一. 概论
1. 数据结构队列:一种遵循先进先出 (FIFO / First In First Out) 原则的一组有序的项;队列在尾部添加新元素,并从头部移除元素。最新添加的元素必须排在队列的末尾。(例如:去食堂排队打饭,排在前面的人先打到饭,先离开;排在后面的人后打到饭,后离开。)
栈:一种遵从先进后出 (LIFO) 原则的有序集合;新添加的或待删除的元素都保存在栈的末尾,称作栈顶,另一端为栈底。在栈里,新元素都靠近栈顶,旧元素都接近栈底。(例如:往口袋里面装东西,先装进去的放在最下面,后装进去的放在最上面,取出的时候只能从上往下取。)

链表:存储有序的元素集合,但不同于数组,链表中的元素在内存中并不是连续放置的;每个元素由一个存储元素本身的节点和一个指向下一个元素的引用(指针/链接)组成。
集合:由一组无序且唯一(即不能重复)的项组成;这个数据结构使用了与有限集合相同的数学概念,但应用在计算机科学的数据结构中。
字典:以 [键,值] 对为数据形态的数据结构,其中键名用来查询特定元素,类似于 Javascript 中的Object。
哈希表:根据关键码值(Key value)而直接进行访问的数据结构。通过把关键码值映射到表中某个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
树:由 n(n>=1)个有限节点组成一个具有层次关系的集合;把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的,基本呈一对多关系,树也可以看做是图的特殊形式。
图:图是网络结构的抽象模型;图是一组由边连接的节点(顶点);任何二元关系都可以用图来表示,常见的比如:道路图、关系图,呈多对多关系。
2. 算法
排序算法:冒泡排序(升序):逐一比较相邻两个元素,如果前面的元素比后面的元素大则交换两者顺序;元素项向上移动至正确的顺序,好似气泡上升至表面一般,因此得名。(冒泡排序每一轮至少有一个元素会出现在正确位置)
快速排序(升序):选择一个基准值,每一个元素与基准值比较。比基准值小的元素放在基准值左边,比基准值大的元素放在基准值右边,左右两边递归执行此操作。通常选择中间的元素作为基准值。
选择排序:每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,以此循环,直至排序完毕。
插入排序:将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,此算法适用于少量数据的排序。
归并排序:将原始序列切分成较小的序列,只到每个小序列无法再切分,然后执行合并,即将小序列归并成大的序列,合并过程进行比较排序,只到最后只有一个排序完毕的大序列,时间复杂度为 O(n log n)。
各种时间复杂度的直观比较:

搜索算法:顺序搜索:让目标元素与列表中的每一个元素逐个比较,直到找出与给定元素相同的元素为止,缺点是效率低下。
二分搜索:在一个有序列表,以中间值为基准拆分为两个子列表,拿目标元素与中间值作比较从而再在目标的子列表中递归此方法,直至找到目标元素。
其他算法:贪心算法:在对问题求解时,不考虑全局,总是做出局部最优解的方法。
动态规划:在对问题求解时,由以求出的局部最优解来推导全局最优解。
复杂度概念:一个方法在执行的整个生命周期,所需要占用的资源,主要包括:时间资源、空间资源。
二. 数据结构
队列概念:一种遵循先进先出 (FIFO / First In First Out) 原则的一组有序的项;队列在尾部添加新元素,并从头部移除元素。最新添加的元素必须排在队列的末尾。
在 Javascript 中实现一个队列类。
1.创建一个类:
class Queue{
constructor(items) {
this.items = items || []
}
// 1. 在末尾添加元素
enqueue(element){
this.items.push(element)
}
// 2. 在头部删除元素
dequeue(){
return this.items.shift()
}
// 3. 获取头部元素
front(){
return this.items[0]
}
// 4. 获取队列长度
get size(){
return this.items.length
}
// 5. 判断是否是空队列
get isEmpty(){
return !this.items.length
}
// 6. 清空队列
clear(){
this.items = []
}
}
2.使用类:
const queue = new Queue() // 类的实例化
queue.isEmpty // true
queue.enqueue('John') // {items: ['John']}
queue.enqueue('Jack') // {items: ['John','Jack']}
queue.enqueue('Camila') // {items: ['John','Jack','Camila']}
queue.size // 3
queue.isEmpty // false
queue.dequeue() // John
queue.dequeue() // Jack
queue.dequeue() // Camila
优先队列概念:元素的添加和移除是基于优先级的,不在满足完全意义的先进先出。例如机场登机的顺序,头等舱和商务舱乘客的优先级要高于经济舱乘客,这些乘客不需要通过正常排队登机。或是去医院看病,医生也会根据病情程度优先处理病情严重的。
在 Javascript 中实现一个队列类:
1.创建一个类:
class PriorityQueue {
constructor() {
this.items = []
}
enqueue(element, priority){
const queueElement = { element, priority }
if (this.isEmpty) {
this.items.push(queueElement)
} else {
// 在列表中找到第一个比后进入的元素的priority大的元素的位置,如果有,将这个元素插入这里。如果没有,将这个元素放在最后面。
const preIndex = this.items.findIndex((item) => queueElement.priority < item.priority)
if (preIndex > -1) {
this.items.splice(preIndex, 0, queueElement)
} else {
this.items.push(queueElement)
}
}
}
dequeue(){
return this.items.shift()
}
front(){
return this.items[0]
}
clear(){
this.items = []
}
get size(){
return this.items.length
}
get isEmpty(){
return !this.items.length
}
print() {
console.log(this.items)
}
}
2.使用类:
const priorityQueue = new PriorityQueue()
priorityQueue.enqueue('Wangjiajia', 2) // {items: [{element: 'Wangjiajia', priority: 2}]}
priorityQueue.enqueue('Wangtongtong', 1) // {items: [{element: 'Wangtongtong', priority: 1},{element: 'Wangjiajia', priority: 2}]}
priorityQueue.enqueue('Davide', 4) // {items: [{element: 'Wangtongtong', priority: 1},{element: 'Wangjiajia', priority: 2},{element: 'Davide', priority: 4}]}
priorityQueue.enqueue('Tom', 3) // {items: [{element: 'Wangtongtong', priority: 1},{element: 'Wangjiajia', priority: 2},{element: 'Tom', priority: 3},{element: 'Davide', priority: 4}]}
priorityQueue.enqueue('James', 2) // {items: [{element: 'Wangtongtong', priority: 1},{element: 'Wangjiajia', priority: 2},{element: 'James', priority: 2},{element: 'Tom', priority: 3},{element: 'Davide', priority: 4}]}
循环队列概念:为充分利用向量空间,克服"假溢出"现象将向量空间想象为一个首尾相接的圆环,并称这种向量为循环向量。存储在其中的队列称为循环队列(Circular Queue)。通俗来说:循环队列是把顺序队列首尾相连,把存储队列元素的表从逻辑上看成一个环,成为循环队列。假溢出: 队列的空间未利用完,但是却造成了元素的溢出。
基于首次实现的队列类,简单实现一个循环引用的示例:
class LoopQueue extends Queue {
constructor(items) {
super(items)
}
getIndex(index) {
const length = this.items.length
return index > length ? (index % length) : index
}
find(index) {
return !this.isEmpty ? this.items[this.getIndex(index)] : null
}
}
使用:
const loopQueue = new LoopQueue(['Surmon'])
loopQueue.enqueue('SkyRover')
loopQueue.enqueue('Even')
loopQueue.enqueue('Alice')
console.log(loopQueue.size, loopQueue.isEmpty) // 4 false
(loopQueue.find(26) // 'Evan'
(loopQueue.find(87651) // 'Alice'
栈:概念:一种遵从先进后出 (LIFO) 原则的有序集合;新添加的或待删除的元素都保存在栈的末尾,称作栈顶,另一端为栈底,出去的时候从栈顶开始出去。在栈里,新元素都靠近栈顶,旧元素都接近栈底。`
用javascript基于数组的方法实现一个栈的功能:
class Stack {
constructor() {
this.items = []
}
// 入栈
push(element) {
this.items.push(element)
}
// 出栈
pop() {
return this.items.pop()
}
// 末位
get peek() {
return this.items[this.items.length - 1]
}
// 是否为空栈
get isEmpty() {
return !this.items.length
}
// 尺寸
get size() {
return this.items.length
}
// 清空栈
clear() {
this.items = []
}
// 打印栈数据
print() {
console.log(this.items.toString())
}
}
使用栈:
// 实例化一个栈
const stack = new Stack()
console.log(stack.isEmpty) // true
// 添加元素
stack.push(5) // [5]
stack.push(8) // [5,8]
// 读取属性再添加
console.log(stack.peek) // 8
stack.push(11) // [5,8,11]
stack.pop() // 11
console.log(stack.size) // 3
console.log(stack.isEmpty) // false
链表:概念:存储有序的元素集合,但不同于数组,链表中的元素在内存中并不是连续放置的;每个元素由一个存储元素本身的节点和一个指向下一个元素的引用(指针/链接)组成。分类:单向链表,双向链表,循环链表链表和数组的区别:
* 数组在添加或者删除元素的时候需要移动其他元素,链表不需要。链表需要使用指针,因此使用的时候需要额外注意一下。
* 数组可以访问其中任何一个元素,链表需要从头开始迭代,直到找到所需的元素。
链表的常见方法:1、append(element):向列表尾部添加一个新的项2、insert(position, element):向列表的特定位置插入一个新的项。3、remove(element):从列表中移除一项。4、removeAt(position):从列表的特定位置移除一项。5、indexOf(element):返回元素在列表中的索引。如果列表中没有该元素则返回-1。6、getElementAt(index): 返回链表中特定位置的元素, 如果不存在这样的元素则返回undefined7、isEmpty():如果链表中不包含任何元素,返回true,如果链表长度大于0则返回false。8、size():返回链表包含的元素个数。与数组的length属性类似。9、toString():由于列表项使用了Node类,就需要重写继承自JavaScript对象默认的toString方法,让其只输出元素的值element。
整体操作方法和数组非常类似, 因为链表本身就是一种可以代替数组的结构.使用javascript描述一个单向链表:
单向链表:
生活中的例子:火车就可以看做链表,每一节都是由一节车厢和车厢之间的连接带组成,这个连接带就可以看成是指针。
用javascript来描述一个单向链表:
// 链表节点
class Node {
constructor(element) {
this.element = element
this.next = null
}
}
// 单向链表
class LinkedList {
constructor() {
this.head = null
this.length = 0
}
// 1. 追加元素
// 向链表尾部追加数据可能有两种情况:
// 链表本身为空, 新添加的数据是唯一的节点.
// 链表不为空, 需要向其他节点后面追加节点.
append(element) {
const node = new Node(element)
let current = null
// 链表本身为空, 新添加的数据是唯一的节点.
if (this.head === null) {
this.head = node
} else {
// 链表不为空, 需要向其他节点后面追加节点.
current = this.head
while(current.next) {
current = current.next
}
current.next = node
}
this.length++
}
// 2. 任意位置插入元素
insert(position, element) {
// 1.检测越界问题: 越界插入失败, 返回false
if (position < 0 || position > this.length) return false
// 2.找到正确的位置, 并且插入数据
// 定义要插入的变量newNode, current当前节点, previous上一个节点
let newNode = new Node(element)
let current = this.head // 初始值为head, 对第一个元素的引用
let previous = null // 存储当前current的上一个节点
let index = 0 // 位置
// 3.判断是否列表是否在第一个位置插入
