LangChain 是一个强大的框架,可以简化构建高级语言模型应用程序的过程。
LangChain简介
LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
LangChain的主要功能有:调用语言模型,将不同数据源接入到语言模型的交互中,允许语言模型与运行环境交互。
LangChain中的核心概念
1. Components and Chains
**Component 是模块化的构建块,可以组合起来创建强大的应用程序。Chain 是组合在一起以完成特定任务的一系列 Components(或其他 Chain)。**例如,一个 Chain 可能包括一个 Prompt 模板、一个语言模型和一个输出解析器,它们一起工作以处理用户输入、生成响应并处理输出。
2. Prompt Templates and Values
Prompt Template 负责创建 PromptValue,这是最终传递给语言模型的内容。Prompt Template 有助于将用户输入和其他动态信息转换为适合语言模型的格式。PromptValues 是具有方法的类,这些方法可以转换为每个模型类型期望的确切输入类型(如文本或聊天消息)。
3. Example Selectors
当想要在 Prompts 中动态包含示例时,Example Selectors 很有用。它们接受用户输入并返回一个示例列表以在提示中使用,使其更强大和特定于上下文。
4. Output Parsers
Output Parsers 负责将语言模型响应构建为更有用的格式。它们实现了两种主要方法:一种用于提供格式化指令,另一种用于将语言模型的响应解析为结构化格式。这使得在您的应用程序中处理输出数据变得更加容易。
5. Indexes and Retrievers
Index 是一种组织文档的方式,使语言模型更容易与它们交互。检索器是用于获取相关文档并将它们与语言模型组合的接口。LangChain 提供了用于处理不同类型的索引和检索器的工具和功能,例如矢量数据库和文本拆分器。
6. Chat Message History
LangChain 主要通过聊天界面与语言模型进行交互。ChatMessageHistory 类负责记住所有以前的聊天交互数据,然后可以将这些交互数据传递回模型、汇总或以其他方式组合。这有助于维护上下文并提高模型对对话的理解。
7. Agents and Tookits
Agent 是在 LangChain 中推动决策制定的实体。它们可以访问一套工具,并可以根据用户输入决定调用哪个工具。Tookits 是一组工具,当它们一起使用时,可以完成特定的任务。代理执行器负责使用适当的工具运行代理。
什么是LangChain Agent?
LangChain Agent 是框架中驱动决策制定的实体。它可以访问一组工具,并可以根据用户的输入决定调用哪个工具。代理帮助构建复杂的应用程序,这些应用程序需要自适应和特定于上下文的响应。当存在取决于用户输入和其他因素的未知交互链时,它们特别有用。
什么是LangChain model?
LangChain model 是一种抽象,表示框架中使用的不同类型的模型。LangChain 中的模型主要分为三类:
- LLM(大型语言模型):这些模型将文本字符串作为输入并返回文本字符串作为输出。它们是许多语言模型应用程序的支柱。
- 聊天模型( Chat Model):聊天模型由语言模型支持,但具有更结构化的 API。他们将聊天消息列表作为输入并返回聊天消息。这使得管理对话历史记录和维护上下文变得容易。
- 文本嵌入模型(Text Embedding Models):这些模型将文本作为输入并返回表示文本嵌入的浮点列表。这些嵌入可用于文档检索、聚类和相似性比较等任务。
LangChain的代码结构
langchain的repo:https://github.com/hwchase17/langchain
可以看到LangChain可以对接的LLM不止一个,agents和tools同样有很多个:


