这里整理一下平时所用的多模态数据集以备之用,主要分为
多模态分类(情感分类,影视分类)
多模态问答
多模态匹配(检索)
多模态生成
后面会不断地去添加,也希望能够帮到其他人,欢迎大家补充。
【0】.多模态以及其他方向如何入门或者查找数据集?
看到评论区有很多小伙伴对多模态方面不知道怎么入门,不知道使用哪些数据集,最简单的方法是找一篇最近最新的相关方向的多模态论文,通过related work可以了解这个方向的发展,通过experiment了解这个方向比较受欢迎的一些数据集。论文可以用google学术或者arxiv查,基本上能查到目前大部分的论文。
https://www.aclweb.org/anthology/ 这个网站有很多会议论文,包括ACL,EMNLP等等
https://papers.nips.cc/ 这个网站是影响力特别大的Nips会议论文
上述链接均可以有年份查询,通过年份可以找到对应年份的所有会议论文,非常方便哦。
【1】.多模态分类数据集(包括情感分类、影视分类)
一、双模态(一般是文本、图像和语音的两两组合)
1.《Multi-Modal Sarcasm Detection in Twitter with Hierarchical Fusion Model》--【多模态讽刺识别】 2019年。论文中建立的数据集,包含文本和图像两个模态,具体来说是三个模态,文本部分包含两个方面:一个是描述(文本模态),另一个是图像的属性,即图像包含那些东西,用文字描述(也可以归类为属性模态)。数据集较好之处是给出了原始数据,即有原始的文本,原始的图像和属性描述,可以任意操作成实验表征。数据集和代码链接是https://github.com/headacheboy/data-of-multimodal-sarcasm-detection
2.《Towards Multimodal Sarcasm Detection(An Obviously Perfect Paper)》--【多模态讽刺识别】2019年。论文给的是图像和文本双模态讽刺视频。其中每个标签对应的图像包含多个,对应的文本是一组对话,具体如下图所示:
数据集链接是:https://github.com/soujanyaporia/MUStARD
二、三模态(一般是文本、图像加语音)
1.《Multimodal Language Analysis in the Wild_ CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph》--【多模态情感和情绪分析】2018年。论文中描述的CMU-MOSEI数据集规模最大的三模态数据集之一,且具有情感和情绪两个标签,情感从negative到positive一共有7个类别,情绪包含愤怒、开心、悲伤、惊讶、害怕和厌恶6个类别,标签的数值在[-3~3]之间。数据集给出了原始数据,但是过于原始,即给出的是文本,音频和视频文件,图像还得自己去以固定频率捕获并且和文本语音对其还是比较麻烦的。大多实验都使用处理好的实验数据。数据集的链接是:http://immortal.multicomp.cs.cmu.edu/raw_datasets/processed_data/
2.《UR-FUNNY: A Multimodal Language Dataset for Understanding Humor》--【多模态幽默分析】2019年。论文中描述的是UR-FUNNY数据集,包含文本语音图像三个模态来分析幽默情感。具体目前没用到没有细看,日后再补充。数据集和代码链接是:https://github.com/ROC-HCI/UR-FUNNY
好像部分同学下载失败,可以用下面这个链接:
链接:https://pan.baidu.com/s/1iOwSmlaQeTo3NH95LnPl0A
提取码:5z4o
3.《MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos》--【多模态情绪分析】。论文中描述的是CMU-MOSI数据集,跟上述的CMU-MOSEI数据集名字很像,但是发布较早,规模小且只有情绪的标签。数据集跟MOSEI一样,有处理好的实验数据,但是也有部分原始数据,video部分依然是视频不是已经捕获好的图像。数据集的链接是:http://immortal.multicomp.cs.cmu.edu/raw_datasets/processed_data/
