1、CPU性能监控
1.2、平均负载基础
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。平均负载其实就是平均活跃进程数。平均活跃进程数,直观上的理解就是单位时间内的活跃进程数。
查看cpu个数:
grep 'model name' /proc/cpuinfo | wc -l
负载说明(现针对单核情况,不是单核时则乘以核数)
uptime
load<1:没有等待
load==1:系统已无额外的资源跑更多的进程了
load>1:进程都堵着等待资源
不同load值说明的问题
1)1分钟 load >5,5分钟 load ❤️,15分钟 load <1
短期内繁忙,中长期空闲,初步判断是一个抖动或者是拥塞前兆
2)1分钟 load >5,5分钟 load >3,15分钟 load <1
短期内繁忙,中期内紧张,很可能是一个拥塞的开始
3)1分钟 load >5,5分钟 load >5,15分钟 load >5
短中长期都繁忙,系统正在拥塞
4)1分钟 load <1,5分钟Load>3,15分钟 load >5
短期内空闲,中长期繁忙,不用紧张,系统拥塞正在好转
举个例子,假设我们在一个单 CPU 系统上看到平均负载为 1.73(1分钟),0.60(5分钟),7.98(15分钟),那么说明在过去 1 分钟内,系统有 73% 的超载,而在 15 分钟内,有 698% 的超载,从整体趋
势来看,系统的负载在降低。
当平均负载高于 CPU 数量 70% 的时候,我们就该考虑分析排查负载高的问题了。一旦负载过高,就可
能导致进程响应变慢,进而影响服务的正常功能。
1.3、平均负载与 CPU 使用率
平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
1.4、监控命令
安装对应的命令:apt install stress sysstat
其中sysstat 包括了mpstat 和pidstat 。
压测命令:stress ,一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
监测命令:mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
(1)检测是否有活动进程:
sudo ps -ef |grep "nginx: master process" |grep -v grep
(2)检测有几个同样的活动进程
sudo ps -ef |grep "nginx: master process" |grep -v grep |wc -l
top命令
top命令用于查看活动进程的CPU和内存信息,能够实时显示系统中各个进程的资源占用情况,可以按照CPU、内存的使用情况和执行时间对进程进行排序。
我们可以用以下所示的top命令的快捷键对输出的显示信息进行转换。
t:切换报示进程和CPU状态信息。
n:切换显示内存信息。
r:重新设置一个进程的优先级。系统提示用户输人需要改变的进程PID及需要设置的进程优先级,
然后输入个正数值使优先级降低,反之则可以使该进程拥有更高的优先级,即是在原有基础上进行
相加,默认优先级的值是100
k:终止一个进程,系统将提示用户输入需要终止的进程PID o
s:改变刷新的时间间隔。
u:查看指定用户的进程。
top 命令查找cpu占用率最高的程序,找到对应的PID
top -Hp pid ,查看具体进程下的线程,比如
mpstat命令
此命令用于实时监控系统CPU的一些统计信息,这些信息存放在/proc/stat文件中,在多核CPU系统里,不但能查看所有CPU的平均使用信息,还能查看某个特定CPU的信息。
使用方式:mpstat [-P {cpu|ALL}] [internal [count]]
当mpstat不带参数时,输出为从系统启动以来的平均值。

mpstat -P ALL
使用mpstat -P ALL 5 2命令,表示每5秒产生一个报告,总共产生2个。
pidstat
pidstat用于监控全部或指定的进程占用系统资源的情况,包括CPU、内存、磁盘I/O、程切换、线程数等数据。
-u:表示查看cpu相关的性能指标
-w:表示查看上下文切换情况,要想查看每个进程的详细情况,要加上-w
-t:查看线程相关的信息,默认是进程的;常与-w结合使用(cpu的上下文切换包括进程的切换、线程
的切换、中断的切换)
-d:展示磁盘 I/O 统计数据
-p:指明进程号
pidstat -urd -p 进程号
[root@VM_0_ubuntu ~]# pidstat -urd -p 24615
Linux 3.10.0-957.5.1.el7.x86_64 (VM_0_ubuntu) 08/22/2019 x86_64 (1 CPU)
场景一:CPU 密集型进程
# 1、模拟一个 CPU 使用率 100% 的场景
stress --cpu 1 --timeout 600
# 2、在第二个终端运行 uptime 查看平均负载的变化情况
uptime
# 3、第三个终端运行 mpstat 查看 CPU 使用率的变化情况
mpstat -P ALL 5
场景二:I/O 密集型进程
# 1. 第一个终端运行 stress 命令模拟 I/O 压力
stress -i 1 --timeout 600
# 2. 第二个终端运行 uptime 查看平均负载的变化情况
uptime
# 3. 第三个终端运行 mpstat 查看 CPU 使用率的变化情况
mpstat -P ALL 5 1
# 4. 查看是哪个进程,导致 iowait较高
pidstat -u 5 1
场景三:大量进程的场景
# 1. 第一个终端模拟8个进程
stress -c 8 --timeout 600
# 2. 第二个终端uptime
uptime
# 3. 使用pidstat查看进程情况
pidstat -u 5 1
stress --cpu 1 --timeout 600
mpstat -P ALL 5 2
pidstat -urd -p 3320
vmstat 5
apt install sysbench
sysbench --num-threads=10 --max-time=300 --max-requests=1000000 --test=threads run
free -h
iostat
swapon -s
df -h
du -s
du -c
ip -s addr show dev ens33
sar -n DEV 1
1.5、CPU上下文切换
1、所谓的上下文切换,就是把上一个任务的寄存器和计数器保存起来,然后加载新任务的寄存器和计数器,最后跳转到新任务的位置开始执行新任务。
2、根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换。
1、系统调用上下文切换
linux 进程既可以在用户空间运行,又可以在内核空间中运行。
当它在用户空间运行时,被称为进程的用户态;当它进入进入内核空间的时候,被称为进程的内核态
从用户态到内核态的转变过程,需要通过系统调用来完成
CPU 寄存器里原来的指令位置是在用户态。但是为了执行内核态代码,需要先把用户态的位置保存起
来,然后寄存器更新为内核态指令的新位置。最后跳转到内核态运行内核任务。
当系统调用结束后,CPU 寄存器需要恢复原来保存的用户态位置,然后再切换到用户空间,继续运行进程。一次系统调用发生了两次 CPU 上下文切换!