if (position == 0) {
newNode.next = current
this.head = newNode
} else {
while (index++ < position) { // 向前赶, 直到找到当前位置position
previous = current
current = current.next
}
// index === position, 找到要插入的位置
newNode.next = current
previous.next = newNode
}
// 4.length+1
this.length++
}
// 3. 从链表中任意移除一项
removeAny(position) {
//边界检查,越界返回false
if(position < 0 || position > this.length-1){
return false
}
let current = this.head
let previous = null
let index = 0
// 如果删除第一个元素
if(position == 0){
this.head = current.next
}else{
// 不是删除第一个找到删除的位置
while(index++ < position){
previous = current
current = current.next
}
previous.next = current.next
}
this.length--
return current.element
}
// 4. 寻找元素下标
findIndex(element) {
let current = this.head
let index = 0
//遍历链表直到找到data匹配的position
while (current) {
if (element === current.element) {
return index
}
current = current.next
index++
}
return false
}
// 5. 从链表的特定位置移除一项。
remove(element) {
const index = this.indexOf(element)
return this.removeAt(index)
}
// 6. 判断是否为空链表
isEmpty() {
return !this.length
}
// 7. 获取链表长度
size() {
return this.length
}
// 8. 转为字符串
toString() {
let current = this.head
let str = ''
while (current) {
str += ` ${current.element}`
current = current.next
}
return str
}
}
链表类的使用:
const linkedList = new LinkedList()
console.log(linkedList) // LinkedList {head: null, length: 0}
// 1. 在末尾追加元素
linkedList.append(2) // LinkedList {head: {element:2,next:null}, length: 1}
linkedList.append(4) // LinkedList {head: {element:2,next:{element:4,next:null}}, length: 2}
linkedList.append(6) // LinkedList {head: {element:2,next:{element:4,next:{element:6,next:null}}}, length: 3}
// 2. 在任意位置插入一个元素
linkedList.insert(2, 18) // LinkedList {head: {element:2,next:{element:4,next:{element:18,next:{element:6,next:null}}}}, length: 4}
// 3. 从链表中任意位置删除一项
linkedList.removeAny(2) // 18
// 4. 寻找元素下标
linkedList.findIndex(6) // 2
linkedList.findIndex(18) // false
linkedList.findIndex(20) // false
// 5. 从链表的特定位置移除一项。
linkedList.remove(4)
// 6. 判断是否为空链表
linkedList.isEmpty() // false
// 7. 获取链表长度
linkedList.size() // 2
// 8. 转为字符串
linkedList.toString() // ' 2 4 18 6'
双向链表:概念:双向链表和普通链表的区别在于,在链表中, 一个节点只有链向下一个节点的链接,而在双向链表中,链接是双向的:一个链向下一个元素, 另一个链向前一个元素,如下图所示:
使用javacsript来实现一个双向链表类:
class Node{
constructor(element){
this.element = element
this.next = null
this.prev = null
}
}
// 双向链表
class DoublyLinkedList {
constructor() {
this.head = null
this.tail = null
this.length = 0
}
// 1. 任意位置插入
insert(position,element){
// 1.1 检测越界问题: 越界插入失败, 返回false
if (position < 0 || position > this.length) return false
let newNode = new Node(element)
let current = this.head // 初始值为head, 对第一个元素的引用
let previous = null // 存储当前current的上一个节点
let index = 0 // 位置
// 1.2 如果插在了首位
if(position == 0){
// 空链表
if(!head){
this.head = node
this.tail = node
}else{
this.head = node
node.next = current
current.prev = node
}
}
// 1.3 如果插在了末位
else if(position == this.length) {
this.tail = node
current.next = node
node.prev = current
}else {
// 如果插在了中间位置
// 找到插入的位置
while(idex++ < position){
previous = current
current = current.next
}
// 插入进去
node.next = current
previous.next = node
node.pre = previous
current.pre = node
this.length++
return true
}
}
// 2. 移除任意位置元素
removeAny(position){
// 2.1 边界检查,越界返回false
if(position < 0 || position > this.length-1) return false
let current = this.head
let previous = null
let index = 0
// 2.2 如果删除的是首位
if(position == 0){
this.head = current.next
this.head.prev = null
}else if(position == this.length - 1){
// 2.3 如果删除的是末位
this.tail = current.pre
this.tail.next = null
}else {
// 2.4 中间项
// 找到删除的位置
while(index++ < position){
previous = current
current = current.next
}
previous.next = current.next
current.prev = current.next.prev
this.length--
return current.element
}
}
}
循环链表:概念:循环链表可以像单向链表一样只有单向引用,也可以向双向链表一样具有双向引用。单向循环链表:最后一个元素指向下一个元素的指针(tail.next)不是引用null, 而是指向第一个元素(head),如下图所示:
双向循环链表:最后一个元素指向下一个元素的指针tail.next不是nul,而是指向第一个元素(head),同时第一个元素指向前一个元素的指针head.prev不是null,而是最后一个元素tail。如图所示:
链表的优势:无需移动链表中的元素,就能轻松地添加和移除元素。因此,当你需要添加和移除很多元素 时,最好的选择就是链表,而非数组。
集合:概念:集合是由一组无序且唯一(不能重复)的项组成的。目前在ES6中已经内置了Set的实现。集合中常用的一些方法:
add() 添加元素
delete() 删除元素,返回布尔值,删除成功返回true,删除失败返回false
has() 判断是否含有某个元素,返回布尔值
clear() 清空set数据结构
size 没有括号,返回此结构长度
在ES6中使用集合:
const arr = [1,2,2,3,3,3,4,4,5]
const str = 'wangjiajiawwwjiajiawwwww'
// 1.添加元素
new Set(arr) // Set{1,2,3,4,5}
new Set(str ) // Set{'w', 'a', 'n', 'g', 'j', 'i'}
new Set(arr).add(8) // Set{1,2,3,4,5,8}
// 2.删除元素
new Set(arr).delete(2) // true
new Set(arr).delete(9) // false
// 3.判断是否含有某个元素
new Set(arr).has(2) // true
new Set(arr).has(9) // false
// 4.清空set数据结构
new Set(arr).clear() // undefined
// 5.没有括号,返回此结构长度
new Set(arr).size // 5
在javascript中使用集合:
// hasOwnProperty(propertyName)方法 是用来检测属性是否为对象的自有属性,如果是,返回true,否则返回false; 参数propertyName指要检测的属性名;
// hasOwnProperty() 方法是 Object 的原型方法(也称实例方法),它定义在 Object.prototype 对象之上,所有 Object 的实例对象都会继承 hasOwnProperty() 方法。
class Set {
constructor() {
this.items = {}
}
has(value) {
return this.items.hasOwnProperty(value)
}
add(value) {
if (!this.has(value)) {
this.items[value] = value
return true
}
return false
}
remove(value) {
if (this.has(value)) {
delete this.items[value]
return true
}
return false
}
get size() {
return Object.keys(this.items).length
}
get values() {
return Object.keys(this.items)
}
}
const set = new Set()
set.add(1)
console.log(set.values) // ["1"]
console.log(set.has(1)) // true
console.log(set.size) // 1
set.add(2)
console.log(set.values) // ["1", "2"]
console.log(set.has(2)) // true
console.log(set.size) // 2
set.remove(1)
console.log(set.values) // ["2"]
console.log(set.has(1)) // false
set.remove(2)
console.log(set.values) // []
对集合可以执行如下操作:并集:对于给定的两个集合,返回一个包含两个集合中所有元素的新集合。交集:对于给定的两个集合,返回一个包含两个集合中共有元素的新集合。差集:对于给定的两个集合,返回一个包含所有存在于第一个集合且不存在于第二个集合的元素的新集合。
并集:
并集的数学概念:集合A和B的并集,表示为A∪B,定义如下:A∪B = { x | x∈A V x∈B },意思是x(元素)存在于A中,或x存在于B中。如图:

基于刚才的 Set 类实现一个并集方法:
union(otherSet) {
const unionSet = new Set()
// 先添加其中一个集合的元素放在unionSet中
this.values.forEach((v, i) => unionSet.add(this.values[i]))
// 在把另一个集合的元素放入unionSet中
otherSet.values.forEach((v, i) => unionSet.add(otherSet.values[i]))
return unionSet
}
交集:
并集的数学概念:集合A和B的交集,表示为A∩B,定义如下:A∩B = { x | x∈A ∧ x∈B },意思是x(元素)存在于A中,且x存在于B中。如图:

基于刚才的 Set 类实现一个交集方法:
intersection(otherSet) {
const intersectionSet = new Set()
// 从集合A开始循环判断,如果这个元素也在集合B中,那就说明这个元素是集合A,B公有的。这时候把这个元素放到一个新的集合中
this.values.forEach((v, i) => {
if (otherSet.has(v)) {
intersectionSet.add(v)
}
})
return intersectionSet
}
差集:
差集的数学概念:集合A和B的差集,表示为A-B,定义如下:A-B = { x | x∈A ∧ x∉B },意思是x(元素)存在于A中,且不x存在于B中。如图:
基于刚才的 Set 类实现一个差集 A-B 的方法:
difference(otherSet) {
// 从集合A开始循环判断,如果这个元素不在集合B中。说明这个元素是A私有的,此时把这个元素放入一个新的集合中。
const differenceSet = new Set()
this.values.forEach((v, i) => {
if (!otherSet.has(v)) {
differenceSet.add(v)
}
})
return differenceSet
}
子集:
子集的数学概念:集合A是B的子集,或者说集合B包含了集合A,如图:
基于刚才的 Set 类实现一个子集方法:
// 在这里this代表集合A,otherSet代表集合B
subset(otherSet){
if(this.size > otherSet.size){
return false
}else{
// 只要A里面有一个元素不在B里面就说明A不是B的子集,后面元素不用在判断了
this.values.every(v => !otherSet.has(v))
}
}
字典:
集合、字典、散列表都可以存储不重复的数据。字典以键值对的形式存储数据,类似于javascript中的Object对象。
在javascript中实现字典:
class Dictionary {
constructor() {
this.items = {}
}
set(key, value) {
this.items[key] = value
}
get(key) {
return this.items[key]
}
remove(key) {
delete this.items[key]
}
get keys() {
return Object.keys(this.items)
}
get values() {
/*
也可以使用ES7中的values方法
return Object.values(this.items)
*/
// 在这里我们通过循环生成一个数组并输出
return Object.keys(this.items).reduce((r, c, i) => {
r.push(this.items[c])
return r
}, [])
}
}
使用字典:
const dictionary = new Dictionary()
dictionary.set('Wangjiajia', 'Wangjiajia@email.com')
dictionary.set('Wangtongtong', 'Wangtongtong@email.com')
dictionary.set('davide', 'davide@email.com')
console.log(dictionary) // {items:{'Wangjiajia', 'Wangjiajia@email.com','Wangtongtong', 'Wangtongtong@email.com','davide', 'davide@email.com'}}
console.log(dictionary.keys) // ['Wangjiajia','Wangtongtong','davide']
console.log(dictionary.values) // [Wangjiajia@email.com','Wangtongtong@email.com','davide@email.com']
console.log(dictionary.items) // {'Wangjiajia': 'Wangjiajia@email.com','Wangtongtong': 'Wangtongtong@email.com','davide':'davide@email.com'}
哈希表:
-
根据关键码值(Key value)而直接进行访问的数据结构。通过把关键码值映射到表中某个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫散列表。 给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
哈希表示意图:
哈希表冲突:当通过哈希函数取得一个哈希值时,很有可能这个值的下标所处的位置上已经存放过数据,这时候便出现冲突。解决冲突:链地址法、开放地址法。
在javascript中实现哈希表:
function HashTable(){
// 初始化哈希列表
// 1. 设置哈希表数组
this.item = []
// 2. 设置哈希表长度
this.limit = 10
// 3. 设置表中数据量
this.total = 0
// 设置哈希函数
HashTable.prototype.hashFunc = function(key, limit){
let keyvalue = 0
for(let i=0; i<key.length; i++){
keyvalue=keyvalue * 12 + key.charCodeAt(i)
}
//使用取余运算计算hashCode
return keyvalue%limit
}
// 增、改
HashTable.prototype.put = function(key, value){
// 根据hashCode找到对应下标修改或者添加数据
let index = this.hashFunc(key, this.limit)
let arr = this.item[index]
// 如果这个下标所处的位置已经存放过数据,即arr有值,此时存在哈希表冲突
if(arr){
let completed = false
// 遍历数组,如果发现重名数据则直接修改
arr.forEach(item=>{
if(key===item[0]){
completed = true
return item[1] = value
}
})
// 如果没有重名则在末尾添加新数据
if(!completed){
arr.push([key, value])
this.total++
}
}else{
//如果basket为null则重新创建数组
this.item[index] = [[key, value]]
this.total++
}
}
// 查
HashTable.prototype.get = function(key){
let index = this.hashFunc(key, this.limit)
let basket = this.item[index]
//如果basket为null则没有对应数据
if(basket===undefined){
return null
}else{
//如果有basket, 则遍历basket,遍历完没有对应key则不存在对应数据
for(let i = 0; i < basket.length; i++){
if(key===basket[i][0]) return basket[i][1]
}
return null
}
}
// 删
HashTable.prototype.remove = function(key){
let index = this.hashFunc(key, this.limit)
let basket = this.item[index]
//如果basket为null则没有对应数据
if(!basket){
return null
}else{
//如果有basket, 则遍历basket,遍历完没有对应key则不存在对应数据
for(let i = 0; i < basket.length; i++){
if(key===basket[i][0]){
this.total--
return basket.splice(i, 1)
}
}
return null
}
}
//求表长
HashTable.prototype.size = function(){
return this.total
}
//判断表空
HashTable.prototype.isEmpty = function(){
return this.total===0
}
}
树:
-
概念:是一种天然具有递归属性的非顺序数据结构,是一种特殊的图(无向无环)。由n个节点组成,具有一定的层级关系。 -
根结点:树的最顶端的节点,根节点只有一个 -
子节点:除根节点之外,并且本身下面还连接有节点的节点。 -
叶子结点:自己下面不再连接有节点的节点(即末端),称为叶子节点(又称为终端结点),度为0 -
深度:节点到根结点的节点数量
-
高度:所有节点深度中的最大值
-
普通树:

