♥️作者:白日参商
🤵♂️个人主页:白日参商主页
♥️坚持分析平时学习到的项目以及学习到的软件开发知识,和大家一起努力呀!!!
🎈🎈加油! 加油! 加油! 加油
🎈欢迎评论 💬点赞👍🏻 收藏 📂加关注+!
学习目标:能够利用python对一些科研中需要用到的数据进行爬取
一、步骤总览
1、导入python库
2、获取豆瓣电影的第一页的数据 并保存起来
3、请求对象的定制
4、模拟浏览器向服务器发送请求
5、获取响应的数据
6、把数据下载到本地
二、代码示例
import urllib.request
# get请求
# 1、获取豆瓣电影的第一页的数据 并保存起来
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# 2、请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 3、模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 4、获取响应的数据
content = response.read().decode('utf-8')
# 5、把数据下载到本地
# open方法默认使用的是gbk的编码,如果我们想保存汉字,那么需要在open方法中指定编码格式为utf-8,下面有两种方法可以自己选择
# 方法一
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content)
# 方法二
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
三、通俗代码解读:
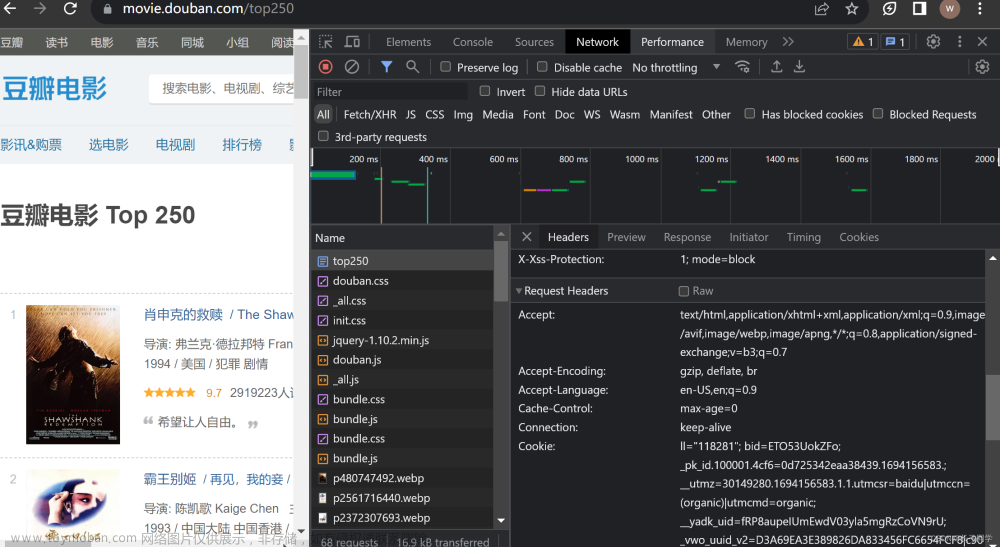
当拿到整个代码的时候,首先是导入请求包import urllib.request,紧接着是url,URL就是我们要读取的数据的地址接口,下面以chrome为例:
接下来就是User-Agent的获取,直接在上面那演示的位置就可以找到:
拿到自己的上面两步以后,就是对请求对象的定制了:文章来源:https://www.toymoban.com/news/detail-525565.html
# 2、请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 3、模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 4、获取响应的数据
content = response.read().decode('utf-8')
因为爬取的数据是json格式的,我们需要创建一个json文件并保存我们爬取的内容:文章来源地址https://www.toymoban.com/news/detail-525565.html
# 5、把数据下载到本地
# open方法默认使用的是gbk的编码,如果我们想保存汉字,那么需要在open方法中指定编码格式为utf-8,下面有两种方法可以自己选择
# 方法一
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content)
# 方法二
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
-
CSDN 技术博客 1 篇
♥️作者:白日参商
🤵♂️个人主页:白日参商主页
♥️坚持分析平时学习到的项目以及学习到的软件开发知识,和大家一起努力呀!!!
🎈🎈加油! 加油! 加油! 加油
🎈欢迎评论 💬点赞👍🏻 收藏 📂加关注+!
到了这里,关于【爬虫学习】1、利用get方法对豆瓣电影数据进行爬取的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2024/01/415693-1.png)