系统调用过程中对用户态的资源没有任何影响,也不会切换进程,所以也称为特权模式切换
2、进程上下文切换
进程是由内核来管理和调度的,所以进程的切换只发生在内核态。进程的上下文不仅包括了虚拟内存、
栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
进程的上下文切换在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保
存下来;而加载了下一进程的内核态后再刷新进程的虚拟内存映射关系和用户栈,刷新虚拟内存映射就
涉及到 TLB 快表 (虚拟地址缓存),因此会影响内存的访问速度。

进程上下文切换的原因
其一,为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。(被动切换)
其二,进程在系统资源不足,这个时候进程也会被挂起,并由系统调度其他进程运行。(主动切换)
其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
其四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
第五,发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
3、线程上下文切换
线程与进程的区别在于:线程是调度的基本单位,而进程是资源分配基本单位。内核中的任务调度,实际调度的是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
1:当进程只有一个线程时,可以认为进程就等于线程
2:当进程拥有多个线程时,共享虚拟内存和全局变量等资源。这些资源在上下文切换时不需要修改
3:线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时需要保存
4、线程的上下文切换分为两种
1.前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
2.前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据
5、中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备
事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。中断上下文只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等
6、怎么查看上下文切换
过多的上下文切换,会把 CPU 时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成了系统性能大幅下降的一个元凶。
们可以使用 vmstat 这个工具,来查询系统的上下文切换情况。此命令显示关于内核线程、虚拟内存、
磁盘I/O 、陷阱和CPU占用率的统计信息。
# 每隔5秒输出一组数据
vmstat 5
需要注意如下内容。
r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。
b(Blocked)则是处于不可中断睡眠状态的进程数。
buff:是I/O系统存储的磁盘块文件的元数据的统计信息。
cache:是操作系统用来缓存磁盘数据的缓冲区,操作系统会自动一调节这个参数,在内存紧张时
操作系统会减少cache的占用空间来保证其他进程可用。
si和so较大时,说明系统频繁使用交换区,应该查看操作系统的内存是否够用。
bi和bo代表I/O活动,根据其大小可以知道磁盘I/O的负载情况。
in(interrupt)则是每秒中断的次数。
cs:参数表示线程环境的切换次数,此数据太大时表明线程的同步机制有问题。
7、案例分析
上下文切换频率是多少次才是正常的?
使用sysbench 来模拟系统多线程调度切换的情况。
有命令,都默认以 root 用户运行,运行 sudo su root 命令切换到 root 用户。
# 1. 测试工具和监测命令的安装:
apt install sysbench sysstat
# 2. 使用vmstat查看空闲系统的上下文切换次数
# 间隔1秒后输出1组数据
vmstat 1 1
# 3. 在另一个终端开始压测
# 以10个线程运行5分钟的基准测试,模拟多线程切换的问题
sysbench --num-threads=10 --max-time=300 --max-requests=10000000 --test=threads run
# 4. 使用vmstat查看
vmstat 1
cs 列:的上下文切换次数从之前的 35 骤然上升到了 139 万。
r 列:就绪队列的长度已经到了 8,远远超过了系统 CPU 的个数 2,所以肯定会有大量的 CPU 竞争。
us(user)和 sy(system)列:这两列的 CPU 使用率加起来上升到了 100%,其中系统 CPU 使用率,也就是 sy 列高达 84%,说明 CPU 主要是被内核占用了。
in 列:中断次数也上升到了 1 万左右,说明中断处理也是个潜在的问题。
综合这几个指标,我们可以知道,系统的就绪队列过长,也就是正在运行和等待 CPU 的进程数过多,
导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高。
8、使用pidstat查看
什么进程导致了这些问题呢?
