目标
介绍OpenCV内部通用的特征来向量化C++代码以此获取更快的运行时间。我们将简要介绍SIMD内部函数和如何使用宽寄存器。
理论
在这一节,我们简要的介绍一些概念来更好理解功能。
1. 内建函数(Intrinsics)
内建函数(Intrinsics) 是编译器单独处理函数。这些函数通常使用更高效的方式来优化运行效率。 但是,因为这些函数独立于编译器,这一为编写可移植的程序带来困难。
2. SIMD
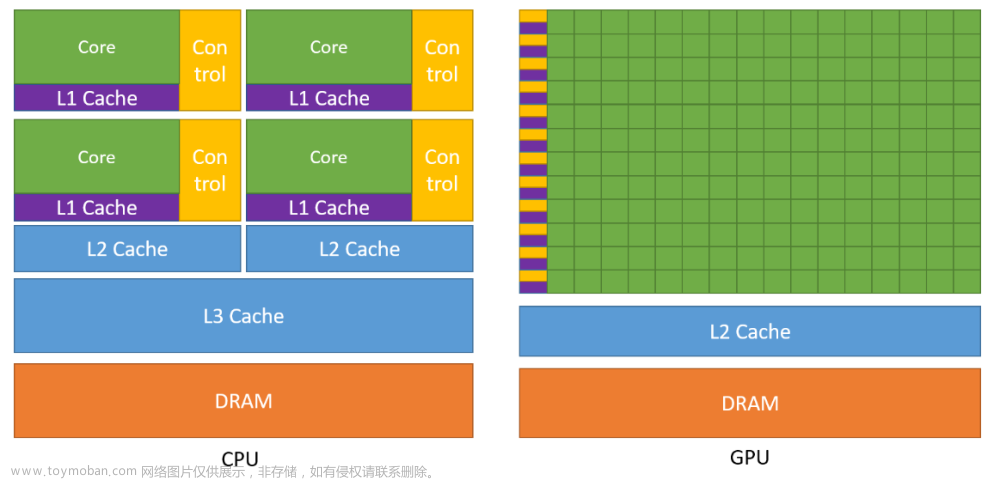
SIMD 是 Single Instruction, Multiple Data 的缩写。 SIMD内建函数允许处理器矢量化计算。数据将被存储在一个特殊的寄存器中。这个寄存器可能是128-bit, 258-bit 或者512-bit宽的。每个寄存器保存多个相同类型的值。寄存器的尺寸以及每个值的尺寸决定了寄存器中数据的个数。
取决于CPU的架构,不同的CPU可能又不同的寄存器位宽。
通用内建函数
OpenCV的通用内建函数提供了一个SIMD向量化方法的抽象, 并且使用者不需要编写单独的代码来适配自己的系统就可以使用这些内建方法。
OpenCV 通用内建方法支持如下的指令集:
- 128 bit 寄存器
-
- x86(SSE/SSE2/SSE4.2)
-
- ARM(NEON)
-
- PowerPC(VSX)
-
- MIPS(MSA)
- 256 bit 寄存器 支持 x86(AVX2)
- 512 bit 寄存器 支持 x86(AVX512)
我们将介绍相关的结构体和函数:
- Register structures
- Load and store
- Mathematical Operations
- Reduce and Mask
1. Register Structures
通用内建函数将每个寄存器都实现为一个结构体,这个结构体基于特定的SIMD寄存器。所有的类型都包含 nlanes 枚举。这个枚举给出了该类型可以容纳的精确数值。者可以消除实现过程中硬编码的需要。
Note
每个寄存器结构体都在 cv的命名空间之下
有两类寄存器:尺寸可变寄存器(variable sized registers), 固定尺寸寄存器(Constant sized registers)
1.1 可变尺寸寄存器
可变尺寸寄存器: 这类结构没有固定的尺寸,具体的长度由编译时推断出来。基于可变的SIMD容量, 因此,nlanes的类型是在编译是得到的。
每个结构体的形式如下:
v_[type of value][size of each value in bits]
例如,v_unint8 处理 8-bit 无符号整型, v_float32 处理32-bit 浮点型。 我们申明寄存器就像我们在C++中声明任意对象一样。
基于可获取的SIMD指令集,不同的寄存器可以容纳不同数量的值,比如:如果你的电脑支持最大256bit的寄存器,那么:
- v_uint8 可以容纳 32个 (8-bit 无符号整型)
- v_float64,可以容纳 4 个(double)
1.2 固定尺寸寄存器
固定尺寸寄存器: 具有固定 比特尺寸的结构并且只能处理固定数量的值。我们需要知道系统支持什么样的SIMD指令集,并选择兼容的寄存器。只有在需要知道精确的位长时才使用这些。
每个结构需要遵循如下惯例:
v_[type of value][size of each value in bits]x[number of values]
假设我们要存储:
- 32-bit 有符号整型 在 128-bit 的寄存器中。 由于寄存器大小是已知的,我们可以找出寄存器中数据点的数量(128/32=4):
v_int32x8 reg1 // holds 8 32-bit signed integers.
- 64-bit floats 在512位寄存器中:
v_float64x8 reg2 // reg2.nlanes = 8
2. 加载和保存操作
现在我们知道寄存器如何工作,让我们来看这些来看这些用于填充寄存器值的函数
2.1 Load
Load: 加载函数,允许你将值加载到寄存器中
