【Kafka】Kafka基础概念笔记
1. 两种模式
Kafka作为消息队列,有两种模式:
- 点对点模式
- 发布/订阅模式
1.1 点对点模式
特点:
- 消费者主动拉取数据,消息收到后清除消息

1.2 发布/订阅模式
- 可以有多个topic主题(浏览、点赞、收藏、评论等)
- 消费者消费数据之后,不删除数据
- 每个消费者相互独立,都可以消费到数据

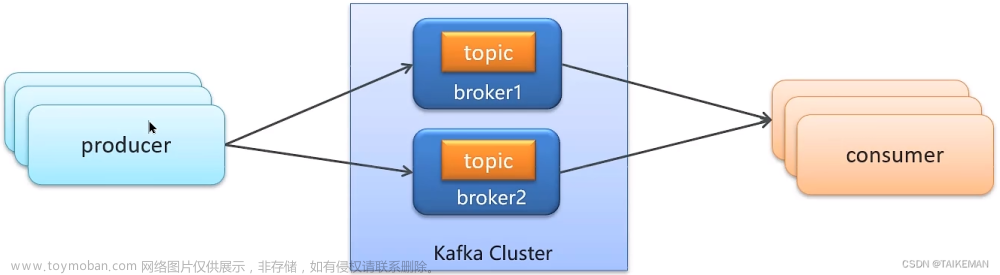
2. 基础架构
Kafka的基础架构:
- 为方便扩展,并提高吞吐量,一个topic分为多个partition(分区)
- 配合分区的设计,提出消费者组的概念,组内每个消费者并行消费,一个分区只能由一个组内消费者消费,避免重复消费
- 为提高可用性,为每个partition增加若干副本
- Zookeeper中记录谁是leader,Kafka2.8.0以后也可以配置不采用ZK

- Consumer Group(CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,为避免详消息的重复消费,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台Kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
- Topic:可以理解为一个队列,生产者和消费者面向的都是一个topic。
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker (即服务器上),一个topic可以分为多个 partition,每个 partition 是一个有序的队列。
- Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower。
- Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
- Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
3. Topic命令行操作
3.1 查看 Topic 操作
①查看操作Topic命令参数
#在kafka的目录下
bin/kafka-topics.sh
输入该命令行后,控制台列出所有的参数及含义:

总结如下:

3.2 创建 Topic
②创建一个名为first的topic,要求分区数为1,集群有3个节点,所以分区副本设置为3
bin/kafka-topics.sh --bootstrap-server node1:9092 --create --partitions 1 --replication-factor 3 --topic first
3.3 查看所有 Topic
③查看当前服务器中所有的topic
bin/kafka-topics.sh --bootstrap-server node1:9092 --list
3.4 查看 Topic 的详情
④查看 first 主题的详情
bin/kafka-topics.sh --bootstrap-server node1:9092 --describe --topic first

-
Replicas:1,2,0表示副本分别存在三个节点中 -
Leader:1表示Leader副本存储在代号为1的节点中,其余两个存的是Follower副本 -
Isr:1,2,0表示同步副本,follower副本同步leader副本的数据,ISR是Kafka中用于保证数据一致性和可靠性的副本集合
3.5 修改分区数
⑤注意:分区数只能增加不能减少
bin/kafka-topics.sh --bootstrap-server node1:9092 --alter --partitions 3 --topic first
修改之后再次查看 first 主题的详情:

3.6 删除 Topic
⑥删除 first 主题
bin/kafka-topics.sh --bootstrap-server node1:9092 --delete --topic first
4. 生产者命令行操作
4.1 生产者命令行操作
查看操作生产者命令参数
bin/kafka-console-producer.sh


4.2 给 topic 发送消息
bin/kafka-console-producer.sh --bootstrap-server node1:9092 --topic first

向 first 主题发送了一条 hello world 消息。
5. 消费者命令行操作
5.1 查看操作消费者命令参数
bin/kafka-console-consumer.sh



5.2 消费 topic 中的消息
消费 first 主题中的消息
bin/kafka-console.consumer.sh --bootstrap-server node1:9092 --topic first

我们发现光标一直在闪,却没有收到任何消息,那是因为kafka默认读取consumer脚本起来之后的消息,想要读取所有数据(包含历史数据)就要加上 --from-beginning 参数
bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --from-beginning --topic first
 文章来源:https://www.toymoban.com/news/detail-525604.html
文章来源:https://www.toymoban.com/news/detail-525604.html
这样就把历史数据也给读出来了。文章来源地址https://www.toymoban.com/news/detail-525604.html
到了这里,关于【Kafka】Kafka基础操作笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!