在第三个终端再用 pidstat 来看一下, CPU 和进程上下文切换的情况:
# 每隔1秒输出1组数据(需要 Ctrl+C 才结束)
# -w参数表示输出进程切换指标,而-u参数则表示输出CPU使用指标
$ pidstat -w -u 1
从 pidstat 的输出你可以发现,CPU 使用率的升高果然是 sysbench 导致的,它的 CPU 使用率已经达到了 100%。但上下文切换则是来自其他进程,包括非自愿上下文切换频率最高的 pidstat ,以及自愿上下文切换频率最高的内核线程 kworker 和 sshd。怪异的事儿:pidstat 输出的上下文切换次数,加起来也就几百,比 vmstat 的 139 万明显小了太多。这是怎么回事呢?难道是工具本身出了错吗?别着急,在怀疑工具之前,我们再来回想一下,前面讲到的几种上下文切换场景。其中有一点提到, Linux 调度的基本单位实际上是线程,而我们的场景sysbench 模拟的也是线程的调度问题,那么,是不是 pidstat 忽略了线程的数据呢?通过运行 man pidstat ,你会发现,pidstat 默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标。所以,我们可以在第三个终端里, Ctrl+C 停止刚才的 pidstat 命令,再加上 -t 参数,重试一下看看
# 每隔1秒输出一组数据(需要 Ctrl+C 才结束)
# -wt 参数表示输出线程的上下文切换指标
pidstat -wt 1
现在你就能看到了,虽然 sysbench 进程(也就是主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换次数却有很多。看来,上下文切换罪魁祸首,还是过多的 sysbench 线程。
每秒上下文切换多少次才算正常呢?这个数值其实取决于系统本身的 CPU 性能。在我看来,如果系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算是正常的。但当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。
这时,你还需要根据上下文切换的类型,再做具体分析。比方说:
自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题;
非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶
颈;中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型。
1.6、 遇到CPU利用率高该如何排查
遇到CPU使用率高时,首先确认CPU是消耗在哪一块,如果是内核态占用CPU较高:
- %iowait 高,这时要重点关注磁盘IO的相关操作,是否存在不合理的写日志操作,数据库操作等;
- %soft或%cs 高,观察CPU负载是否较高、网卡流量是否较大,可不可以精简数据、代码在是否在多线程操作上存在不合适的中断操作等;
- %steal 高,这种情况一般发生在虚拟机上,这时要查看宿主机是否资源超限;如果是用户态较高,且没有达到预期的性能,说明应用程序需要优化。
1.7、根据指标查找工具


2、内存性能监控
2.1、内存是什么-虚拟内存和物理内存
操作系统有虚拟内存与物理内存的概念。在很久以前,还没有虚拟内存概念的时候,程序寻址用的都是物理地址。程序能寻址的范围是有限的,这取决于CPU的地址线条数。比如在32位平台下,寻址的范围是2^32也就是4G。并且这是固定的,如果没有虚拟内存,且每次开启一个进程都给4G的物理内存,就可能会出现很多问题:
1、因为我的物理内存时有限的,当有多个进程要执行的时候,都要给4G内存,很显然你内存小一点,这很快就分配完了,于是没有得到分配资源的进程就只能等待。当一个进程执行完了以后,再将等待的进程装入内存。这种频繁的装入内存的操作是很没效率的
2、由于指令都是直接访问物理内存的,那么我这个进程就可以修改其他进程的数据,甚至会修改内核
地址空间的数据,这是我们不想看到的
3、因为内存时随机分配的,所以程序运行的地址也是不正确的
一个进程运行时都会得到4G的虚拟内存。这个虚拟内存你可以认为,每个进程都认为自己拥有4G的空
间,这只是每个进程认为的,但是实际上,在虚拟内存对应的物理内存上,可能只对应的一点点的物理内存,实际用了多少内存,就会对应多少物理内存。进程得到的这4G虚拟内存是一个连续的地址空间(这也只是进程认为),而实际上,它通常是被分隔成多个物理内存碎片,还有一部分存储在外部磁盘存储器上,在需要时进行数据交换。进程开始要访问一个地址,它可能会经历下面的过程
1. 每次我要访问地址空间上的某一个地址,都需要把地址翻译为实际物理内存地址
2. 所有进程共享这整一块物理内存,每个进程只把自己目前需要的虚拟地址空间映射到物理内存上
3. 进程需要知道哪些地址空间上的数据在物理内存上,哪些不在(可能这部分存储在磁盘上),还有
在物理内存上的哪里,这就需要通过页表来记录
4. 页表的每一个表项分两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地
址(如果在的话)
5. 当进程访问某个虚拟地址的时候,就会先去看页表,如果发现对应的数据不在物理内存上,就会发
生缺页异常
6. 缺页异常的处理过程,操作系统立即阻塞该进程,并将硬盘里对应的页换入内存,然后使该进程就
绪,如果内存已经满了,没有空地方了,那就找一个页覆盖,至于具体覆盖的哪个页,就需要看操
作系统的页面置换算法是怎么设计的了。


1. 我们的cpu想访问虚拟地址所在的虚拟页(VP3),根据页表,找出页表中第三条的值.判断有效位。
如果有效位为1,DRMA缓存命中,根据物理页号,找到物理页当中的内容,返回。
2. 若有效位为0,参数缺页异常,调用内核缺页异常处理程序。内核通过页面置换算法选择一个页面
作为被覆盖的页面,将该页的内容刷新到磁盘空间当中。然后把VP3映射的磁盘文件缓存到该物理
页上面。然后页表中第三条,有效位变成1,第二部分存储上了可以对应物理内存页的地址的内
容。
3. 缺页异常处理完毕后,返回中断前的指令,重新执行,此时缓存命中,执行1。
4. 将找到的内容映射到告诉缓存当中,CPU从告诉缓存中获取该值,结束。
当每个进程创建的时候,内核会为进程分配4G的虚拟内存,当进程还没有开始运行时,这只是一个内存