2.2 Constructors
当声明一个寄存器结构是,我们既可以提供一个内存地址,寄存器可以从一个连续的地址中获取值。也可以提供一个显示提供值作为多个参数(显示多个参数仅适合于常量尺寸寄存器)
float ptr[32] = {1, 2, 3....,32}; // ptr 是一个32位连续内存块的指针
// 可变尺寸寄存器
int x = v_float32().nlanes; // 设置 x 作为寄存器可以保存的数目
v_float32 reg1(ptr); // reg1 保存前x个值,通过可获取的最大寄存器数量
v_float32 reg2(ptr + x); // reg2 保存后面的 x 个值
// 常量尺寸寄存器
v_float32x4 reg1(ptr); // reg1 保存前4个 float {1, 2, 3, 4}
v_float32x4 reg2(ptr + 4); // reg2 保存跟后面4个float {5, 6, 7, 8}
// 我们可以显示的写下这些值
v_float32x4(1, 2, 3, 4);
2.3 Load Function
我们可以使用加载方法并且提供内存中数据的地址。
float ptr[32] = {1,2,3, ...., 32};
v_float32 reg_var;
reg_var = vx_load(ptr); // 从 ptr 的 0 - reg_var.nlanes - 1 中加载数据
v_float32x4 reg_128; // 从ptr 的 0 - 3 中加载数据
reg128 = v_load(ptr);
v_float32x8 reg_256;
reg_256 = v256_load(ptr); // loads values from ptr[0] upto ptr[7]
v_float32x16 reg_512;
reg_512 = v512_load(ptr); // loads values from ptr[0] upto ptr[15]
Note: 加载函数假定数据是没有对齐的。如果你的数据是对齐的,你可以使用 vx_load_aligned() 函数
2.4 store
保存函数允许你将寄存器中的值保存到一个特定的内存中
- 可以使用 **v_store()**函数将寄存器中的值保存到内存中
float ptr[4];
v_store(ptr, reg); // 保存寄存器中前128-bit( 4 x 32 floats)到 ptr中
Note 确认ptr和寄存器是相同的类型。你也可以将寄存器中的转换过后在带出来。简单地将指针类型转换为特定类型将导致对数据的错误解释。
3. 二进制和一元运算符
这些内建通用函数 提供了一些二进制和一元操作
3.1 算术操作
我们可以加、减、乘、除 两个寄存器。并且可以做对位计算(element-wise). 寄存器必须有相同的宽和相同的类型。例如:
v_float32 a, b; // {a1, ..., an}, {b1, ..., bn}
v_float32 c;
c = a + b; // {a1 + b1, ..., an + bn}
c = a * b; // {a1 * b1, ..., an * bn}
3.2 二进制逻辑和偏移
我们可以左移和右移寄存器中的每个值。我们同样可以使用 bitwise & | ^ ~ 对两个寄存器做element-wise 操作。
v_int32 as; // {a1, ..., an}
v_int32 al = as << 2; // {a1 << 2, ..., an << 2}
v_int32 bl = as >> 2;
v_int32 a, b;
v_int a_and_b = a & b;
3.3 比较操作
我们可以使用 > < >= <= == 和 != 操作。 由于每个寄存器包含不同的值。我们对于这些操作不能获取单独的bool值。 相反的,对于 true 值, 所有位都被转化为1 (oxff for 8bit, oxffff for 16 bit …). 同时 false 值被转化为0.
