引言
本着“凡我不能创造的,我就不能理解”的思想,本系列文章会基于纯Python以及NumPy从零创建自己的深度学习框架,该框架类似PyTorch能实现自动求导。
💡系列文章完整目录: 👉点此👈
要深入理解深度学习,从零开始创建的经验非常重要,从自己可以理解的角度出发,尽量不适用外部框架的前提下,实现我们想要的模型。本系列文章的宗旨就是通过这样的过程,让大家切实掌握深度学习底层实现,而不是仅做一个调包侠。
上篇文章中基于RNN作为编码器/解码器的seq2seq架构实现德语-英语的机器翻译。
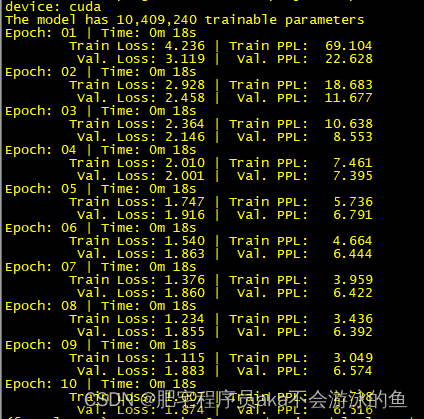
上篇文章中针对编码器生成的上下文向量的使用是作为解码器的初始向量,后续解码过程中无法直接使用。本文尝试让解码器的每个时间步都能看到这个上下文向量,并通过在测试集上验证效果。
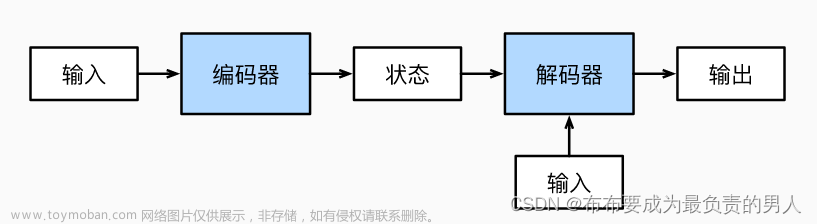
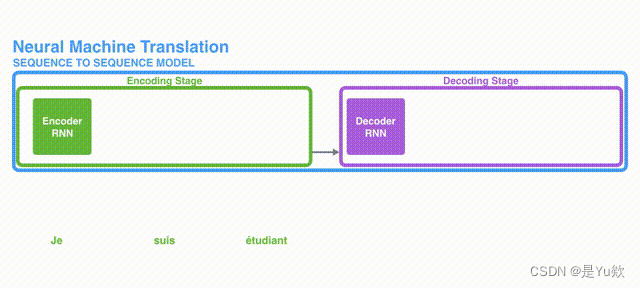
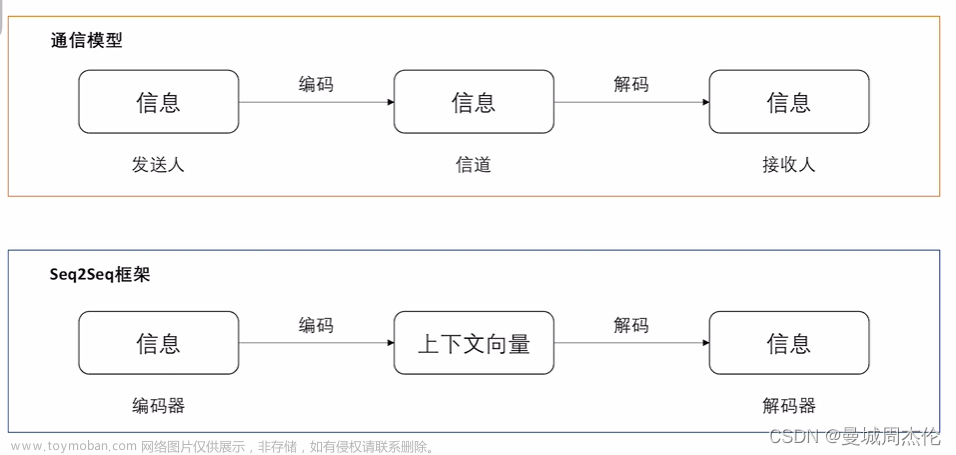
seq2seq简介
 文章来源:https://www.toymoban.com/news/detail-523371.html
文章来源:https://www.toymoban.com/news/detail-523371.html
上图是seq2seq翻译德语“早上好”的例子。源语句guten morgen首先经过嵌入层(黄色),然后输入到编码器(浅绿色)。为了表示句子的开头和结束,加入开文章来源地址https://www.toymoban.com/news/detail-523371.html
到了这里,关于从零实现深度学习框架——Seq2Seq模型尝试优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!