布局。实际上并不立即就把虚拟内存对应位置的程序数据和代码(比如.text .data段)拷贝到物理内存
中,只是建立好虚拟内存和磁盘文件之间的映射就好(叫做存储器映射)。这个时候数据和代码还是在
磁盘上的。当运行到对应的程序时,进程去寻找页表,发现页表中地址没有存放在物理内存上,而是在
磁盘上,于是发生缺页异常,于是将磁盘上的数据拷贝到物理内存中。
另外在进程运行过程中,要通过malloc来动态分配内存时,也只是分配了虚拟内存,即为这块虚拟内存
对应的页表项做相应设置,当进程真正访问到此数据时,才引发缺页异常。
可以认为虚拟空间都被映射到了磁盘空间中(事实上也是按需要映射到磁盘空间上,通过mmap,
mmap是用来建立虚拟空间和磁盘空间的映射关系的)
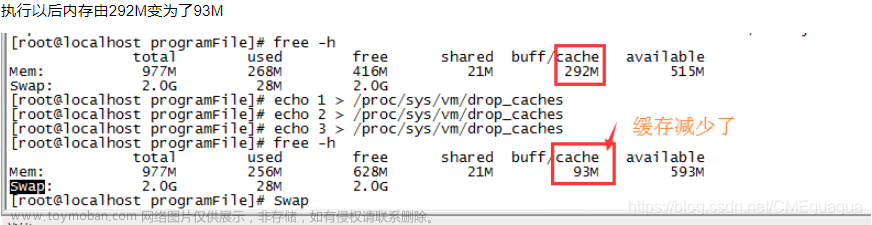
2.2、内存中的buffer和cache
free -h
这个界面包含了物理内存 Mem 和交换分区 Swap 的具体使用情况,比如总内存、已用内存、缓存、可
用内存等。其中缓存是 Buffer 和 Cache 两部分的总和。
1. Mem 行(第二行)是内存的使用情况。
2. Swap 行(第三行)是交换空间的使用情况。
total 列显示系统总的可用物理内存和交换空间大小。
used 列显示已经被使用的物理内存和交换空间。
free 列显示还有多少物理内存和交换空间可用使用。
shared 列显示被共享使用的物理内存大小。
buff/cache 列显示被 buffer 和 cache 使用的物理内存大小。
available 列显示还可以被应用程序使用的物理内存大小。
2.3、对于buffer和cache的区别
1. Buffers 是对原始磁盘块的临时存储,也就是用来缓存磁盘的数据,通常不会特别大(20MB 左
右)。这样,内核就可以把分散的写集中起来,统一优化磁盘的写入,比如可以把多次小的写合并
成单次大的写等等。
2. Cached 是从磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据。这样,下次访问这些文
件数据时,就可以直接从内存中快速获取,而不需要再次访问缓慢的磁盘。

1. Buffer 既可以用作“将要写入磁盘数据的缓存”,也可以用作“从磁盘读取数据的缓存”。
2. Cache 既可以用作“从文件读取数据的页缓存”,也可以用作“写文件的页缓存”。
Buffer 是对磁盘数据的缓存,而 Cache 是文件数据的缓存,它们既会用在读请求中,也会用在写请求
中。
在读写普通文件时,会经过文件系统,由文件系统负责与磁盘交互;而读写磁盘或者分区时,就会跳过
文件系统,也就是所谓的“裸I/O“。这两种读写方式所使用的缓存是不同的,也就是文中所讲的 Cache 和
Buffer 区别。
2.4、内存监控优化
Buffer 和 Cache 分别缓存的是对磁盘和文件系统的读写数据。
1、从写的角度来说,不仅可以优化磁盘和文件的写入,对应用程序也有好处,应用程序可以在数据真正落盘前,就返回去做其他工作。
2、从读的角度来说,不仅可以提高那些频繁访问数据的读取速度,也降低了频繁 I/O 对磁盘的压力
3、文件IO性能监控

Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File
System)。
I/O 指的是相对内存而言的 input 和 output。从文件、数据库、网络向内存中写入数据叫做 input;从
内存向文件、数据库、网络中输出数据叫做 output。Linux 系统 I/O 分为内核准备数据和将数据从内核
拷贝到用户空间两个阶段
3.1、 I/O 的两种方式(缓存 I/O 和直接 I/O)
缓存 I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制
中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间(用户空间)。
1、读操作:操作系统检查内核空间的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从缓存
中返回,也就是将数据复制到应用程序的用户空间;否则从磁盘中读取数据至内核空间的缓冲区,
再将内核空间缓冲区的数据返回。
2、写操作:将数据从用户空间复制到内核空间的缓冲区,这时对用户程序来说写操作就已经完成。至
于什么时候将数据从内核空间写到磁盘中,这步由操作系统决定,除非显示地调用了 sync 同步命令。
缓存IO的优点
缓存 I/O 的优点:
- 在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全;
- 可以减少读盘的次数,从而提高性能。
缓存IO的缺点
缓存 I/O 的缺点:
- 在缓存 I/O 机制中,DMA 方式可以将数据直接从磁盘读到内核空间的页缓存中,或者将数据从内
核空间的页缓存中直接写回到磁盘上,而不能直接在应用程序地址空间(用户空间)和磁盘之间进行
数据传输。这样,数据在传输过程中需要在应用程序地址空间(用户空间)和页缓存(内核空间)之间进
行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是比较大的。
直接 I/O
直接 IO 就是应用程序直接访问磁盘,而不经过内核缓冲区,这样做的目的是减少一次从内核缓冲区到用户程序地址空间的数据复制操作。例如数据库管理系统这类应用,它们更倾向于选择自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据。数据库管理系统可以提供一种更加高效的缓存机制来提高数据库中存取数据的性能。
3.2、监控磁盘IO命令
iostat IO状态
该命令用于监控CPU占用率、平均负载值及I/O读写速度等。
await指的是平均等待时间,一般都在10ms左右。
cpu的统计信息,如果是多cpu系统,显示的所有cpu的平均统计信息。
%user:用户进程消耗cpu的比例
%nice:用户进程优先级调整消耗的cpu比例
%sys:系统内核消耗的cpu比例
%iowait:等待磁盘io所消耗的cpu比例
%idle:闲置cpu的比例(不包括等待磁盘I/O)
磁盘的统计参数
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to
the device.)。“一次传输"意思是"一次I/O请求”。