// let us consider the following code is run in a 128-bit register
v_uint8 a; // a = {0, 1, 2, ..., 15}
v_uint8 b; // b = {15, 14, 13, ..., 0}
v_uint8 c = a < b;
/*
let us look at the first 4 values in binary
a = |00000000|00000001|00000010|00000011|
b = |00001111|00001110|00001101|00001100|
c = |11111111|11111111|11111111|11111111|
If we store the values of c and print them as integers, we will get 255 for true values and 0 for false values.
*/
---
// In a computer supporting 256-bit registers
v_int32 a; // a = {1, 2, 3, 4, 5, 6, 7, 8}
v_int32 b; // b = {8, 7, 6, 5, 4, 3, 2, 1}
v_int32 c = (a < b); // c = {-1, -1, -1, -1, 0, 0, 0, 0}
/*
The true values are 0xffffffff, which in signed 32-bit integer representation is equal to -1.
*/
3.4 最大最小值操作
我们可以使用 v_min 和 v_max 函数来返回两个寄存器中相同位置的寄存器中 最小值和最大值。
v_int32 a; // {a1, ..., an}
v_int32 b; // {b1, ..., bn}
v_int32 mn = v_min(a, b); // {min(a1, b1), ..., min(an, bn)}
v_int32 mx = v_max(a, b); // {max(a1, b1), ..., max(an, bn)}
Note: 对比最大值和最小值不能用在64位整数中。 Bitwise shfit 和逻辑运算只能用在整数值中。 bitwise shift 只能用在16, 32, 和64位的寄存器中。
4. Reduce and Mask
4.1 Reduce 操作 (规约操作)
- v_reduce_min
- v_reduce_max
- v_reduce_sum
规约操作返回一个值最大值、最小值或者和。
v_int32 a; // a = {a1, ..., a4}
int mn = v_reduce_min(a); // mn = min(a1, ..., an)
int sum = v_reduce_sum(a); // sum = a1 + ... + an
4.2 Mask Operations
Mask 操作包括:
- v_check_all() : 返回一个bool, 当所有的值在寄存器中都小于0时,返回true
- v_check_any(): 返回一个bool, 当有一个值小于0时,返回true
- v_select(): 返回一个寄存器,该寄存器基于掩码混合两个寄存器。
v_uint8 a; // {a1, .., an}
v_uint8 b; // {b1, ..., bn}
v_int32x4 mask: // {0xff, 0, 0, 0xff, ..., 0xff, 0}
v_uint8 Res = v_select(mask, a, b) // {a1, b2, b3, a4, ..., an-1, bn}
/*
"Res" 中的值挑选规则如下:
- 如果mask的对应位置为1,选a 中对应的元素,否则选b中对应的元素
*/
Demo
在这个模块中,我们将对单通道的简单卷积函数进行矢量化,并将结果与标量实现进行比较。
Note: 并不是所有的算法都是通过手动矢量化来改进的。事实上,在某些情况下,编译器可能会自动向量化代码,从而为标量实现产生更快的结果。文章来源:https://www.toymoban.com/news/detail-525960.html
1. 向量化卷积
我们首先实现一个一维的卷积并且向量化它。 二维向量化卷积将在行之间执行一维卷积以产生正确的结果。文章来源地址https://www.toymoban.com/news/detail-525960.html
1.1 1-D 卷积
void conv1d(Mat src, Mat& dst, Mat kernel)
{
int len = src.cols;
dst = Mat(1, len, CV_8UC1);
int sz = kernel.cols / 2;
copyMakeBorder(src, src, 0, 0, sz, sz, BORDER_REPLICATE);
for(int i = 0; i < len; i++)
{
double value = 0;
for (int k = -sz; k <= sz; ++k) {
value +=
}
}
}
1.2 1-D向量化实现
void conv1dsimd(Mat src, Mat kernel, float* ans, int row = 0, int rowk = 0, int len = 1)
