改造原来的哈希桶
由于要使用一个哈希桶封装出unordered_map和uordered_set,所以要对哈希桶的模版参数进行改造,由于unordered_map是kv模型,而uordered_set是k模型,所以必须在实现哈希桶的时候提供模版,在封装uordered_set和unordered_map时传入不同的模版参数。
还要要修改的是,如果同时封装出,在获得key值时,unordered_map 和 unordered_set的key是不同的,所以必须传入不同仿函数来获得key值,为了后边在可以进行key比较。
namespace HashBucket
{
template<class T>
class HashNode
{
public:
typedef HashNode<T> Node;
HashNode(const T& data)
:_data(data)
,_next(nullptr)
{}
T _data;
Node* _next;
};
template<class K, class T, class Hash, class KeyOfT>
class HashTable;
template<class K, class T, class Hash,class KeyOfT>
class HashTable
{
public:
typedef HashNode<T> Node;
typedef iterator<K, T, Hash, KeyOfT> iterator;
iterator begin()
{
int i = 0;
while (!_tables[i])
{
i++;
}
return iterator(_tables[i], this);
}
iterator end()
{
return iterator(nullptr, this);
}
~HashTable()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
pair<iterator,bool> insert(const T& data)
{
Hash hash;
KeyOfT kot;
auto ret = find(kot(data));
if (ret!=end())
{
return make_pair(ret, false);
}
if (_size == _tables.size())
{
size_t NewSize = _tables.size() == 0 ? 10 : _tables.size() * 2;
vector<Node*> NewTables;
NewTables.resize(NewSize, nullptr);
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
if (cur)
{
Node* next = cur->_next;
size_t hashi = hash(kot(cur->_data)) % _tables.size();
cur->_next = NewTables[hashi];
NewTables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(NewTables);
}
size_t hashi = hash(kot(data)) % _tables.size();
Node* NewNode = new Node(data);
NewNode->_next = _tables[hashi];
_tables[hashi] = NewNode;
_size++;
return make_pair(iterator(NewNode,this), true);
}
iterator find(const K& key)
{
Hash hash;
KeyOfT kot;
if (_tables.size() == 0)
{
return end();
}
size_t hashi = hash(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur,this);
}
cur = cur->_next;
}
return end();
}
bool earse(const K& key)
{
Hash hash;
KeyOfT kot;
size_t hashi = hash(key) % _tables.size();
Node* prev = nullptr;
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_kv) == key)
{
if (cur == _tables[hashi])
{
_tables[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
--_size;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
private:
vector<Node*> _tables;
size_t _size = 0;
};
实现时要注意的问题
1.unordered_map和unordered_set的模版参数
unordered_map中的value值传入pair<K,V>,而unordered_set中的value值和key值相同。
2.KeyOfT仿函数
由于unordered_map的得到key值的方法和unordered_set获得可以值的方法不同,所以必须传入KeyOfT仿函数:
struct MapKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
struct MapKeyOfT
{
const K& operator()(const pair<K,V>& kv)
{
return kv.first;
}
};

3.string类型无法取模问题
由于在使用哈希函数为除留余数法时,会对key值进行取模,但是可能有的类型不支持取模,例如string,所以我们同样使用模版来解决,此时使用类模板来解决,同时对string类型进行类模板的特化:
template<class K>
class HashFunc
{
public:
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<>
class HashFunc<string>
{
public:
size_t operator()(const string& k)
{
size_t val = 0;
for (auto e : k)
{
val *= 131;
val += e;
}
return val;
}
};
哈希桶的迭代器实现
实现unordered_map和unordered_set的迭代器,即实现哈希桶的迭代器就可以了,最后对哈希桶的迭代器进行封装:
1.迭代器的结构
struct iterator
{
typedef HashTable<K, T, Hash, KeyOfT> HT;
typedef HashNode<T> Node;
HT* _Pht;
Node* _node;
};
迭代器的成员变量为一个节点的指针,另外还需要哈希表的地址。文章来源:https://www.toymoban.com/news/detail-523119.html
2.迭代器++
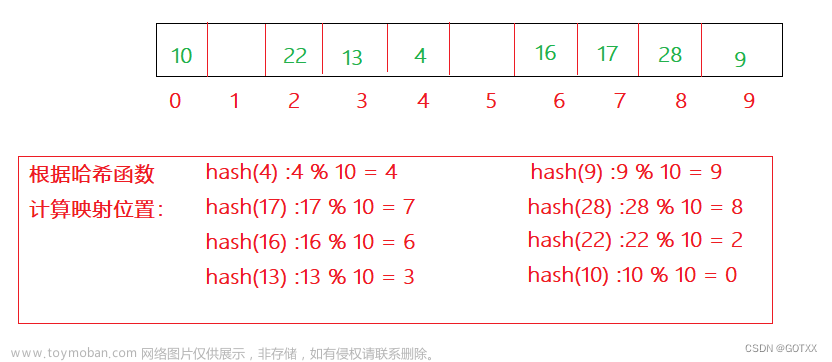
例如下边这个哈希桶:
使用迭代器后遍历顺序是这样的。
迭代器++的规则:
如果哈希表中某一处为空,就去拿表中节点,根据单链表的方式,向下遍历,直到遍历到单链表为空,为空后,继续在哈希表中查找不为空处,继续根据单链表的方式向下遍历。文章来源地址https://www.toymoban.com/news/detail-523119.html
代码实现
1.unordered_map
#pragma once
#include"hash.h"
namespace tmt
{
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<K,V>& kv)
{
return kv.first;
}
};
typedef typename HashBucket::HashTable<K,pair<K,V>,Hash,MapKeyOfT>::iterator iterator;
public:
bool insert(const pair<K,V>& kv)
{
return _HT.insert(kv);
}
iterator begin()
{
return _HT.begin();
}
iterator end()
{
return _HT.end();
}
V& operator[](const K& key)
{
pair<iterator,bool> ret = _HT.insert(make_pair(key,V()));
return ret.first->second;
}
private:
HashBucket::HashTable<K, pair<K,V>, Hash ,MapKeyOfT> _HT;
};
}
2.unordered_set
namespace tmt
{
template<class K, class V, class Hash = HashFunc<K>>
class unordered_set
{
struct MapKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
typedef typename HashBucket::HashTable<K, K, Hash, MapKeyOfT>::iterator iterator;
public:
bool insert(const K& key)
{
return _HT.insert(key);
}
iterator begin()
{
return _HT.begin();
}
iterator end()
{
return _HT.end();
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = _HT.insert(make_pair(key, V()));
return ret.first->second;
}
private:
HashBucket::HashTable<K, K , Hash, MapKeyOfT> _HT;
};
}
到了这里,关于【C++进阶】使用一个哈希桶封装出unordered_map和uordered_set的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[C++]哈希表实现,unordered_map\set封装](https://imgs.yssmx.com/Uploads/2024/02/475233-1.png)