多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量;
kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。
显示扩展统计信息:
iostat -x
每个输出消息含义:
rrqm/s: 每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并
wrqm/s: 每秒对该设备的写请求被合并次数
r/s: 每秒完成的读次数
w/s: 每秒完成的写次数
rkB/s: 每秒读数据量(kB为单位)
wkB/s: 每秒写数据量(kB为单位)
avgrq-sz:平均每次IO操作的数据量(扇区数为单位)
avgqu-sz: 平均等待处理的IO请求队列长度
await: 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位)
svctm: 平均每次IO请求的处理时间(毫秒为单位)
%util: 采用周期内用于IO操作的时间比率,即IO队列非空的时间比率
// kb/s显示磁盘信息,每2s刷新一次
iostat -d -k 2
// kb/s显示磁盘统计信息及扩展信息,每1s刷新 ,刷新10次结束
iostat -dkx 1 10
3.3、swapon查看分区使用情况
查看交互分区的使用情况
使用方法:swapon -s
我们在安装系统的时候已经建立了 swap 分区。swap 分区通常被称为交换分区,这是一块特殊的硬盘空间,即当实际内存不够用的时候,操作系统会从内存中取出一部分暂时不用的数据,放在交换分区中,从而为当前运行的程序腾出足够的内存空间。 也就是说,当内存不够用时,我们使用 swap 分区来临时顶替。这种“拆东墙,补西墙”的方式应用于几乎所有的操作系统中
一般来讲,swap 分区容量应大于物理内存大小,建议是内存的两倍,但不超过 2GB。
3.4、df磁盘情况
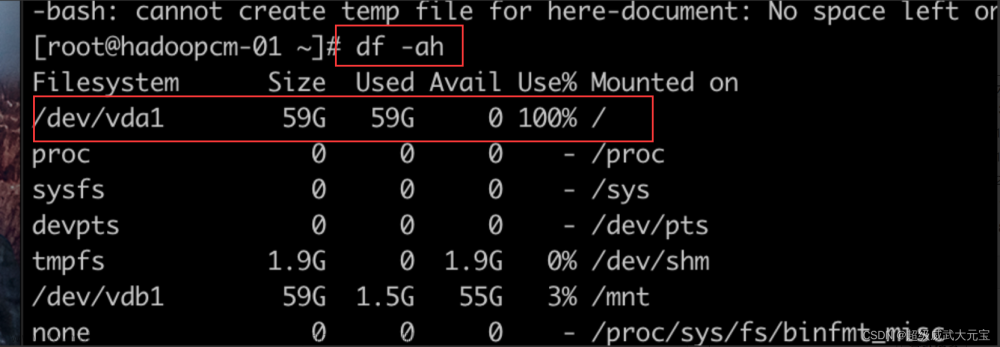
该命令用于查看文件系统的硬盘挂载点和空间使用情况。
使用方式:df -h
3.5、du目录大小
du常用的选项:
-h:以人类可读的方式显示,显示M或K
-a:显示目录占用的磁盘空间大小,还要显示其下目录和文件占用磁盘空间的大小-s:显示目录占用的
磁盘空间大小,不显示其下子目录和文件占用的磁盘空间大小-c:显示几个目录或文件占用的磁盘空间
大小,还要统计它们的总和
du -a 显示目录和目录下子目录和文件占用磁盘空间的大小。直接使用-a 以字节为单位,-ha 如下图以M
或K为结果显示。
du -s 显示当前所在目录大小
du -s -h home 显示home目录大小
du -c 显示几个目录或文件占用的磁盘空间大小,还要统计它们的总和
du -lh --max-depth=1 : 查看当前目录下一级子文件和子目录占用的磁盘容量。
4、网络IO性能监控
4.1、性能指标
实际上,我们通常用带宽、吞吐量、延时、PPS(Packet Per Second)等指标衡量网络的性能。
1. 带宽,表示链路的最大传输速率,单位通常为 b/s (比特 / 秒)。
2. 吞吐量,表示单位时间内成功传输的数据量,单位通常为 b/s(比特 / 秒)或者 B/s(字节 / 秒)。
吞吐量受带宽限制,而吞吐量 / 带宽,也就是该网络的使用率。
3. 延时,表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指
标可能会有不同含义。比如,它可以表示,建立连接需要的时间(比如 TCP 握手延时),或一个数
据包往返所需的时间(比如 RTT)。
4. PPS,是 Packet Per Second(包 / 秒)的缩写,表示以网络包为单位的传输速率。PPS 通常用来
评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即 PPS 可以达到或者接近理论最
大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响。
除了这些指标,网络的可用性(网络能否正常通信)、并发连接数(TCP 连接数量)、丢包率(丢包百
分比)、重传率(重新传输的网络包比例)等也是常用的性能指标。
4.2、网络配置
使用 ifconfig 或者 ip 命令,来查看网络的配置
ifconfig 和 ip 分别属于软件包 net-tools 和 iproute2,iproute2 是 net-tools 的下一代。通常情况
下它们会在发行版中默认安装。
如果你找不到 ifconfig 或者 ip 命令,可以安装这两个软件包。
使用ip
ip -s addr show dev ens33
有几个跟网络性能密切相关的指标需要掌握。
1. 网络接口的状态标志。ifconfig 输出中的 RUNNING ,或 ip 输出中的 LOWER_UP ,都表示物理网
络是连通的,即网卡已经连接到了交换机或者路由器中。如果你看不到它们,通常表示网线被拔掉了。
2. MTU 的大小。MTU 默认大小是 1500,根据网络架构的不同(比如是否使用了 VXLAN 等叠加网
络),你可能需要调大或者调小 MTU 的数值。
3. 网络接口的 IP 地址、子网以及 MAC 地址。这些都是保障网络功能正常工作所必需的,你需要确保
配置正确。
4. 网络收发的字节数、包数、错误数以及丢包情况,特别是 TX 和 RX 部分的 errors、dropped、
overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现了网络 I/O 问题。其中:
1. errors 表示发生错误的数据包数,比如校验错误、帧同步错误等;
2. dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包;
3. overruns 表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处
理(队列满)而导致的丢包;
4. carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;
5. collisions 表示碰撞数据包数。
4.3、套接字信息
使用netstat 或者 ss ,来查看套接字、网络栈、网络接口以及路由表的信息
查询网络的连接信息ss比netstat查询速度更快。