-
二叉树:
- 树的每个节点最多只能有两个子节点
- 二叉树可以为空,也就是没有任何节点,如果不为空它是由左右子树两个不相交的二叉树组成。

-
二叉搜索树:
- 非空左子树的键值要小于根结点的键值
- 非空右子树的键值要大于根结点的键值
- 左右子树都要是二叉搜索树

-
满二叉树与完全二叉树
满二叉树是每一个节点都有两个子节点,左右子树呈对称趋势。完全二叉树有的分支不完全对称。
-
红黑二叉树
红黑二叉树本质上就是一种二叉搜索树,在插入和删除等操作的时候通过特定操作保持二叉树的平衡。红黑二叉树本身是复杂的,但它的最坏情况运行时间也是非常良好的,并且在实践中是高效的:它可以在O(log n)时间内做查找,插入和删除,这里的 n 是树中元素的数目。
红黑二叉树在二叉搜索树的基础上必须满足以下要求:- 节点必须是红色的或者黑色的
- 根结点必须是黑色的
- 如果节点是红色的,那么他的子节点必须是黑色的(反之未必)
- 从根节点到任意一个叶子结点不能有两个连续的红色节点
- 从任意节点开始到他的每一个叶子节点,所有路线上的黑色节点数目相同

用javascript实现二叉树的一些操作:
// 封装二叉树节点
class Node {
constructor(data){
this.data = data
this.left = null
this.right = null
}
}
// 封装二叉搜索树
class BinarySearchTree {
constructor(){
this.root = null // 定义二叉树根节点
}
// 插入节点
insert(key){
const newNode = new Node(key)
// 定义插入节点的函数,比根节点小的放左边,比根节点大的放右边
function insertNode(node, newNode){
if(newNode.key < node.key){
// 判断根节点的左侧是否有节点,如果没有节点则直接插入,如果有节点则递归执行insertNode函数
if(node.left == null){
node.left = newNode
}else{
insertNode(node.left, newNode)
}
}else{
// 判断根节点的右侧是否有节点,如果没有节点则直接插入,如果有节点则递归执行insertNode函数
if(node.right == null){
node,right = newNode
}else{
insertNode(node.right, newNode)
}
}
}
// 如果是空二叉树,则插入的节点就是根节点,否则正常插入
if(!this.root){
this.root = newNode
}else{
insertNode(this.root, newNode)
}
}
}
二叉搜索树类的使用:
const tree = new BinarySearchTree()
tree.insert(11)
tree.insert(7)
tree.insert(5)
tree.insert(3)
tree.insert(9)
tree.insert(8)
tree.insert(10)
tree.insert(15)
tree.insert(13)
tree.insert(12)
tree.insert(14)
tree.insert(20)
tree.insert(18)
tree.insert(25)

二叉树的遍历:访问树的每一个节点并对他们进行某种操作的过程
-
前序遍历:先访问根节点,再访问左节点,最后访问右节点(左右子树同样进行该操作,根左右) -
中序遍历:先访问左节点,再访问根节点,最后访问右结点,(左根右) -
后序遍历:先访问左节点,再访问右节点,最后访问根节点。(左右根)
前序遍历:
function preorder(root){
// 排除根节点为空的情况
if(!root) return
// 1. 访问根节点
console.log(root.key) // 11 7 5 3 6 9 8 10 15 13 12 14 20 18 25
// 2. 递归对根节点的左子树进行先序遍历
preorder(root.left)
// 3. 递归对根节点的右子树进行先序遍历
preorder(root.right)
}
preorder(tree)

中序遍历:
const inorder = (root) => {
if(!root) return
// 1. 递归对根节点的左子树进行中序遍历
inorder(root.left)
// 2. 访问根节点
console.log(root.key) // 3 5 6 7 8 9 10 11 12 13 14 15 18 20 25
// 3. 递归对根节点的右子树进行中序遍历
inorder(root.right)
}
inorder(tree)

后序遍历:
const postorder = (root) => {
if (!root) return
// 1. 递归对根节点的左子树进行后序遍历
postorder(root.left)
// 2. 递归对根节点的左子树进行后序遍历
postorder(root.right)
// 3. 访问根节点
console.log(root.key) // 3 6 5 8 10 9 7 12 14 13 18 25 20 15 11
}
postorder(tree)

