x.1 Sequence model
经过前面的学习,我们已知数据大于算法。而以数据为驱动的前提下,我们提出了各种模型。为了适配表格数据,提出了MLP;为了适配图像数据提出了CNN;而对了适配序列数据,我们提出了RNN。
目前为止的数据的样本都符合iid独立同分布特点,但是对于音频,文本中的单词等,都是有顺序的,即他们是序列信息,并不符合独立同分布的特点。故本章节将考虑到时间动力学,根据文本信息处理文本数据。
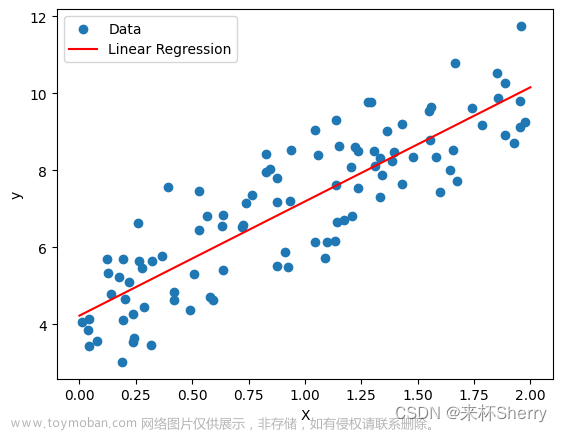
autoregressive model自回归模型:使用长度为tau的序列 {xt-1, …, xt-tau} 来预测xt时刻的结果。
latent autoregressive model隐变量自回归模型:在使用长度为tau的序列 {xt-1, …, xt-tau} 来预测xt时刻的结果的同时,还加入了对过去预测结果的总结。

Markov model马尔科夫模型:当我们使用的是长度为tau的序列进行预测,而不是一整个过去所有的序列进行预测,我们就说序列满足马尔科夫条件,当tau为1时就得到一阶马尔可夫模型,下式就是一阶的:

k-step-ahead-prediction k步预测:对于直到xt的观测序列{x1, … , xt},其在时间步t+k处的预测输出xt+k称为k步预测。即要用预测的数据进行多步预测,在误差累计后,precision精度会迅速下降。
x.2 将raw text文本信息转换为sequence data序列信息
这一步最重要的就是将text文本数据转为token。文章来源:https://www.toymoban.com/news/detail-524218.html
corpus语料库即text,存在很多重复的token,将text转成sequence data的本质就是将text转成token,再将token根据vocabulary映射成number。这之中的token的定义是:每一个时间步预测的timestep,是text中的原子组成部分,独一无二,最小单元。文章来源地址https://www.toymoban.com/news/detail-524218.html
到了这里,关于d2l_第九章_RNN循环神经网络的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!