1. LangChain中提供的模块
- Modules:支持的模块类型和集成
- Prompt:提示词管理、优化和序列化
- Memory:内存是指在链/代理调用之间持续存在的状态。
- Indexes:当语言模型与特定于应用程序的数据相结合时,会变得更加强大——此模块包含用于加载、查询和更新外部数据的接口和集成。
- Chain:链是结构化的调用序列(对LLM或其他实用程序)。
- Agents:代理是一个链,其中LLM在给定高级指令和一组工具的情况下,反复决定操作,执行操作并观察结果,直到高级指令完成。
- Callbacks:回调允许记录和流式传输任何链的中间步骤,从而轻松观察、调试和评估应用程序的内部。
2. LangChain的应用场景
- 文档问答:一个常见的LangChain用例。在特定文档上回答问题,仅利用这些文档中的信息来构建答案。
- 个人助理:LangChain的主要用例之一。个人助理需要采取行动,记住互动,并了解您的数据
- 查询表格数据:使用语言模型查询库表类型结构化数据(CSV、SQL、DataFrame等)
- 与API交互:使语言模型与API交互非常强大,它允许他们访问最新信息,并允许他们采取行动。
- 信息抽取:从文本中提取结构化的信息。
- 文档总结:压缩较长文档,一种数据增强生成。
3. LangChain 的主要特点
LangChain 旨在为六个主要领域的开发人员提供支持:
- LLM 和提示:LangChain 使管理提示、优化它们以及为所有 LLM 创建通用界面变得容易。此外,它还包括一些用于处理 LLM 的便捷实用程序。
- 链(Chain):这些是对 LLM 或其他实用程序的调用序列。LangChain 为链提供标准接口,与各种工具集成,为流行应用提供端到端的链。
- 数据增强生成:LangChain 使链能够与外部数据源交互以收集生成步骤的数据。例如,它可以帮助总结长文本或使用特定数据源回答问题。
- Agents:Agents 让 LLM 做出有关行动的决定,采取这些行动,检查结果,并继续前进直到工作完成。LangChain 提供了代理的标准接口,多种代理可供选择,以及端到端的代理示例。
- 内存:LangChain 有一个标准的内存接口,有助于维护链或代理调用之间的状态。它还提供了一系列内存实现和使用内存的链或代理的示例。
- 评估:很难用传统指标评估生成模型。这就是为什么 LangChain 提供提示和链来帮助开发者自己使用 LLM 评估他们的模型。
LangChain使用示例
LangChain 支持大量用例,例如:
- 针对特定文档的问答:根据给定的文档回答问题,使用这些文档中的信息来创建答案。
- 聊天机器人:构建可以利用 LLM 的功能生成文本的聊天机器人。
- Agents:开发可以决定行动、采取这些行动、观察结果并继续执行直到完成的代理。
使用 LangChain 构建端到端语言模型应用程序
LangChain中有两个核心概念:agent和tool
安装LangChain:
pip install openai
环境设置
现在由于 LangChain 经常需要与模型提供者、数据存储、API 等集成,我们将设置我们的环境。在这个例子中,将使用 OpenAI 的 API,因此需要安装他们的 SDK:
pip install openai
设置环境变量:
import os
import openai
import warnings
warnings.filterwarnings('ignore')
# Set the OpenAI API key
os.environ['OPENAI_API_KEY'] = "sk-xxxxxxxxxxxxxxx" # get api_key from openai official website
openai.api_key = os.getenv("OPENAI_API_KEY")
构建语言模型应用程序:LLM
安装好LangChain并设置好环境后,就可以开始构建语言模型应用程序了。LangChain 提供了一堆模块,可以使用它们来创建语言模型应用程序。可以将这些模块组合起来用于更复杂的应用程序,或者将它们单独用于更简单的应用程序。
构建语言模型应用程序:Chat Model
除了 LLM,还可以使用聊天模型。这些是语言模型的变体,它们在底层使用语言模型但具有不同的界面。聊天模型使用聊天消息作为输入和输出,而不是“文本输入、文本输出”API。聊天模型API的使用还比较新,所以大家都还在寻找最佳抽象使用方式。
要完成聊天,需要将一条或多条消息传递给聊天模型。LangChain 目前支持 AIMessage、HumanMessage、SystemMessage 和 ChatMessage 类型。主要使用 HumanMessage、AIMessage 和 SystemMessage。例如:
from langchain.chat_models import ChatOpenAI
from langchain.schema import (AIMessage, HumanMessage, SystemMessage)

上图示例中表示向OpenAI传递一条消息。当然,也可以传递多条消息:
还可以使用generate为多组消息生成完成。这将返回一个带有附加消息参数的 LLMResult:
还可以从 LLMResult 中提取 tokens 使用等信息:
result.llm_output['token_usage']
# -> {'prompt_tokens': 69, 'completion_tokens': 19, 'total_tokens': 88}
对于聊天模型,还可以通过使用 MessagePromptTemplate 来使用模板。可以从一个或多个 MessagePromptTemplates 创建 ChatPromptTemplate。ChatPromptTemplate 的方法format_prompt返回一个 PromptValue,可以将其转换为字符串或 Message 对象,具体取决于是否要使用格式化值作为 LLM 或聊天模型的输入。例如:
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate)

还可以将代理与聊天模型一起使用。使用 AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION 作为代理类型初始化 Agent:
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI
安装serpapi package和设置SERPAPI_API_KEY环境变量:
!pip install google-search-results
# Set the Search API key
os.environ['SERPAPI_API_KEY'] = "xxxxxxxxxxxxxxxxx"

在此示例中,代理将以交互的方式执行搜索和计算以提供最终答案。
最后,探索将内存与使用聊天模型初始化的链和代理一起使用。这与 Memory for LLMs 的主要区别在于可以将以前的消息保留为它们自己唯一的内存对象,而不是将它们压缩成一个字符串。
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate
)
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template("The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know."),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
])
llm = ChatOpenAI(temperature=0)
memory = ConversationBufferMemory(return_messages=True)
conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm)