netstat
# head -n 3 表示只显示前面3行
# -l 表示只显示监听套接字
# -n 表示显示数字地址和端口(而不是名字)
# -p 表示显示进程信息
netstat -nlp | head -n 3
ss
# -l 表示只显示监听套接字
# -t 表示只显示 TCP 套接字
# -n 表示显示数字地址和端口(而不是名字)
# -p 表示显示进程信息
ss -ltnp | head -n 3
netstat 和 ss 的输出也是类似的,都展示了套接字的状态、接收队列、发送队列、本地地址、远端地
址、进程 PID 和进程名称等。其中,接收队列(Recv-Q)和发送队列(Send-Q)需要你特别关注,它
们通常应该是 0。当你发现它们不是 0 时,说明有网络包的堆积发生。当然还要注意,在不同套接字状
态下,它们的含义不同。
当套接字处于连接状态(Established)时:
Recv-Q 表示套接字缓冲还没有被应用程序取走的字节数(即接收队列长度)。
Send-Q 表示还没有被远端主机确认的字节数(即发送队列长度)。
当套接字处于监听状态(Listening)时:
Recv-Q 表示全连接队列的长度。
Send-Q 表示全连接队列的最大长度。
所谓全连接,是指服务器收到了客户端的 ACK,完成了 TCP 三次握手,然后就会把这个连接挪到全连接
队列中。这些全连接中的套接字,还需要被 accept() 系统调用取走,服务器才可以开始真正处理客户端
的请求。
与全连接队列相对应的,还有一个半连接队列。所谓半连接是指还没有完成 TCP 三次握手的连接,连接
只进行了一半。服务器收到了客户端的 SYN 包后,就会把这个连接放到半连接队列中,然后再向客户端
发送 SYN+ACK 包。
4.4、协议统计信息
使用 netstat 或 ss 查看协议栈的信息
netstat -s
ss -s
4.5、网络吞吐和 PPS
给 sar 增加 -n 参数就可以查看网络的统计信息,比如网络接口(DEV)、网络接口错误(EDEV)、
TCP、UDP、ICMP 等等。执行下面的命令,你就可以得到网络接口统计信息:
sar -n DEV 1
输出指标含义
rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。
rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。
%ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为
max(rxkB/s, txkB/s)/Bandwidth。
4.6、连通性和延时
ping命令是用于检测网络故障的常用命令,可以用来钡J试一台主机到另外一台主机的网络是否连通
-d 使用Socket的SO_DEBUG功能。
-c<完成次数> 设置完成要求回应的次数。
-f 极限检测。
-i<间隔秒数> 指定收发信息的间隔时间。
-I<网络界面> 使用指定的网络接口送出数据包。
-l<前置载入> 设置在送出要求信息之前,先行发出的数据包。
-n 只输出数值。
-p<范本样式> 设置填满数据包的范本样式。
-q 不显示指令执行过程,开头和结尾的相关信息除外。
-r 忽略普通的Routing Table,直接将数据包送到远端主机上。
-R 记录路由过程。
-s<数据包大小> 设置数据包的大小。
-t<存活数值> 设置存活数值TTL的大小。
-v 详细显示指令的执行过程。
4.7、mdev 往返时延
mdev是 Mean Deviation 的缩写, 表示 ICMP包的RTT(Round-Trip Time,往返时延)偏离平均值的程
度, 主要用来衡量网速的稳定性。 mdev 的值越大说明 网速越不稳定。 另外,不同的操作系统的mdev的名字也有所不同, 在mac下它叫作 stddev, 而在 Windows 下则根本没有这个统计指标
4.8、TTL 生成时间
TTL(Time to Live) ,即生存时间,指的是数据包被路由器丢弃之前允许通过的路由器的跳数,为了
防止数据包在路由器之间无限转发,必须设置一个TTL值,每次路由器转发后都会将这个值减1,直到TTL的值为0,这个数据包的生命就被终结了.
4.9、telnet命令使用
telnet是TCP/IP协议族的一员,是网络远程登录服务的标准协议,帮助用户在本地计算机上连接远程主机。
使用方式:telnet IP PORT
和ssh 的区别
端口区别:telnet是23 ssh是22
本质:telnet是明码传输,ssh是加密传输
4.10、nc
验证服务器端口有没有开放
nc是NetCat的简称,在网络调试工具中享有“瑞士军刀”的美誉,此命令功能丰富、短小精悍、简单实
用,被设计成一款易用的网络工具,可通过TCP/LJDP传输数据。
-l 用于指定nc将处于侦听模式。指定该参数,则意味着nc被当作server,侦听并接受连接,而非向
其它地址发起连接。
-p 暂未用到(老版本的nc可能需要在端口号前加-p参数,下面测试环境是centos6.6,nc版本是
nc-1.84,未用到-p参数)
-s 指定发送数据的源IP地址,适用于多网卡机
-u 指定nc使用UDP协议,默认为TCP
-v 输出交互或出错信息,新手调试时尤为有用
-w 超时秒数,后面跟数字
使用:
# 1
nc -l 9999 # 开启一个本地9999的TCP协议端口,由客户端主动发起连接,一旦连接必须由服务
端发起关闭
# 2
nc -vw 2 129.204.197.215 11111 # 通过nc去访问129.204.197.215主机的11111端口,确认是否存
活;可不加参数
# 3
nc -ul 9999 # 开启一个本地9999的UDP协议端口,客户端不需要由服务端主动发起关闭
# 4
nc 129.204.197.215 9999 < test # 通过129.204.197.215的9999TCP端口发送数据文件
# 5
nc -l 9999 > zabbix.file # 开启一个本地9999的TCP端口,用来接收文件内容
# 测试网速
A机器操作如下:
nc -l 9999 > /dev/null
# B机器开启数据传输
nc 129.204.197.215 9999 </dev/zero
# A机器进行网络监控
sar -n DEV 2 100000
4.11、mtr连通性测试
mtr命令是Linux系统中的网络连通性测试工具,也可以用来检测丢包率。
使用方式:mtr baidu.com