搜索最小值和最大值:
最小值在最左边,最大值在最右边
function minNum(node) {
const minNode = node => {
return node ? (node.left ? minNode(node.left) : node.key) : null
}
return minNode(node || this.root)
}
function maxNum(node) {
const maxNode = node => {
return node ? (node.right ? maxNode(node.right) : node.key) : null
}
return maxNode(node || this.root)
}
minNum(tree.root) // 3
maxNum(tree.root) // 25
搜索特定的值:
function search(node,key){
const searchNode = (node,key)=>{
if(node === null)return false
if(node.key === key) return true
return searchNode( key < node.key ? node.left : node.right, key)
}
return searchNode(node, key)
}
search(tree.root,3) // true
search(tree.root,3) // false
图:
- 概念:由一组顶点和连接顶点之间的边所组成的数据结构
- 表示方法: G=(V, E) V是图G中顶点的集合,E是图G中边的集合。
无向图:连接顶点的边没有方向
说明:由一条边连接起来的顶点,称为相邻顶点,比如A和B是相邻的,A和D是相邻的,A和C 是相邻的,A和E不是相邻的。一个顶点的度,是其相邻顶点的数量。例如:A的度为3,E的度为2。如果存在环称为有环图,如果每两个顶点之间都存在路径,则称图是连通的。
有向图:连接顶点的边有方向
说明: 如果图中每两个顶点间在双向上都存在路径,则该图是强连通的。例如,C和D是强连通的, 而A和B不是强连通的。
加权图:图的边被赋予了权值
图的表示方法:
- 邻接矩阵
- 邻接表
邻接矩阵:
1. 可以通过一个二维数组来表示图的结构
2. 当图为稀疏图时这个二维数组许多的空间都会被赋值为0,浪费计算机存储空间
3. 邻接矩阵示意图
说明:用一个二维数组表示,如果这两个顶点相邻,那么这个值就记为1,否则记为0。这种方法可能会记录很多0,造成计算机性能的浪费。因为即使这个顶点只有一个相邻顶点,我们也要迭代一整行。例如:上面I顶点。
邻接表:由一个顶点以及跟这个顶点相邻的其他顶点列表组成,能够减少内存消耗。
使用javascript创建图:
class Graph {
constructor(){
this.vertices = [] // 用来保存顶点的数组
this.adjList = {} // 用来保存边的字典,可以直接用一个对象代替。
}
// 添加顶点
addVertex(v){
this.vertices.push(v)
this.adjList[v] = []
}
// 添加边
addEdge(v,w){
this.adjList[v].push(w)
this.adjList[w].push(v)
}
// 返回字符串
graphToString(){
return this.vertices.reduce((r,v) => {
return this.adjList[v].reduce((r,w) => {
return r + `${w}`
},`${r}\n${v} => `)
},'')
}
}
const graph = new Graph();
['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I'].forEach(c => graph.addVertex(c))
graph.addEdge('A', 'B')
graph.addEdge('A', 'C')
graph.addEdge('A', 'D')
graph.addEdge('C', 'D')
graph.addEdge('C', 'G')
graph.addEdge('D', 'G')
graph.addEdge('D', 'H')
graph.addEdge('B', 'E')
graph.addEdge('B', 'F')
graph.addEdge('E', 'I')
console.log(graph.graphToString())

图的遍历:将图的每个顶点访问一次,并且不能有重复的访问
- 广度优先遍历(Breadth-first-search BFS)
- 深度优先遍历(Depth-first-search DFS)
广度优先遍历:队列,通过将顶点存入队列中,最先入队列的顶点先被探索。广度优先搜索算法会从指定的第一个顶点开始遍历图,先访问其所有的相邻点,就像一次访问图的一层。简单说,就是一层一层地访问顶点,如下图所示:
在javascript中实现广度优先遍历:
breadthFirst(v, callback) {
const read = []
const adjList = this.adjList
let pending = [v || this.vertices[0]]
const readVertices = vertices => {
vertices.forEach(key => {
read.push(key)
pending.shift()
adjList[key].forEach(v => {
if (!pending.includes(v) && !read.includes(v)) {
pending.push(v)
}
})
if (callback) callback(key)
if (pending.length) readVertices(pending)
})
}
readVertices(pending)
}

深度优先遍历:深度优先搜索算法将会从第一个指定的顶点开始遍历图,沿着路径直到这条路径最后一个顶 点被访问了,接着原路回退并探索下一条路径。换句话说,它是先深度后广度地访问顶点,如下图所示:
在javascript中实现深度优先遍历:
deepFirst(callback) {
const read = []
const adjList = this.adjList
const readVertices = vertices => {
vertices.forEach(key => {
if (read.includes(key)) return false
read.push(key)
if (callback) callback(key)
if (read.length !== this.vertices.length) {
readVertices(adjList[key])
}
})
}
readVertices(Object.keys(adjList))
}