4.《CH-SIMS: A Chinese Multimodal Sentiment Analysis Dataset with Fine-grained Annotations of Modality》--【中文多模态情绪】2020年。论文中给出常规的文本、图片和语音的数据进行多模态情绪分类,其中标签更加细致,不仅有最终的标签,还有各个模态的标签。
具体如图所示。论文以及数据集具体我还没看,日后需要我将修改更仔细。数据集链接是: https://github.com/thuiar/MMSA
5.《Iemocap: interactive emotional dyadic motion capture database》--【多模态视频情感分析】2008。论文简单搜了一下好像要钱,凎!根据摘要可以看出IEMOCAP数据库包含大约12小时的视听数据,包括视频、语音、面部运动捕捉、文本转录。IEMOcap数据库有愤怒、快乐、悲伤、中立标签。
数据集参考这个CSDN博客https://blog.csdn.net/qq_33472146/article/details/90665196 ,需要填写一个申请表,具体如下:
数据集获取方式:
需要填一个申请表,如果没结果就给他们发封邮件。数据很大,大概18G左右,可以用Chrome下载管理器下载。
如果有任何问题可以联系这个人Anil Ramakrishna (akramakr@usc.edu)
给他发邮件,告诉他直接把数据集公开在网盘里多好,还要填申请表。。。
6.《GATED MULTIMODAL UNITS FOR INFORMATION FUSION》--【多模态影视类型分类】
该数据集是MM-IMDB,主要是进行影视短剧的多类,包含喜剧,家庭剧等等,具体分布如下图所示。
数据集MM-IMDB的链接是https://archive.org/details/mmimdb

【2】.多模态问答数据集
一、双模态(一般是文本+图片)
《 Making the v in vqa matter: Elevating the role of image understanding in visual question answering》--【多模态问答】2017年。论文中是VQA数据集,包括原始的图片、问答文本等各种属性。我们简单的可以通过word2vec或者Glove或者bert提取文本的embedding,通过Resnet来提取图片的feature,图片问题和回答三个方面通过对应的id来联系

数据集下载链接在https://visualqa.org/download.html
【3】.多模态检索(匹配)数据集
一、双模态(一般是文本+图像)
1.《Microsoft COCO Captions Data Collection and Evaluation Server》--【多模态图片字幕】2015年。论文给出的是经典的MS COCO数据集,现在还在广泛使用,我看21年的论文依然在用这个数据集,很出名。数据集较大,大部分设计到纯CV方面的数据集,标注一共分为5类:目标点检测,关键点检测,实例分割,全景分割以及图片标注,前面四个都是CV领域的,感兴趣的同学可以玩一下,简单的多模态方向只需要最后一个,当然如果你要通过目标检测辅助多模态分析等等方向前面几个标注也是有用的。简单的,我们这里需要的是图片和字幕两个模态,这里注意每个图片对应5条字幕,可以用来做多模态匹配之类的任务。数据集包括2014年发布的以及2017年发布的,每个都有超过几十万张图片的标注,图片给出的是原始图片,标注是基于JSON文件给出的,也是原始的文本数据,我们只要写出程序将字幕抽取出来就可以了,字幕和图片之间有id对应,非常方便。
数据集链接是:Common Objects in Context
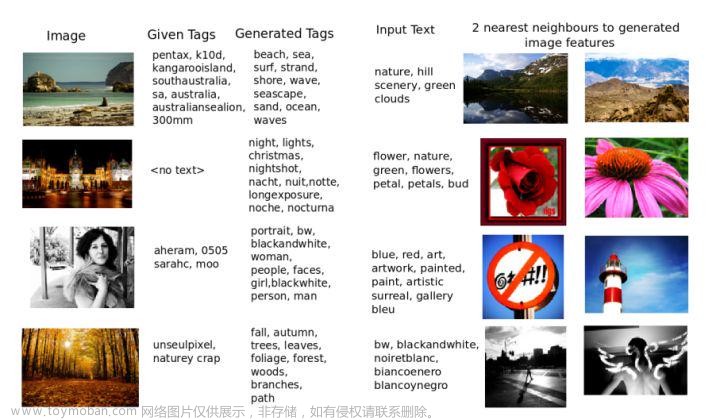
2.《Nus-wide: A real-world web image database from national university of singapore.》--【多模态图片字幕匹配检索】2009年,数据集包含269648张图片,每张图片包含81个真实的标签以及100个文本注释。美中不足的是大概看了一下,给的直接是图片的特征,也就没有原始图片,如果论文的方法在Embedding之上可以拿来试一试。
数据集链接是:https://lms.comp.nus.edu.sg/wp-content/uploads/2019/research/nuswide/NUS-WIDE.html
具体使用起来还稍微有一些复杂,因为给的是feature,所以我就没用了。数据集的使用可以参考这个博客,写的很详细:NUS_WIDE数据库制作_LeeWei-CSDN博客_nuswide数据集