在此示例中使用ConversationChain来维护跨与 AI 的多次交互的对话上下文。
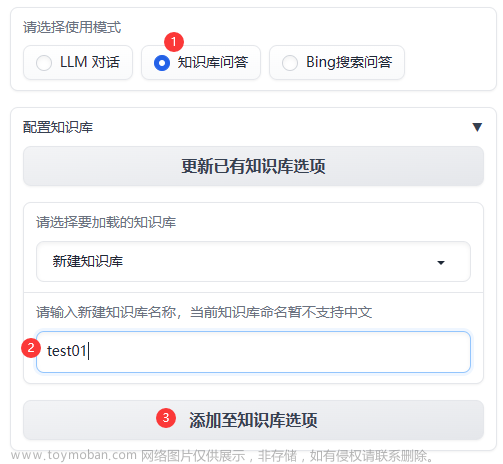
如何实现基于本地知识的问答?

基于单一文档问答的实现原理
- 加载本地文档
- 文档拆分
- 根据提问匹配文本
- 构建prompt
- LLM生成回答

基于本地知识库问答的实现原理

从文档处理角度来看,实现流程如下:
代码实现:
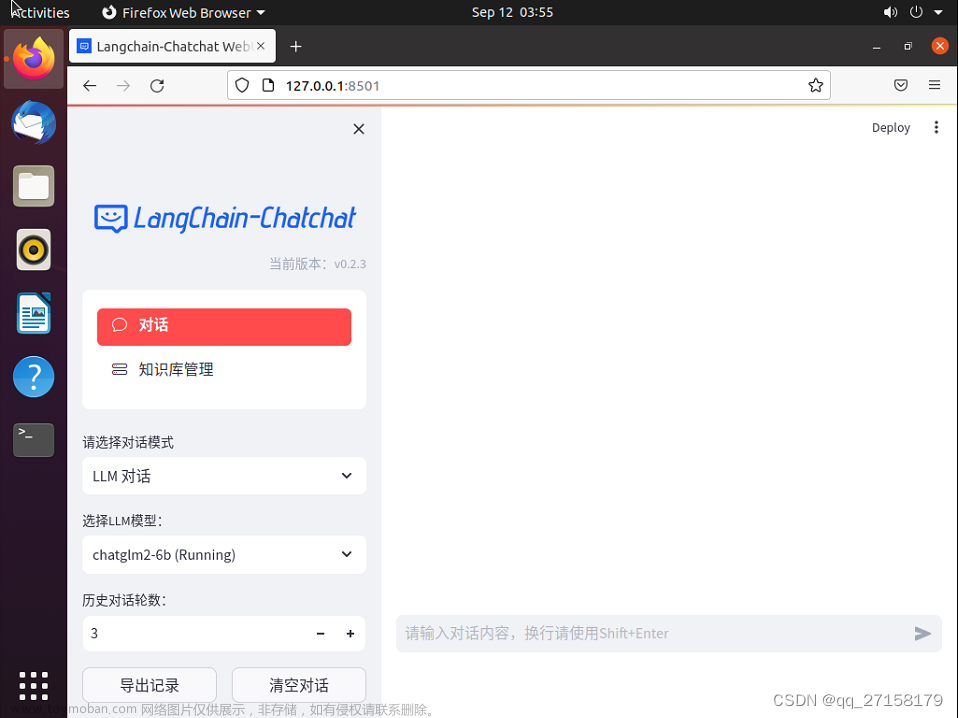
LangChain-ChatGLM简介
LangChain-ChatGLM是一个基于ChatGLM等大预言模型的本地知识库问答实现,也就是一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
项目地址:基于本地知识库的 ChatGLM 等大语言模型应用实现
项目特点:
- 依托ChatGLM等开源模型实现,可离线部署
- 基于langchain实现,可快速实现接入多种数据源
- 在分句、文档读取等方面,针对中文使用场景优化
- 支持PDF、txt、md、docx等文件类型接入,具备命令行demo、webui和vue前端。
项目结构:文章来源:https://www.toymoban.com/news/detail-525950.html
- models:LLM的接口类和实现类,针对开源模型提供流式输出支持。
- loader:文档加载器的实现类
- textsplitter:文本切分的实现类
- chains:工作链路实现,如chains/local_doc_qa实现了基于本地文档的问答实现
- content:用于存储上传的原始文件
- vector_store:用于存储向量库文件、即本地知识库本体
- configs:配置文件存储
项目优化的方向:文章来源地址https://www.toymoban.com/news/detail-525950.html
- 模型微调:对LLM和embedding基于专业领域数据进行微调
- 文档加工:在文本分段后,对每段分别进行总结,基于总结内容语义进行匹配
- 借助不同模型能力:在text2sql、text2cpyher场景下需要产生代码时,可借助不同模型能力
相关资料
- LangChain 完整指南:使用大语言模型构建强大的应用程序
- 注册 Serpapi
到了这里,关于【大语言模型】15分钟快速掌握LangChain以及ChatGLM的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!