背景:当前随着人工智能的快速发展,人机交互的热度变得越来越大,作为人机交互的很重要的一部分-----语音交互,逐渐成为当前的热门论点。
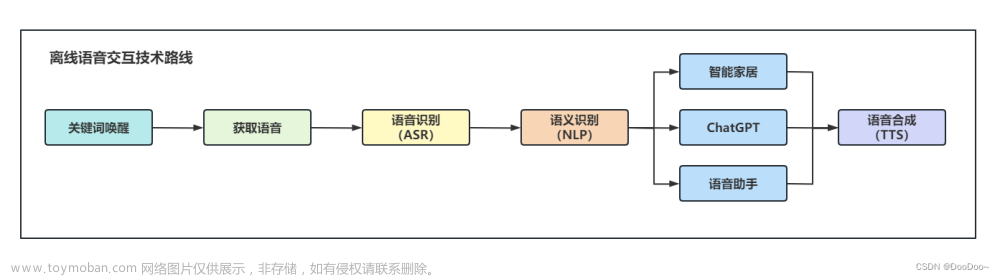
语音交互的几大部分组成
1.获得音频文件----->2.识别音频文件----->3.将音频文件转换为字符串------>4.进行其他相关操作(打开网址,语音对话,指挥机器人.....)
准备阶段,导入相关的库
import pyaudio
import wave
from aip import AipSpeech
import time
以及百度aip注册的密钥1.使用pyaudio借助电脑麦克风获得音频文件
# -*- coding = utf-8
# @Time : 2022/10/2011:43
# @Author : 夜路难行
# @File : record_sound.py
# @SoftWare : PyCharm
import pyaudio
import wave
CHUNK = 1024 #wav文件会将其分成好多个数据包/数据片段
CHANNELS = 1 #声道数
FORMAT= pyaudio.paInt16 #位化深度 2^16
RATE = 16000 #采样率
RECORD_SECONDS = 4
def record_sound(FILEPATH) :
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("开始录音,请说话......")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("录音结束...")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(FILEPATH, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()在此需要了解相关的音频知识:
声道数:支持能发出音响的个数
采样率:一秒钟对声音的采集次数
位化深度:
8bit (也就是1字节) 只能记录 256 个数, 也就是只能将振幅划分成 256 个等级;
16bit (也就是2字节) 可以细到 65536 个数, 这已是 CD 标准了;
32bit (也就是4字节) 能把振幅细分到 4294967296 个等级, 实在是没必要了.
paint16,相当于2^16,把音强分为65535个等级。
比特率:每秒的传输速度,kbps == Kilobit pre seconds ,比特率 = 声道数*位化深度*采样率,在百度aip的使用里面必须比特率为256kbps。
2.音频文件转化为字符串
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
#AIP语音识别
res = client.asr(get_file_content(FILEPATH),'wav',16000,{'dev-pid':15372,})
#提取字符
for key,val in res.items():
print(key,val)
#转化为列表
List = res.get('result')
#列表转化为字符串
string = '.'.join(List)这里是通过将百度aip转化后,返回的字典中,将键‘result’对应的值提取出来,然后将其转化为字符串。
dev-pid:对应的是不同语言的识别,这里可以去参考百度文档,找出自己需要的语言转换。
结合这两部就将语音转换完成了,后续的各项功能大家可以正常添加.....
3.语音唤醒
在网上查阅了相关资料发现,我没有找到windows系统下面的百度aip的语音唤醒,但是发现了科大讯飞的语音唤醒,但由于能力有限,目前不知道怎么将科大讯飞的语音唤醒和百度的语音交互联系起来,所以,想到了一个新的方案。文章来源:https://www.toymoban.com/news/detail-523042.html
借助语音识别的功能,设置关键词,当识别到关键词的时候进行语音识别功能文章来源地址https://www.toymoban.com/news/detail-523042.html
def huanxing(FilePath):
""" 你的 APPID AK SK """
APP_ID = '************'
API_KEY = '*************'
SECRET_KEY = '********'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
record_sound.record_sound(FilePath)
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# AIP语音识别
res = client.asr(get_file_content(FilePath), 'wav', 16000, {'dev-pid': 15372, })
# 提取字符
for key, val in res.items():
print(key, val)
# 转化为列表
List = res.get('result')
# 列表转化为字符串
string = '.'.join(List)
if string == '小黑小黑。' or string == '小黑,你好。':
return 1
else:
time.sleep(2)
print("唤醒失败...\n请重新开始语音唤醒")
huanxing('huanxing.wav')到了这里,关于python--基于百度aip的语音交互及语音唤醒的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[语音识别] 基于Python构建简易的音频录制与语音识别应用](https://imgs.yssmx.com/Uploads/2024/02/662057-1.png)