算法:
排序算法:1.冒泡排序:冒泡排序比较任何两个相邻的项,如果第一个比第二个大,则交换它们。最坏的情况下比较n轮,n为数组的长度。
const arr = [2,4,1,9,8,7,6,5,3]
function bubbleSort(arr){
if(!Array.isArray(arr)){
console.log('请输入一个数组!')
return false
}
const len = arr.length
for(let i=0; i<len; i++){
for(let j=0; j<len - i; j++){
if(arr[j] > arr[j+1]){
[arr[j], arr[j+1]] = [arr[j+1], arr[j]]
}
}
}
return arr
}
const res = bubbleSort(arr) // [1, 2, 3, 4, 5,6, 7, 8, 9]
模拟图:
2.快速排序:
// 1. 选择基准值,一般选择数组中间的值并且向下取整
// 2. 定义左右两个数组,比基准值小的放在左边,比基准值大的放在右边
// 3. 递归左右两个数组
// 4. 终止条件是左右两个数组都只有一个元素
const arr = [49, 38, 65, 97, 76, 13, 27, 49]
function quickSort(arr){
// 终止条件是左右两个数组都只有一个元素
if(arr.length<2){
return arr
}
// 定义左右两个数组
const leftArr = [],
rightArr = []
// 获取基准值
const index = Math.floor(arr.length/2)
const baseValue = arr.splice(index,1)
// 比基准值小的放在左边,比基准值大的放在右边
for(let i of arr){
if(i < baseValue){
leftArr.push(i)
}else{
rightArr.push(i)
}
}
// 递归左右两个数组
return [...quickSort(leftArr), ...baseValue, ...quickSort(rightArr)]
}
const res = quickSort(arr)
console.log(res); // [13, 27, 38, 49,49, 65, 76, 97]
3.选择排序:找到数据结构中的最小值并 将其放置在第一位,接着找到第二小的值并将其放在第二位,以此类推。
// 选择排序:每次找到最小值放在最前面
const arr = [49, 38, 65, 97, 76, 13, 27, 49]
function choseSort(arr){
for(let i=0; i<arr.length; i++){
// 假设最小值元素对应的下标为 i
let minIndex = i
// 寻找最小值
for(let j=i+1; j<arr.length; j++){
if(arr[minIndex] > arr[j]){
minIndex = j
}
}
// 交换数据,第一轮交换第一个数和最小数的位置,以此类推
[arr[i],arr[minIndex]] = [arr[minIndex],arr[i]]
}
return arr
}
const res = choseSort(arr)
console.log(res); // [13, 27, 38, 49,49, 65, 76, 97]
4.插入排序:对循环次数的真正优化,将一组无序数列的左侧始终看成是有序的。
// 1. 第一次是首位,因为只有一个元素
// 2. 第二次取出数组中第二个元素,从后向前遍历左侧的有序数列,找到第一个比这个数大的数,将取出来的数插到这个数的前面
// 3. 如果没有比取出来的数大的,则将这个数插在左侧有序数列的最后面
// 4. 重复步骤2,3,每次向后取一个元素
const arr = [49, 38, 65, 97, 76, 13, 27, 49]
function insertSort(arr){
for(let i=1; i<arr.length; i++){
// 取出来的目标数
let targetNum = arr[i],j = i-1
// 从后向前遍历
while(arr[j] > targetNum){
// 将目标数插入到比它大的数的前面
arr[j+1] = arr[j];
j--
}
// 没有比目标数大的数,则目标数就在原位,不需要改动
arr[j+1] = targetNum
}
return arr
}
const res = insertSort(arr)
console.log(res); // [13, 27, 38, 49,49, 65, 76, 97]
5.归并排序:归并排序是一种分治算法。其思想是将原始数组切分成较小的数组,直到每个小数组只有一 个位置,接着将小数组归并成较大的数组,直到最后只有一个排序完毕的大数组。
// 合并两个有序数组
// 将待排序序列不断地二分,直到只有一个元素。
// 递归地将左右两个子序列进行归并排序。
// 合并两个有序子序列,生成一个新的有序序列。
// 合并地具体操作如下:
// 创建一个临时数组,用于存储合并结果。
// 比较左右两个子序列的第一个元素,将较小的元素放入临时数组,并将对应子序列的指针向后移动一位。
// 重复上述比较和放入操作,直到其中一个子序列为空。
// 将另一个非空子序列的剩余元素依次放入临时数组。
// 将临时数组的元素复制回原始数组相应位置。
function mergeSort(arr) {
if (arr.length <= 1) {
return arr;
}
const mid = Math.floor(arr.length / 2);
const left = arr.slice(0, mid);
const right = arr.slice(mid);
return merge(mergeSort(left), mergeSort(right));
}
function merge(left, right) {
let result = [];
let i = 0;
let j = 0;
while (i < left.length && j < right.length) {
if (left[i] < right[j]) {
result.push(left[i]);
i++;
} else {
result.push(right[j]);
j++;
}
}
return result.concat(left.slice(i)).concat(right.slice(j));
}
// 示例用法
const arr = [5, 3, 8, 4, 2, 9, 1, 7, 6];
const sortedArr = mergeSort(arr);
console.log(sortedArr); // [1, 2, 3, 4, 5, 6, 7, 8, 9]
搜索算法:顺序搜索:最基本的一种搜索算法,就是将数据结构中的每一个元素,和我们要找的元素作比较,这种搜索算法非常的低效率。
const arr = [5,4,3,2,1]
const arr = [5,4,3,2,1]
function sequentialSearch(arr, value){
for(let i of arr){
if(i == value)return '搜索到了'
}
return '没有搜索到'
}
const res = sequentialSearch(arr, 3)
console.log(res,'res=='); // 搜索到了

二分搜索:
// 二分搜索
// 1. 要求被搜索的数据结构已经排序,选择中间值
// 2. 如果中间值等于目标值,则找到,算法执行完毕
// 3. 如果中间值大于目标值,则说明目标值在中间值的左侧,此时在左侧在找到中间值,在比较,以此类推
// 4. 如果中间值小于目标值,则说明目标值在中间值的右侧,此时在右侧在找到中间值,在比较,以此类推
const arr = [1,2,3,4,5,6,7,8]
function BinarySearchTree(arr, value){
// arr是一个已经排序好的数组,如果是无序的先进行排序
let left = 0
let right = arr.length - 1
while(left <= right){
// 中间值的下标
let mid = Math.floor((left + right) / 2)
if(arr[mid] == value){
return `找到了下标为:${mid}`
}else if(arr[i] > value){
right = mid -1
}else{
left = mid +1
}
}
return '找不到目标值'
}
const res = BinarySearchTree(arr,5) // '找到了下标为:4'
const res = BinarySearchTree(arr,9) // '找不到目标值'
斐波那锲数列:前两个数都为1,从第三个数字开始是前两个数字之和。
function fibonacci(n){
// 要求n是大于0的整数
if(n < 3){
return 1
}else{
return fibonacci(n-1) + fibonacci(n-2)
}
}
fibonacci(1) // 1
fibonacci(2) // 1
fibonacci(3) // 2
fibonacci(6) // 8

