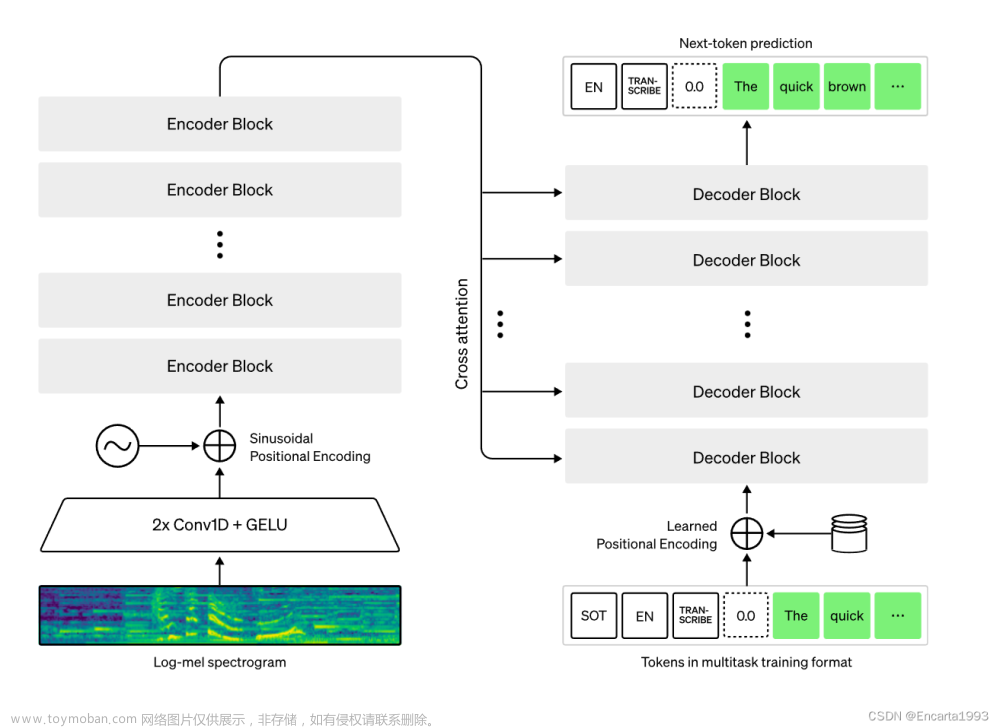
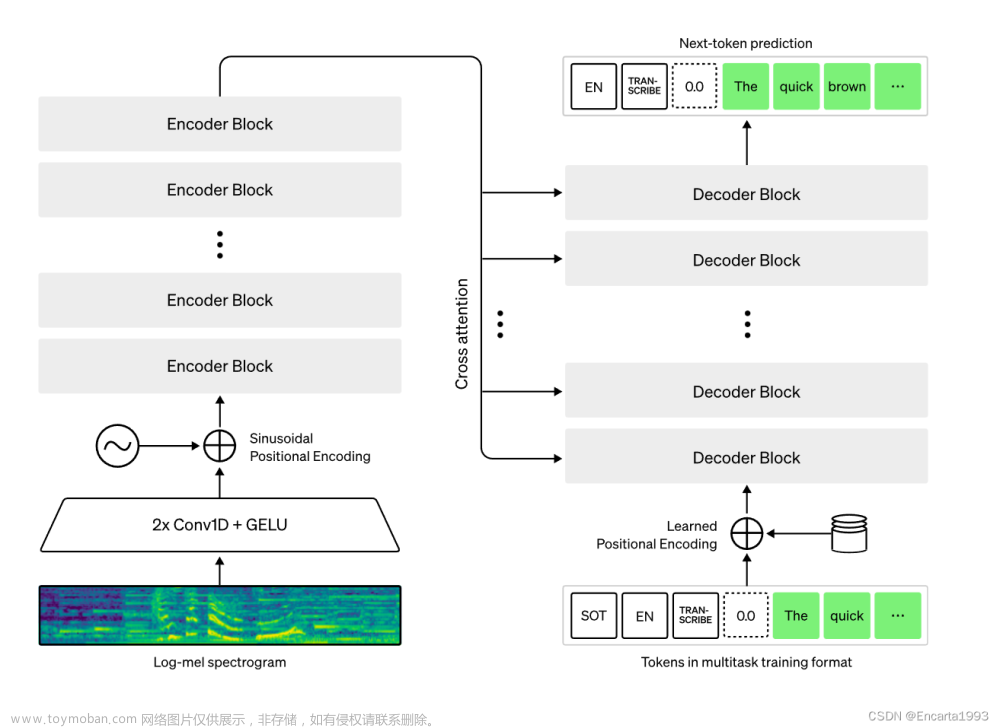
Whisper是一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练,能够在英语语音识别上达到接近人类水平的鲁棒性和准确性1。Whisper还可以进行多语言语音识别、语音翻译和语言识别等任务2。Whisper的架构是一个简单的端到端方法,采用了编码器-解码器的Transformer模型,将输入的音频转换为对应的文本序列,并根据特殊的标记来指定不同的任务2。
要使用Whisper模型,您需要安装Python 3.8-3.10和PyTorch 1.10.1或更高版本,以及一些其他的Python包,如HuggingFace Transformers和ffmpeg-python2。您还需要在您的系统上安装ffmpeg命令行工具2。您可以使用pip命令来安装或更新Whisper包,如下所示:
pip install -U openai-whisper
安装完成后,您可以使用edge_tts.Communicate类来创建一个Whisper对象,并调用其transcribe方法来对音频文件进行语音识别3。例如,以下代码可以对一个英语音频文件进行语音识别,并打印出结果:
import edge_tts tts = edge_tts.Communicate() result = tts.transcribe(‘english_audio.wav’) print(result)
如果您想对其他语言的音频文件进行语音识别或翻译,您可以在创建Whisper对象时指定language参数,如下所示:
tts = edge_tts.Communicate(language=‘zh-CN’) # for Chinese speech recognition tts = edge_tts.Communicate(language=‘zh-CN-en’) # for Chinese to English speech translation
更多关于Whisper模型和使用方法的细节,请参考以下链接:
Blog
Paper
Model card
Code
Colab example文章来源:https://www.toymoban.com/news/detail-523287.html
文章来源地址https://www.toymoban.com/news/detail-523287.html
到了这里,关于语音识别whisper的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!