输出文件的末尾1kb的内容
-tail /jinguo/shuguo.txt
#创建一个input目录
–mkdir -p input
#根目录下创建一个名称为input的目录
–mkdir -p /input
# 删除指定文件
-rm /sa/guo.txt
# 递归删除文件夹及其下所有文件
-rm -r /
#将文件输出为文本格式
-text /
#将一个或多个源文件复制到HDFS文件系统中目标位置
-cp
#移动指定源文件到目标文件
-mv
#显示占用存储空间的大小
-du
#moveFromLocal命令支持从本地将文件移动到HDFS中, moveToLocal命令则相反。代码
向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class HDFSApi {
/**
* 判断路径是否存在
*/
public static boolean test(Configuration conf, String path) throws IOException {
FileSystem fs = FileSystem.get(conf);
return fs.exists(new Path(path));
}
public static void copyFromLocalFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path localPath = new Path(localFilePath);
Path remotePath = new Path(remoteFilePath);
/* fs.copyFromLocalFile 第一个参数表示是否删除源文件,第二个参数表示是否覆盖 */
fs.copyFromLocalFile(false, true, localPath, remotePath);
fs.close();
}
public static void appendToFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
/* 创建一个文件读入流 */
FileInputStream in = new FileInputStream(localFilePath);
/* 创建一个文件输出流,输出的内容将追加到文件末尾 */
FSDataOutputStream out = fs.append(remotePath);
/* 读写文件内容 */
byte[] data = new byte[1024];
int read = -1;
while ((read = in.read(data)) > 0){
out.write(data, 0, read);
}
out.close();
in.close();
fs.close();
}
/**
* 主函数
*/
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
String localFilePath = "/home/hadoop/text.txt"; // 本地路径
String remoteFilePath = "/user/hadoop/text.txt"; // HDFS路径
U4 Hbase
HBase是一个稀疏、多维度、排序的映射表,这张表的索引是四维的:
行键(row key)、列族(column family)、**列限定符(定位)、时间戳(版本)
可伸缩分布式数据库,BigTable的开源实现
![[Pasted image 20220616112428.png]]
![[Pasted image 20220616113211.png]]
数据是未经解释的字符串,没有数据类型。
HBase操作则不存在表与表之间的关系
HBase面向列存储,每个列族都由几个文件保存,不同列族的文件是分离的,一个列族中有若干个列
HBase只有一个索引——行键
HBase并不会删除数据旧的版本(匹配HDFS只能追加不能修改)
三个主要的功能组件:
库函数:链接到每个客户端
一个Master主服务器:负责表和Region管理
许多个Region服务器:负责存储和维护分配给自己的Region,处理来自客户端的读写请求
同一个Region不会被分拆到多个Region服务器
每个Region的建议最佳大小1GB-2GB
客户端
客户端使用Hbase的RPC机制与服务器进行通信
客户端在获得Region的存储位置信息后,直接从Region服务器上读取数据
客户端只通过Zookeeper来获得Region位置信息,这种设计方式使得Master负载很小
Zookeeper服务器
多台机器组成集群提供协同服务,帮助选举出一个Master作为集群的总管,且保证有且只有一个Master在运行,避免单点失效问题
Region服务器是HBase最核心的模块
Store是Region的核心
每个Store对应一个列族的存储,包含一个MemStore缓存和若干个StoreFile文件
数量达到一定值,多个StoreFile合并为一个
单个StoreFile过大时一个Region分裂为两个
三层结构->三级寻址
客户端通过三级寻址定位Region
**(简记:ZRM)
Zookeeper文件 -> -ROOT-表 -> .META.表
Hlog:预写式日志
每个Region只维护一个Hlog文件,所有Region对象公用一个Hlog。
HBase常用命令
进入:
hbase shell
create 'a_stu','name','score'
//创建a_stu表,两个列
//put ‘表名’,‘行键’,‘列族名:列名’,‘值’[,时间戳]
put't1','row1','f1:c1','value1',14218
//由id插入math成绩
put 'a_stu','20181228','score:math','95'
scan 'a_stu'//查看表
count 'a_stu'//统计表行数
//查询
get 'a_stu','20181228','name','score'
get't1','r1',{COLUMN=>'c1',TIMERANGE=>[ts1,ts2],VERSION=>4}
//查看表相关信息
describe 't1'
//删除制定元素:表、行、列、时间戳为ts1
delete 't1','r1','c1',ts1
//删除整行
deleteall 'a_stu','20181228'
//删除表数据(表还在)
truncate 'a_stu'
#一次只能put/delete一个column,删除整行用deleteall
