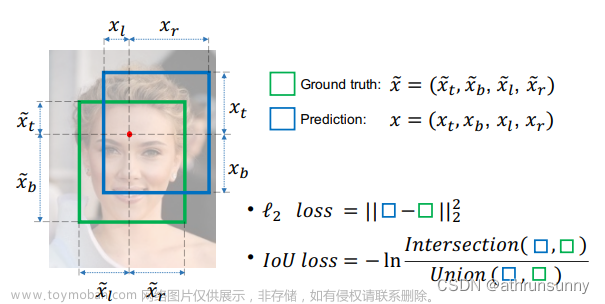
一、引言
本文通过估计锚框的离群度定义一个动态聚焦机制(FM) f(β),β =
L
I
o
U
L
I
o
U
\frac{L_{IoU}}{L_{IoU}}
LIoULIoU。FM通过将小梯度增益分配到具有小β的高质量锚框,使锚框回归能够专注于普通质量的锚框。
同时,该机制将小梯度增益分配给β较大的低质量锚箱,有效削弱了低质量样例对锚框回归的危害。
作者将这种操作称之为明智的IOU(WIoU)。
二、实现细节
由于训练数据不可避免地包含低质量的例子,距离、横纵比等几何因素会加重低质量例子的惩罚,从而降低模型的泛化性能。一个好的损失函数应该在锚盒与目标盒重合良好时弱化几何因素的惩罚,训练中较少的干预会使模型获得更好的泛化能力。在此基础上构建距离注意力,得到具有两层注意机制的WIoU v1:
R
W
I
o
U
∈
[
1
,
e
)
R_{WIoU}∈[1,e)
RWIoU∈[1,e),这将显著放大普通质量锚框的
L
I
o
U
L_{IoU}
LIoU。
L
I
o
U
∈
[
0
,
1
]
L_{IoU}∈[0,1]
LIoU∈[0,1],这将显著降低高质量锚框的
R
W
I
o
U
R_{WIoU}
RWIoU,并在锚框与目标框重合良好时,将焦点集中在中心点之间的距离上。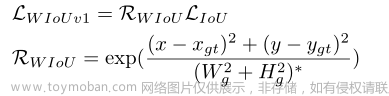
其中
W
g
W_g
Wg,
H
g
H_g
Hg是最小的包围框的大小。为了防止
R
W
I
o
U
R_{WIoU}
RWIoU产生阻碍收敛的梯度,
W
g
,
H
g
W_g, H_g
Wg,Hg从计算图中分离(上标*表示此操作)。因为它有效地消除了阻碍收敛的因素,所以没有引入诸如长宽比之类的新指标。
在现有工作中提到的一系列锚框回归损失中,SIoU收敛速度最快。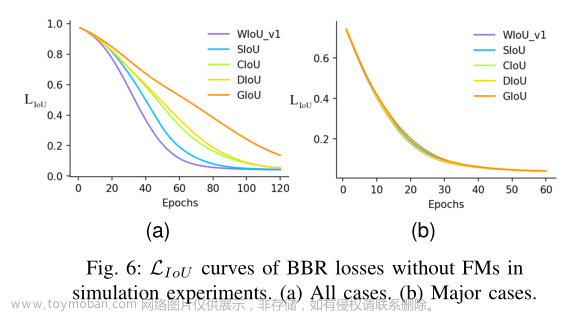
对于锚框回归中的主要情况,所有锚框回归损失都具有极其相似的收敛速率。由此可见,收敛速度的差异主要来自于不重叠的边界框。本文提出的基于注意的WIoU v1在这部分有最好的效果。
从焦点损失中学习:为交叉熵设计了一个单调FM,有效地降低了简单示例对损失值的贡献。因此,该模型可以专注于硬例,并获得分类性能的提高。类似地,本文构造
L
W
I
o
U
v
1
L_{WIoUv1}
LWIoUv1的单调聚焦系数
L
I
o
U
γ
∗
L^{γ *}_{IoU}
LIoUγ∗。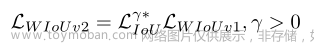
由于聚焦系数的加入,WIoU v2反向传播的梯度也发生了变化: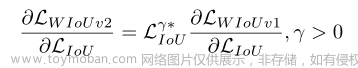
注意,梯度增益为
r
=
L
I
o
U
γ
∗
∈
[
0
,
1
]
r = L^{γ *}_{IoU}∈[0,1]
r=LIoUγ∗∈[0,1]。在模型训练过程中,梯度增益随着
L
I
o
U
L_{IoU}
LIoU的减小而减小,导致训练后期收敛速度较慢。因此,引入
L
I
o
U
L_{IoU}
LIoU的均值作为归一化因子: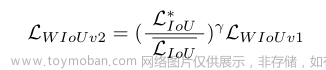
其中,
L
I
o
U
L_{IoU}
LIoU是动量为m的运行均值。动态更新归一化因子使梯度增益
r
=
(
L
I
o
U
∗
L
I
o
U
)
γ
r = (\frac{L^∗_{IoU}}{ L_{IoU}})^γ
r=(LIoULIoU∗)γ总体上处于较高的水平,解决了训练后期收敛缓慢的问题。
动态非单调FM:锚框的离群度由
L
I
o
U
L_{IoU}
LIoU与
L
I
o
U
L_{IoU}