阶乘数列:当前数等于从1开始乘,一直乘到当前数字。例如:f(3)=123
function factorial(n){
// 要求n是大于0的整数
if(n == 1){
return 1
}else{
return factorial(n-1) * n
}
}
factorial(1) // 1
factorial(2) // 2
factorial(3) // 6
factorial(4) // 24
factorial(5) // 120
分治法:它将一个复杂的问题分解成多个相对简单且独立的子问题,然后递归地解决这些子问题,最后将其合并得到原问题的解,具体步骤为:分解(Divide):将原问题划分成多个相同或相似的子问题。这一步骤通常利用递归实现。解决(Conquer):递归地解决子问题。如果子问题足够小,可以直接求解。合并(Combine):将子问题的解合并成原问题的解。
例如:归并排序、快速排序
动态规划:它将一个复杂的问题分解成多个相互关联的子问题,通过反复求解子问题,来解决原来的问题。
常见动态规划问题有:斐波那锲数列,爬楼梯,打家劫舍,背包问题,最长公共子序列问题,硬币找零,图的全源最短路径。
爬楼梯问题:假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
// 动态规划,爬楼梯
// 示例 1:
// 输入:n=2
// 输出:2
// 解释:有两种爬楼梯的方法:
// 1. 1 阶 + 1 阶
// 2. 2 阶
// 示例 2:
// 输入:n = 3
// 输出:3
// 解释:有三种方法可以爬到楼顶。
// 1. 1 阶 + 1 阶 + 1 阶
// 2. 1 阶 + 2 阶
// 3. 2 阶 + 1 阶
// 解题思路:可以假设在第n-1个台阶爬一个台阶,或者在第n-2个台阶爬两个台阶。则问题就变为了:f(n)=f(n-1) + f(n-2)
// f(n-1) 为爬到第n-1个台阶的办法,f(n-2)为爬到第n-2个台阶的办法
// 时间复杂度O(n)
// 空间复杂度O(n)
function climbStairs(n){
// 规定n是大于等于1的正整数
if(n==1){
return 1
}else{
// 存放f(n)的数组
let dp = [1,1]
for(let i=2;i<=n;i++){
dp[i] = dp[i-1] + dp[i-2]
}
return dp[n]
}
}
// 优化算法:变量替换数组
// 时间复杂度O(n)
// 空间复杂度O(1)
function climbStairs(n){
if(n==1) return 1
let dp0 = 1,dp1 = 1
for(let i=2;i<=n;i++){
[dp0, dp1] = [dp1, dp0 + dp1]
}
return dp1
}
climbStairs(5) // 8
climbStairs(8) // 34
取值问题:在不同时经过两个相邻房间的情况下,能够获取到的最多钱财
// 示例 1:
// 输入:[1,2,3,1]
// 输出:4
// 解释:1 号房屋 (金额 = 1) ,然后 3 号房屋 (金额 = 3)。
// 获取到的最高金额 = 1 + 3 = 4 。
// 示例 2:
// 输入:[2,7,9,3,1]
// 输出:12
// 解释:1 号房屋 (金额 = 2), 3 号房屋 (金额 = 9),接着5 号房屋 (金额 = 1)。
// 获取到的最高金额 = 2 + 9 + 1 = 12 。
// 解题思路:到第 k 间房能获取到的最大金额,应该是前 k-2 间房获取到的最大金额加上第 k 间房的金额。
// 或者是 前 k-1 间房获取到的最大金额。
// 最终结果就是这两种情况下取最大值。
// f(k): 前 k 间房获取的最大值,a(k): 第 k 间房的金额。
// f(k) = Math.max(f(k-2) + a(k), f(k-1))
function getmoney(list){
if(list.length == 0)return 0
// 存放能获取到的最大金额的数组,i表示房间数
let dp = [0, list[0]]
for(let i=2;i<=list.length;i++){
dp[i] = Math.max(dp[i-2] + list[i-1], dp[i-1])
}
return dp[list.length]
}
getmoney([2,5,3,1,9,4,7,6]) // 21
getmoney([2,8,3,1,9,4,7,6]) // 24
贪心算法:期望通过每一个阶段的局部最优解,从而得到全局最优解(只是一种期望,实际上可能并不能得到全局最优解)。它不像动态规划那样计算更大的格局。
贪心算法和动态规划的异同:
相同点:
- 两者都有最优子结构,以及贪心选择策略(贪心)或重叠子问题(dp)。
- 可以理解贪心算法是特殊的动态规划算法。
不同点:文章来源:https://www.toymoban.com/news/detail-525328.html
- 贪心算法应用的范围较少,求解的是局部最优解。每一个阶段的最优解依赖于上一个阶段。最后得到的解是所有局部最优解的推断,并不一定是全局最优解,求解过程较快,是一种自上而下的求解过程。
- 动态规划:类似于穷举法,求解所有可行解,最后通过回溯法获取全局最优解
- 贪心算法求解过程:
将所有候选解按一定规则排序;
根据贪心选择策略(某个循环实现)判断个是否选择到最优解中。 - 动态规划求解过程:
①将所有于问题的可行解存储在一个列表中;
②循环写递推式(可用递归写的部分)
③使用回溯法推出最优解。
const coinArr = [1,0.5,5,2,10,50,20,100]
const amount = 43
function changeAmount(coins, amount){
// 把钱币面额数组从大到小排序
coins.sort((a,b)=>b-a)
// 存储找零结果
let result = []
for (let i = 0;i<coinArr.length;i++){
while(amount>=coins[i]){
// 将最大面值放进数组
result.push(coinArr[i])
// 减去已经找零的金额
amount -= coinArr[i]
}
}
// 能找开的时候amount一定是等于零的
if(amount>0){
return '找不开零钱'
}
return result
}
console.log(changeAmount(coinArr,amount));
 文章来源地址https://www.toymoban.com/news/detail-525328.html
文章来源地址https://www.toymoban.com/news/detail-525328.html
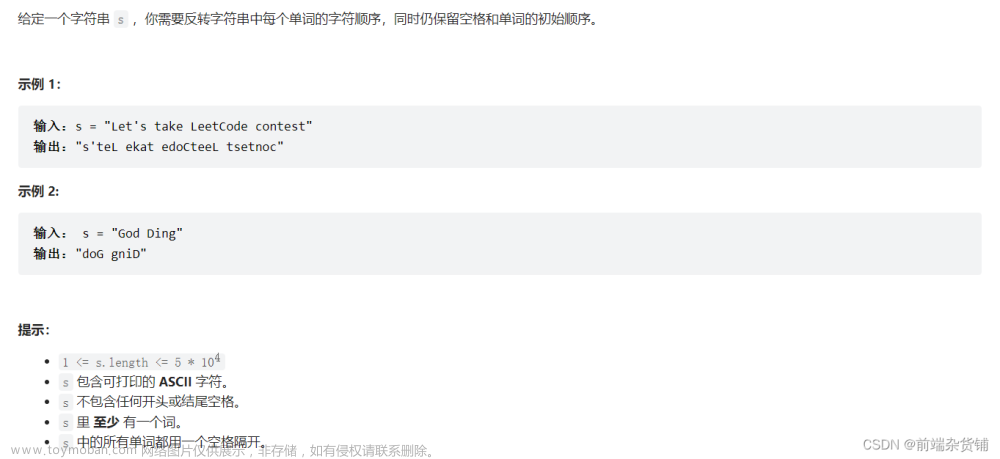
到了这里,关于数据结构与算法(持续更新中..)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![Javascript 数据结构[入门]](https://imgs.yssmx.com/Uploads/2024/02/636445-1.png)