其中的第2列为丢包率,可以用来判断网络中两台机器的连通质量。
模拟丢包:sudo tc qdisc add dev eth0 root netem loss 10%
4.12、nslookup
这是一款检测网络中DNS服务器能否正确解析域名的工具命令,并且可以输出。
使用方式: nslookup sina.com
4.13、traceroute
traceroute可以提供从用户的主机到互联网另一端的主机的路径,虽然每次数据包由同一出发点到达同一目的地的路径可能会不一样,但通常来说大多数情况下路径是相同的。
使用方式:traceroute sina.com
在输出中记录按序列号从1开始,每个记录代表网络一跳,每跳一次表示经过一个网关或者路由;我们看到每行有三个个时间,单位是毫秒,指的是这一跳需要的时间。
4.14、sar
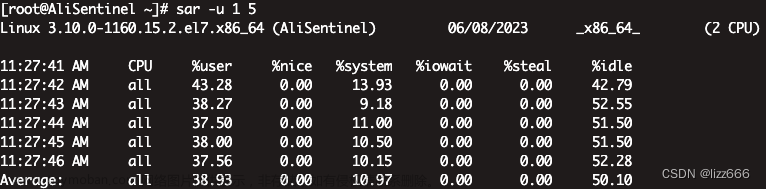
sar是一个多功能的监控工具,使用简单,不需要管理员权限,可以输出每秒的网卡存取速度,适合线上排查问题时使用。
使用方式: sar -n DEV 1 1
从输出中可以看到网卡的读写速度和流量,在应急过程中可以用来判断服务器是否上量。
此命令除了可以用于查看网卡的信息,还可以用来收集如下服务的状态信息。
-A:所有报告的总和。
-u:CPU利用率。
-v:进程、I节点、文件和锁表状态。
-d:硬盘的使用报告。
-r:没有使用的内存页面和硬盘快。
-g:串口I/O的情况。
-b:缓冲区的使用情况。
-a:文件的读写情况。
-c:系统的调用情况。
-R:进程的活动情况。
-y:终端设备的活动情况。
-w:系统的交换活动。
之前公司自己搞的CDN,并发稍微高点图片就拉取不下来。最后发现是云服务器做了限速。
按小时租赁服务器进行测试是很便宜很方便。
4.15、netstat
根据进程名查找进程ID
ps -elf | grep 进程
netstat -nap | grep 24614
4.16、iptraf强大的网络监控
iptraf是一个实时监控网络流量的交互式的彩色文本屏幕界面。它监控的数据比较全面,可以输出TCP连
接、网络接口、协议、端口、网络包大小等信息,但是耗费的系统资源比较多,且需要管理员权限。
使用方式:sudo iptraf
在进入主界面之前可以选择不同的选项,在不同的选项下可以查看不同维度的网络信息
安装方法:
# centos
yum -y install ncurses
yum -y install iptraf
# ubuntu
sudo apt-get install iptraf
4.17、tcpdump
tcpdump是网络状况分析和跟踪工具,是可以用来抓包的实用命令,使用前需要对TCP/IP有所熟悉,因为过滤使用的信息都是TCP/IP格式。
Ubuntu安装:sudo apt-get install tcpdump文章来源:https://www.toymoban.com/news/detail-522467.html
n -D 列举所有网卡设备
n -i 选择网卡设备
n -c 抓取多少条报文
n --time-stamp-precision 指定捕获时的时间精度,默认微妙micro,可选纳秒nano
n -s 指定每条报文的最大字节数,默认262144字节
4.18、nmap
扫描某一主机打开的端口及端口提供的服务信息,通常用于查看本机有哪些端口对外提供服务,或者服
务器有哪些端口对外开放。
# ubuntu安装
sudo apt install nmap
#centos安装
yum install nmap
使用方式:nmap -v -A localhost
nmap localhost #查看主机当前开放的端口
nmap -p 1024-65535 localhost #查看主机端口(1024-65535)中开放的端口
nmap -PS 192.168.56.101 #探测目标主机开放的端口
nmap -PS22,80,3306 192.168.56.101 #探测所列出的目标主机端口
nmap -O 192.168.56.101 #探测目标主机操作系统类型
nmap -A 192.168.56.101 #探测目标主机操作系统类型
4.19、ethtool
ethtool用于查看网卡的配置情况。
sudo apt install ethtool
命令使用格式:ethtool [option] interface
查看网卡:ethtool ens33
(1)查看网卡的接口信息
ethtool eth1 #查看网络接口eth1的信息
(2)关闭网卡eth1的自动协商
ethtool -s eth1 autoneg off
(3)修改网卡速率为 100Mb/s
ethtool -s eth4 speed 100
(4)查看网卡驱动信息
ethtool -i eth0
(5)查看网卡的一些工作统计信息
ethtool –S eth0
(6)停止和查看网卡的发送模块TX的状态
ethtool -A tx off eth0 #修改tx的状态
ethtool -a eth0 #查看tx的状态
(7)关闭网卡对收到的数据包的校验功能
ethtool -K rx off eth0 #关闭校验
ethtool –k eth0 #查看校验启动状态
4.20、lsof
lsof是系统管理/安全的尤伯工具。将这个工具称之为lsof真实名副其实,因为它是指“列出打开文件
(lists openfiles)”。而有一点要切记,在Unix中一切(包括网络套接口)都是文件。
查看帮助文档: lsof -h
你可以使用它来获得你系统上设备的信息,你能通过它了解到指定的用户在指定的地点正在碰什么东
西,或者甚至是一个进程正在使用什么文件或网络连接。具体可以使用man lsof查看帮助文档。
默认 : 没有选项,lsof列出活跃进程的所有打开文件
组合 : 可以将选项组合到一起,如-abc,但要当心哪些选项需要参数
-a : 结果进行“与”运算(而不是“或”)
-l : 在输出显示用户ID而不是用户名
-h : 获得帮助
-t : 仅获取进程ID
-U : 获取UNIX套接口地址
-F : 格式化输出结果,用于其它命令。可以通过多种方式格式化,如-F pcfn(用于进程id、命令
名、文件描述符、文件名,并以空终止)
获取网络信息
显示端口被某个程序占用
lsof -i:port
lsof -p 12 看进程号为12的进程打开了哪些文件
