介绍
ChatGLM-6B是开源的文本生成式对话模型,基于General Language Model(GLM)框架,具有62亿参数,结合模型蒸馏技术,实测在2080ti显卡训练中上(INT4)显存占用6G左右,
优点:1.较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
2,更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM2-6B 序列长度达32K,支持更长对话和应用。
3,人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。目前已开源监督微调方法,
不足:1,模型容量较小: 6B 的小容量,决定了其相对较弱的模型记忆和语言能力,随着自己训练数据数量和轮次增加,会逐步丧失原来的对话能力,智谱ai于魁飞博士给的训练数据再好在1000条左右。
2,较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成,以及多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。解决方式:外挂知识库的形式,例如ChatGLM-6B 结合 langchain 实现本地知识库link
3,训练完自己的数据后,遗忘掉之前对话的能力,出现灾难性遗忘,解决办法在自己专业领域数据上可以加入通用开源的对话微调数据集一起训练,
制作不易,收藏关注哈,一起交流…
1,安装
1.1,ChatGLM2-6B官方开源的训练方式基于P-Tuning v2微调,
链接: git_link
基于QLoRA
链接: git_link
1.2,ChatGLM-6B基于P-Tuning v2微调,
链接: git_link
两个版本区别,文章末尾介绍
以下ChatGLM2-6B微调步骤
下载ChatGLM2-6B
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B
pip install -r requirements.txt
cd ptuning/
pip install rouge_chinese nltk jieba datasets
2, 使用自己数据集
2.1 构建自己的数据集
样例数据下载链接
链接: Dataset
将自己的数据集换成以下格式
{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
解释:构建数据集是一个 JSON 格式文件,其中一个列表中包含多个字典
{ “content”: “问句1”,
“summary”: "答案1“}
{ “content”: “问句1”,
“summary”: "答案1“}
{…}
2.2 修改 train.sh 和 evaluate.sh
修改 train.sh 和 evaluate.sh 中的 train_file、validation_file和test_file为你自己的 JSON 格式数据集路径,并将 prompt_column 和 response_column 改为 JSON 文件中输入文本和输出文本对应的 KEY。
我修改的train.sh示例如下:
## 切记如果粘贴我的这个示例代码,请删除注释
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=2 # 双卡
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_train \
--train_file di/train.json \ # 训练文件地址
--validation_file di/fval.json \ # 验证文件地址
--prompt_column content \ # 训练集中prompt名称
--response_column summary \ # 训练集中答案明细
--overwrite_cache \ # 重复训练一个训练集时候可删除
--model_name_or_path THUDM/chatglm-6b \ # 加载模型文件地址,可修改为本地路径,第五章讲怎么找
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \ # 保存训练模型文件地址
--overwrite_output_dir \
--max_source_length 64 \ # 最大输入文本的长度
--max_target_length 128 \
--per_device_train_batch_size 1 \ # batch_size 根据显存调节
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 2000 \ # 最大保存模型的步数
--logging_steps 10 \ # 打印日志间隔
--save_steps 500 \ # 多少部保存一次模型
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4 # 可修改为int8
参数具体解释
train.sh 中的 PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。
P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。
在默认配置 quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16 下,INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
2.3,开始训练
bash train.sh
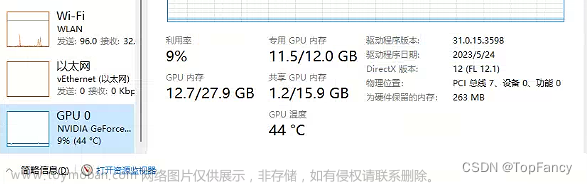
示例:两个显卡分别占用8.3G显存

3,验证模型
将 evaluate.sh 中的 CHECKPOINT 更改为训练时保存的 checkpoint 名称,运行以下指令进行模型推理和评测:
bash evaluate.sh
4,模型部署
3.1 自己验证 ,更换模型路径
将对应的demo或代码中的THUDM/chatglm2-6b换成经过 P-Tuning 微调之后 checkpoint 的地址(在示例中为 ./output/adgen-chatglm-6b-pt-8-1e-2/checkpoint-3000)。注意,目前的微调还不支持多轮数据,所以只有对话第一轮的回复是经过微调的。
在 P-tuning v2 训练时模型只保存 PrefixEncoder 部分的参数,所以在推理时需要同时加载原 ChatGLM-6B 模型以及 PrefixEncoder 的权重,因此需要指定 evaluate.sh 中的参数:
首先载入Tokenizer:
from transformers import AutoConfig, AutoModel, AutoTokenizer
# 载入Tokenizer
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
如果需要加载的 P-Tuning 的 checkpoint:
config = AutoConfig.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, pre_seq_len=128)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", config=config, trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join(CHECKPOINT_PATH, "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
# Comment out the following line if you don't use quantization
model = model.quantize(4) #或者8
model = model.half().cuda()
model.transformer.prefix_encoder.float()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
你也可以直接运行支持加载 P-Tuning v2 checkpoint 的 web demo
bash web_demo.sh
可能需要修改 web_demo.sh 的内容以符合你实际的 checkpoint 情况。
5,预训练模型地址一般存放位置在本机
本章第二步执行bash train.sh,终端会打印出模型加载的位置,找到位置后替换
一般存放的位置是
.cache/huggingface/hub/models–THUDM–chatglm-6b/snapshots/aa51e62ddc9c9f334858b0af44cf59b05c70148a/
查看包含这些目录
config.json configuration_chatglm.py modeling_chatglm.py pytorch_model.bin quantization.py
替换掉 demo.py 文件中THUDM/chatglm-6b为自己路径
6 如需要使用多轮对话数据对模型进行微调,可以提供聊天历史,例如以下是一个三轮对话的训练数据:
{"prompt": "长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "response": "用电脑能读数据流吗?水温多少", "history": []}
{"prompt": "95", "response": "上下水管温差怎么样啊?空气是不是都排干净了呢?", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"]]}
{"prompt": "是的。上下水管都好的", "response": "那就要检查线路了,一般风扇继电器是由电脑控制吸合的,如果电路存在断路,或者电脑坏了的话会出现继电器不吸合的情况!", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"], ["95", "上下水管温差怎么样啊?空气是不是都排干净了呢?"]]}
训练时需要指定 --history_column 为数据中聊天历史的 key(在此例子中是 history),将自动把聊天历史拼接。要注意超过输入长度 max_source_length 的内容会被截断。
可以参考以下指令:
bash train_chat.sh
7,遇到的问题和解决办法
7.1,出现一个问题了。 RuntimeError: Default process group has not been initialized, please make sure to call init_process_group.
训练的时候
估计transforms版本,我也遇到了,我回退到transformers==4.27.1 就可以了
7.2 ,问题:ValueError: Unable to create tensor, you should probably activate truncation and/or padding with ‘padding=True’ ‘truncation=True’ to have batched tensors with the same length. Perhaps your features 。。
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 16858) of binary
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
解决方式
显存不够,调小batch_size显存就可以了
8,ChatGLM2-6B和ChatGLM-6B区别
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。文章来源:https://www.toymoban.com/news/detail-523558.html
更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。文章来源地址https://www.toymoban.com/news/detail-523558.html
到了这里,关于ChatGLM2-6B、ChatGLM-6B 模型介绍及训练自己数据集实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!