3.《Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models》--【多模态图片字幕匹配检索】Flickr30k数据集,给定了31783张图像以及158915个文本注释,可以看出和MS COCO一样一张图片对应5个注释。只不过图片有点小,只有3万张。具体使用步骤可以参考这个博客:https://blog.csdn.net/gaoyueace/article/details/80564642
数据集链接是http://shannon.cs.illinois.edu/DenotationGraph/进行填表,获取下载地址http://shannon.cs.illinois.edu/DenotationGraph/data/index.html,但是好像不是很稳定。
也可以直接用我这百度云的:https://pan.baidu.com/s/1Z4tyzFfbMSkQkjcuTwG5UQ,提取码是:bk9l,分享是永久有效。下载文件蛮简单的,一个图片,一个字幕,通过图片id进行对应。
对应于Flickr30k 3万张图片,有一个小版本Flickr8k,只有8千张图片。
数据集链接是:https://pan.baidu.com/s/1PWuBlzLK2bFqkRbaBTqAuw
提取码:txnd
《The IAPR Benchmark: A New Evaluation Resource for Visual Information Systems》--【多模态图片字幕匹配检索】IAPR TC-12数据集,包括20,000张从世界各地拍摄的静态自然图像,包括各种不同的静态自然图像截面。这包括不同运动和动作的照片,人物、动物、城市、风景和当代生活的许多其他方面的照片。使用三种语言(英语,德语和西班牙语)来进行注释。
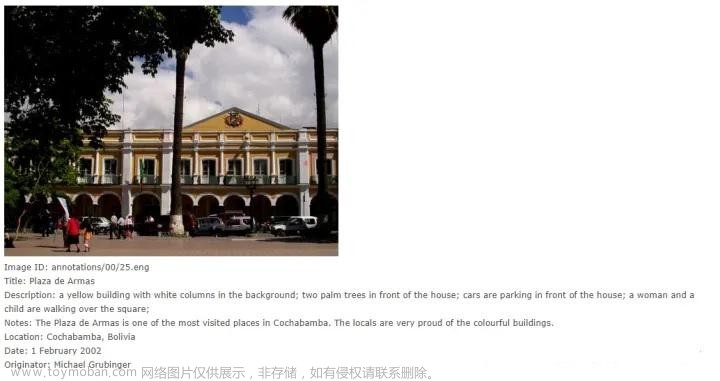
论文链接是:http://thomas.deselaers.de/publications/papers/grubinger_lrec06.pdf
数据集链接是:https://www.imageclef.org/photodata
《Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning》--【多模态检索】2018年。较大的多模态数据集,包含超过300万张图片以及相应的文本描述,可以用于多模态预训练(不过还是感觉好少哇,跟单模态几亿张图片比起来,多模态的标注工作太耗时耗力了)。如图所示:


数据集地址:https://github.com/google-research-datasets/conceptual-captions
论文地址:https://www.aclweb.org/anthology/P18-1238.pdf
6.《WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training》--【多模态检索 2021】论文发布了超级大型的中文文本图片匹配数据集 RUC-CAS-WenLan 用于预训练,数据集规模在3000万对。同时论文也发布了大型中文多模态检索预训练模型。
模型代码以及数据集的下载链接如下:https://github.com/BAAI-WuDao/BriVl
论文地址:https://arxiv.org/abs/2103.06561
【4】多模态生成数据集
一、三模态(文本、图像和语音)
1.《How2: A Large-scale Dataset for Multimodal Language Understanding》--【多模态自动语音识别、多模态机器翻译、语音文本翻译、多模态总结(Summarization)】
How2 是一个大规模的多模态数据集,涵盖了80000个视频片段(约2000小时)的各种主题的大型教学视频数据集,使用单词级别的时间对齐英语字幕。 除了多模态之外,How2也是多语言的:字幕也有葡萄牙语翻译。文章来源:https://www.toymoban.com/news/detail-522317.html
数据集的链接是https://github.com/srvk/how2-dataset文章来源地址https://www.toymoban.com/news/detail-522317.html

到了这里,关于多模态分析数据集(Multimodal Dataset)整理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!