LIoU的比值表征: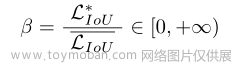
离群度小意味着锚盒质量高。给它分配一个小的梯度增益,以便将BBR集中在普通质量的锚盒上。此外,将较小的梯度增益分配给具有较大离群度的锚框将有效地防止较大的有害梯度。利用β构造了一个非单调聚焦系数,并将其应用于WIoU v1: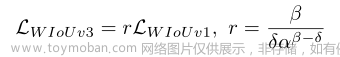
当
β
=
δ
β = δ
β=δ时,
δ
δ
δ使r = 1。如图8所示,锚框的离群度满足β = C (C为常值)时,其梯度增益最大。由于
L
I
o
U
L_{IoU}
LIoU是动态的,锚框的质量划分标准也是动态的,这使得WIoU v3可以在每一个时刻做出最符合当前情况的梯度增益分配策略。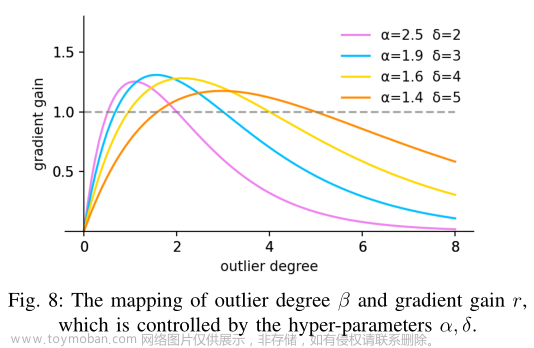
为了防止低质量的锚框在训练早期被落下,初始化
L
I
o
U
=
1
L_{IoU} = 1
LIoU=1,使
L
I
o
U
L_{IoU}
LIoU = 1的锚框获得最高的梯度增益。为了在训练的早期阶段保持这样的策略,需要设置一个小动量m来延迟
L
I
o
U
L_{IoU}
LIoU接近真实值的时间。对于数据批次数为n的训练,我们建议将动量设为: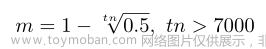
这个设置使得训练t周期后的
L
I
o
U
=
0.5
(
1
+
L
I
o
U
−
r
e
a
l
)
L_{IoU} = 0.5(1 + L_{IoU−real})
LIoU=0.5(1+LIoU−real)。
在训练的中后期,WIoU v3会给低质量的锚框分配较小的梯度增益,以减少有害的梯度。同时,针对普通质量的锚框,提高模型的定位性能。文章来源:https://www.toymoban.com/news/detail-521396.html
三、实验
通过比较BBR的loss版本2和原始版本(下表),单调FM对SIoU和EIoU的性能都有负面影响。由于这两者对距离度量的惩罚更强,在单调调频的作用下合成了更大的有害梯度。CIoU和WIoU v1对于距离度量的惩罚较小,这使得它们能够有效地削弱单调FM对有害梯度的放大。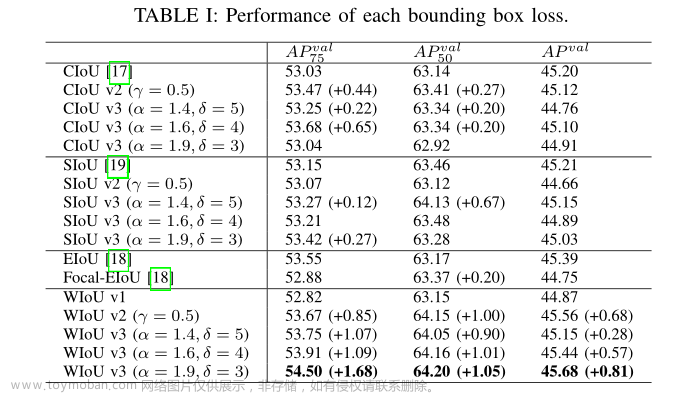
此外,作者比较了锚框的回归结果(下图)。具有单调FM的WIoU v2受到低质量示例的影响,导致预测结果不佳。WIoU v3得益于动态非单调调频,有效地屏蔽了低质量示例的影响,实现了理想的预测。
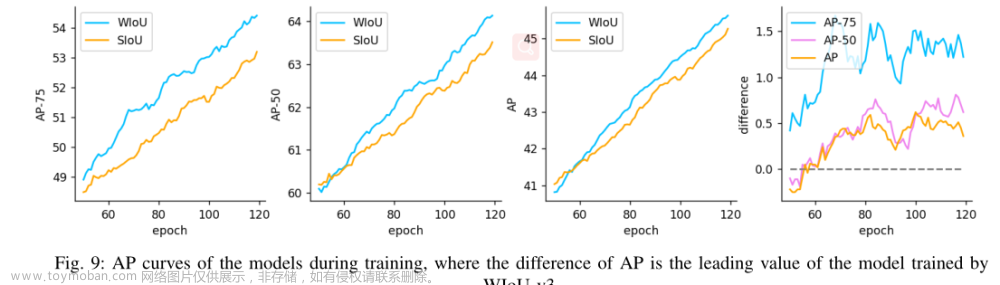
YOLOv7在训练过程中的精度变化(上图)。由于动态非单调FM,WIoU v3有效地屏蔽了训练过程中的许多负面影响,因此模型的精度可以更快地提高。
在将WIoU v3与最先进的BBR损失进行比较后,得到了几个精度差异较大的类别(表II)。受益于识别低质量示例的能力,WIoU v3训练的模型对某些类别的精度有了很大的提高。与此同时,该模型对飞机和长椅的精度有所下降。
一些飞机的标签是有争议的(下图),一些选定的飞机缺乏突出的特征,如机身。这些例子和低质量的例子一样难学,这部分难学的例子被WIoU v3的FM丢弃了。此外,长凳的标签有很多错误,也有大量的长凳没有贴上标签。这对于泛化能力强、检测到更多长椅的模型来说是不公平的 文章来源地址https://www.toymoban.com/news/detail-521396.html
文章来源地址https://www.toymoban.com/news/detail-521396.html
到了这里,关于Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!