{
if (len == -1) {
len = src.cols;
}
Mat src_32, kernel_32;
const int alpha = 1;
src.convertTo(src_32, CV_32FC1, alpha);
int ksize = kernel.cols;
int sz = kernel.cols / 2;
int step = v_float32().nlanes; // The item numbers in v_float32
float* sptr = src_32.ptr<float>(row); // The input data
float* kptr = kernel.ptr<float>(rowk); // The weights of kernel
copyMakeBorder(src_32, src_32, 0, 0, sz, sz, BORDER_REPLICATE); // padding
/**
算法实例
Input
--------------------------------
kernel: {k0, k1, k2}
src: a0, a1, a2, a3, a4, a5
step: 16 向量寄存器最多存储数量
--------------------------------
Algorighm
--------------------------------
1. Padding
src: a0, a1, a2, a3, a4, a5
src_32: a0, a0, a1, a2, a3, a4, a5, a5
2.分别计算每个卷积核分量的结果
----------------------------------------------------------------------------------------
k = 0 kernel_wide = k0 step = 16
kernel_wide: k0 k0 ... k0 (nums = step)
windows: a0 a0 ... a_{n-step} (nums = step)
ans: 0 0 ... 0 (nums = step)
sum: k0*a0 k0*a1 ... k0*a_{n-step} (nums = step)
----------------------------------------------------------------------------------------
ans: k0*a0 k0*a1 ... k0*a_{n-step} (nums = step)
----------------------------------------------------------------------------------------
回写到 ans, 并进行下一个向量化操作 ...
----------------------------------------------------------------------------------------
k = 1 kernel_wide = k0 step = 16
kernel_wide: k1 k1 ... k1 (nums = step)
windows: a1 a1 ... a_{n-step+1} (nums = step)
ans: k0*a0 k0*a1 ... k0*a_{n-step} (nums = step)
sum: k1*a1 k1*a2 ... k0*a_{n-step+1} (nums = step)
----------------------------------------------------------------------------------------
ans: k0*a0 + k1*a1 k0*a1+k1*a1 ... k0*a_{n-step} + k1*a_{n-step+1}
----------------------------------------------------------------------------------------
回写到 ans, 并进行下一个向量化操作 ...
*/
for (int k = 0; k < ksize; k++)
{
v_float32 kernel_wide = vx_setall_f32(kptr[k]);
int i = 0;
for ( i= 0; i + step < len; i += step )
{
v_float32 windows = vx_load(sptr + i + k);
v_float32 sum = vx_load(ans + i) + kernel_wide * windows;
v_store(ans + i, sum);
}
for(; i< len; i++)
{
*(ans + i) += sptr[i + k] * kptr[k];
}
}
}
参考资料
- https://docs.opencv.org/4.x/d6/dd1/tutorial_univ_intrin.html
到了这里,关于【OpenCV】SIMD向量化加速教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!