lsof -c abc 显示abc进程现在打开的文件,可以使用less进行分页,b 向后翻一页,d 向后翻半页
lsof abc.txt 显示打开文件abc.txt的进程
5、其他工具
5.1、nmon性能监控
centos安装
wget http://sourceforge.net/projects/nmon/files/nmon16e_mpginc.tar.gz
mkdir nmon16e_mpginc
tar -xvfz nmon16e_mpginc.tar.gz -C nmon16e_mpginc
cd nmon16e_mpginc
# 授权运行权限
chmod +x nmon_x86_64_centos7
# 使nmon在任何地方都能运行
mv nmon_x86_64_centos7 /usr/bin/nmon
# ubuntu安装
sudo apt-get install nmon
# 使用
nmon
后台监控
为了配合性能测试,我们往往需要将一个时间段内系统资源消耗情况记录下来,这时可以使用命令在远
程窗口执行命令:
./nmon/ nmon_x86_rhel5 -f -N -m /nmon/log -s 30 -c 120
其中各参数表示:
-f 按标准格式输出文件:_YYYYMMDD_HHMM.nmon
-N include NFS sections
-m 切换到路径去保存日志文件
-s 每隔n秒抽样一次,这里为30
-c 取出多少个抽样数量,这里为120,即监控=120*(30/60/60)=1小时
根据小时计算这个数字的公式为:c=h3600/s,比如要监控10小时,每隔30秒采样一次,则
c=103600/30=1200
该命令启动后,会在nmon所在目录下生成监控文件,并持续写入资源数据,直至360个监控点收集完成
——即监控1小时,这些操作均自动完成,无需手工干 预,测试人员可以继续完成其他操作。如果想停
止该监控,需要通过“#ps –ef|grep nmon”查询进程号,然后杀掉该进程以停止监控。
定时任务
除配合性能测试的短期监控,我们也可以实现对系统的定期监控,作为运营维护阶段的参考。定期监控
实现如下:
(1)执行命令:#crontab –e
(2)在最后一行添加如下命令:
0 8 * * 1,2,3,4,5 /nmon/nmon_x86_rhel5 -f -N -m /nmon/log -s 30 -c 1200
表示:
周一到周五,从早上08点开始,监控10个小时(到18:00整为止),输出到/nmon/log
测试指标可视化
nmon命令 生成的nmon可以通过工具进行可视化展示,一般可以使用nmonchart、nmon_analyser
nmonchart
nmonechart 使用Google charts 生成html报告
5.2、glances系统监控
安装
#centos
yum install -y glances
#ubuntu
$ sudo apt-add-repository ppa:arnaud-hartmann/glances-stable
$ sudo apt-get update
$ sudo apt-get install glances
glances
除了很多命令行选项之外,Glances 还提供了更多的可在其运行时开关输出信息选项的快捷键,下面是
一些例子:
a – 对进程自动排序
c – 按 CPU 百分比对进程排序
m – 按内存百分比对进程排序
p – 按进程名字母顺序对进程排序
i – 按读写频率(I/O)对进程排序
d – 显示/隐藏磁盘 I/O 统计信息
f – 显示/隐藏文件系统统计信息
n – 显示/隐藏网络接口统计信息
s – 显示/隐藏传感器统计信息
y – 显示/隐藏硬盘温度统计信息
l – 显示/隐藏日志(log)
b – 切换网络 I/O 单位(Bytes/bits)
w – 删除警告日志
x – 删除警告和严重日志
1 – 切换全局 CPU 使用情况和每个 CPU 的使用情况
h – 显示/隐藏这个帮助画面
t – 以组合形式浏览网络 I/O
u – 以累计形式浏览网络 I/O
q – 退出(‘ESC‘ 和 ‘Ctrl&C‘ 也可以
5.3、w
显示谁登录了系统并执行了哪些程序。
[root@VM_0_ubuntu ~]# w -h
root pts/0 113.246.155.156 10:58 2.00s 0.23s 0.23s -bash
root pts/2 113.246.155.156 11:30 26.00s 0.06s 0.00s tail -f /data/rtc/room_server/log/roll.log
root pts/3 113.246.155.156 11:53 1:30 0.03s 0.03s -bash
6、日志监控
tail
tail -h
在实时日志上打印颜色,给每个状态给上不同的颜色,INF绿色、WARN黄色、ERROR红色
tail -f /data/rtc/room_server/log/roll.log | perl -pe
's/(INF)/\e[0;32m$1\e[0m/g,s/(WARN)/\e[0;33m$1\e[0m/g,s/(ERROR)/\e[1;31m$1\e[0m/g'
multitail
可同时开启多视窗看log,适合用在看部署在很多机器上的项目的log -cS [color_scheme] : 可以选择输出
的log的颜色,推荐使用goldengate,也可自定义(修改/etc/multitail.conf)
dos2unix和unix2dos
用于转换Windows和UNIX的换行符,通常在Windows系统h开发的脚本和配置,UNIX系统下都需要转换。文章来源地址https://www.toymoban.com/news/detail-522467.html
使用方式:
dos2unix test.txt
unix2dos test.txt
#转换整个目录
find . -type f -exec dos2unix {} \;
find ./ -type f 此命令是显示当前目录下所有的文件
到了这里,关于Linux网络、磁盘、内存、日志监控的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[Linux]日志文件已删掉磁盘空间不释放,不重启服务进程的解决方法](https://imgs.yssmx.com/Uploads/2024/02/648095-1.png)