disable 'a_stu'//先disable再drop
drop 'a_stu'//删除表
exists 'a_stu'//查看是否存在
//如果列族下没有子列,则只加“:”即可
put'scores','Jim','course:Chinese','90'
put'scores,'Tom','grade:','2'
get 'scores','Jim','course:math'
list//列出 所有的表
//制定分割点
create 't1','f1',{SPLITS=>'10','20'}
//浏览指定数据
scan 't1',{COLUMN=>'c1',TIMERANGE=>[201801,201809]}
//扫描前5条
scan 't1',{LIMIT=>5}
//向表t1中添加列族f1
alter 't1',Name=>'f1'
//删除列族
alter 't1',{NAME=>'f1',METHOD=>'delete'}NoSQL
(1)灵活的可扩展性
(2)灵活的数据模型
(3)与云计算紧密融合
与关系数据库相比,NoSQL:
缺乏统一的查询语言、统一的理论基础
弱一致性
很难实现数据完整性
支持超大规模数据存储,具有强大的横向扩展能力
四大类型:
键值数据库:
一个哈希表,表中有一个特定的Key 和一个指针指向特定的 Value,Key 可以用来定位 Value,即存储和检索具体的 Value。
列族数据库:一般采用列族数据模型,数据库由多个行构成,每行数据包含多个列族,不同的行可以具有不同数量的列族,属于同一列族的数据会被存放在一起。
文档数据库:以文档作为最小单位,大都假定文档以某种标准化格式封装并对数据进行加密,同时用多种格式进行解码。
图数据库:图作为数据模型来存储数据
CAP理论
C(Consistency)一致性
A(Availability)可用性
指能够快速获取数据,且在确定的时间内返回操作结果。
P(Tolerance of Network Partition)分区容忍性
指当出现网络分区的情况时,分离的系统也能正常运行。
事务ACID 四性:
A(Atomicity):原子性
指事务对于其数据修改,要么全都执行,要么全都不执行。
C(Consistency):一致性
指事务在完成时,必须使所有的数据都保持一致状态。
I(Isolation):隔离性
指并发事务所做的修改必须与其他并发事务所做的修改分离开。
D(Durability):持久性
指事务完成之后,它对于系统的影响是永久性的。
BASE:
基本可用 Basiclly Available,
软状态 Soft-state,
最终一致性 Eventual consistency
MapReduce
分而治之、计算向数据靠拢
分布式并行编程模型MapReduce特点:
![[Pasted image 20220630103124.png]]
MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。
Master上运行JobTracker
Slave上运行TaskTracker
并行计算过程抽象到两个函数:
Map函数
输入为分布式文件系统的文件块,格式是任意的。
Map 函数将输入的元素转换成 <key, value> 形式的键值对,键和值的类型也是任意的。一个Map任务可生成具有相同键的多个<key, value> 。
Reduce函数
将输入的一系列具有相同键的键值对以某种方式组合起来,输出处理后的键值对,输出结果合并成一个文件。
Map每一个输入的<k 1 ,v 1 >会输出一批<k 2 ,v 2 >。<k 2 ,v 2 >是计算的中间结果
Reduce输入的中间结果<k 2 ,List(v 2 )>中的List(v 2 )表示是一批属于同一个k 2 的value
输入形式为<k, List(v)>,输出为<k,v1>。
MapReduce体系结构由四个部分组成:
Client:用户程序通过Client提交到JobTracker
JobTracker :负责资源监控和作业调度。
监控所有TaskTracker与Job的健康状况
跟踪任务的执行进度、资源使用量等信息
TaskTracker:
周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作
使用slot等量划分本节点上的资源量(CPU、内存等)
slot 分为Map slot 和Reduce slot
Task :分为Map Task 和Reduce Task 两种,均由TaskTracker 启动
MapReduce工作流程
不同的Map任务/Reduce任务之间不会进行通信。
用户不能显式地从一台机器向另一台机器发送消息。
所有的数据交换都是通过MapReduce框架自身实现
MapReduce的处理单位是split
split 是一个逻辑概念,只包含一些元数据信息,它的划分方法完全由用户自己决定。
Hadoop为每个split创建一个Map任务,split 的多少决定了Map任务的数目。理想的分片大小是一个HDFS块。
最优的Reduce任务个数取决于slot的数目
代码
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf);
job.setJarByClass(Test.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}Spark
特点:
运行速度快、容易使用、通用性、运行模式多样
Spark的计算模式也属于MapReduce
Scala是Spark的主要编程语言,但Spark还支持其他语言。
Scala:一种多范式编程语言
运行于Java平台,兼容Java程序。
并发性
RDD:弹性分布式数据集
特点
容错性
中间结果持久化到内存
存放的数据可以是Java对象
RDD操作分为
转换(Transformation):map groupBy filter
动作(Action): count
RDD之间的依赖关系
窄依赖:一个父的一个分区对应于一个子的分区或多个父的分区对应于一个子的分区。
宽依赖:一个父的一个分区对应一个子多个分区。文章来源:https://www.toymoban.com/news/detail-521321.html
DAG:有向无环图,反映RDD之间的依赖关系文章来源地址https://www.toymoban.com/news/detail-521321.html
到了这里,关于大数据技术原理与应用(第3版)期末复习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!