数字图像处理的期末大作业
成绩出来了,感觉一般般,做个记录
代码图片文件:数学建模2013年国赛B题碎纸片复原(纵切和横纵切两问)-统计分析文档类资源-CSDN下载
目录
第一问 碎纸片拼接--纵切
以下为python代码:
结果
问题二: 碎纸片拼接--纵切+横切
python代码如下:
结果:
第一问 碎纸片拼接--纵切
- 设计思路
通过二值化,将图片灰度转变为0-1之间(以便提高运算速率)。在此问题中题目给出了纵状的切割图片,主要的解题思路是通过计算每张图片与左边界的距离得到第一列图片的序号,然后遍历第一列的图片,为其匹配该行的图片,最终得到纵向图片拼接的序号。
- 算法步骤
- 对图像进行二值化的预处理
- 首先,求出第一列的序号(通过比较每张图片与最左边的距离,求出第一列的序号,因为图片一般存在页边距,而第一列的图片与左边界的距离是相同的,都为页边距)
- 对于求出的第一列的图片序号,求与其边缘匹配指数最高的图片,即为下一图片序号,通过计算下一图片的与其边缘匹配指数最高的图片为其下一图片序号。依次遍历得到最终的图片拼接排序。其中,边缘匹配指数为左边图片的最右边一列像素和右边匹配图片的最左边一列像素相等的个数。
以下为python代码:
import cv2
import numpy as np
import matplotlib.pyplot as plt
import skimage.io as io
from collections import Counter
from PIL import Image
data_dir = './附件1'
path = data_dir +'/*.bmp'
coll = io.ImageCollection(path)#读入灰度图像
img_num = len(coll)
#*********转矩阵*******
img = np.asarray(coll)
for i in range(0,len(coll)):
img[i] = cv2.adaptiveThreshold(src=img[i], # 要进行处理的图片
maxValue=1, # 大于阈值后设定的值
adaptiveMethod=cv2.ADAPTIVE_THRESH_MEAN_C, # 自适应方法,ADAPTIVE_THRESH_MEAN_C:表区域内均值;ADAPTIVE_THRESH_GAUSSIAN_C:表区域内像素点加权求和
thresholdType=cv2.THRESH_BINARY, # 同全局阈值法中的参数一样
blockSize=11, # 方阵(区域)大小,
C=1) # 常数项,每个区域计算出的阈值的基础上在减去这个常数作为这个区域的最终阈值,可以为负数
coll[0].shape
#计算与左边距离 选出第一张图片
Max = -1
index = 0
for i in range(0,img.shape[0]):
#计算
count = 0
for y in range(0,img.shape[2]):#图片按列便利
panduan = 1
for x in range(0,img.shape[1]):
if(img[i][x][y]==0):
panduan = 0
break
if(panduan==1):
count = count+1
else:
break
if(count>Max):
Max = count
index = i
#计算每一张的右边边缘 检测最匹配的图片
ans_index = [] #用于记录最终的排序
ans_index.append(index) #插入第一张图片的索引
#计算每一张的边缘 左和右 相匹配的值
while(1):
Max = -1
index = 0
zj = ans_index[len(ans_index)-1]
print(ans_index)
for i in range(0,len(coll)):
if(ans_index.count(i)==1):
continue
count = 0
for x in range(0,img.shape[1]):#遍历行遍历 左右元素
if(img[i][x][0]==img[zj][x][img.shape[2]-1]):
count = count + 1
if(count>Max):
Max = count
index = i
ans_index.append(index)
print(ans_index)
if(len(ans_index)==len(coll)):
break
ans_img = coll[ans_index[0]]
for i in range(0,len(ans_index)):
if(i==0):
continue
ans_img = np.hstack((ans_img, coll[ans_index[i]])) # 水平合并
ans_img.shape
im = Image.fromarray(ans_img) # to Image
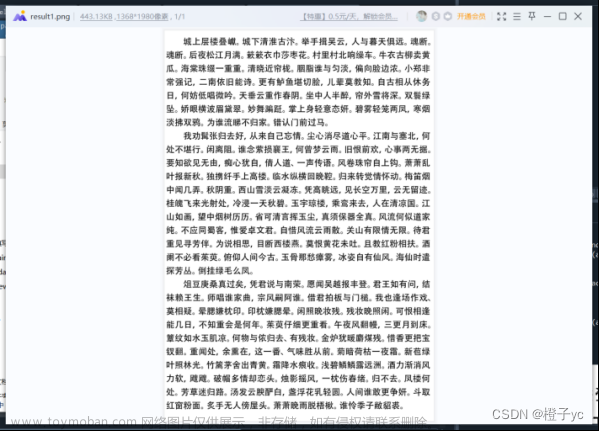
im.save('result1.png')
代码运行结果:
结果
通过上述算法计算得到附件1的图片拼接顺序如下:
[8, 14, 12, 15, 3, 10, 2, 16, 1, 4, 5, 9, 13, 18, 11, 7, 17, 0, 6]
最终拼接得到的图片如下所示(result1.png文件):
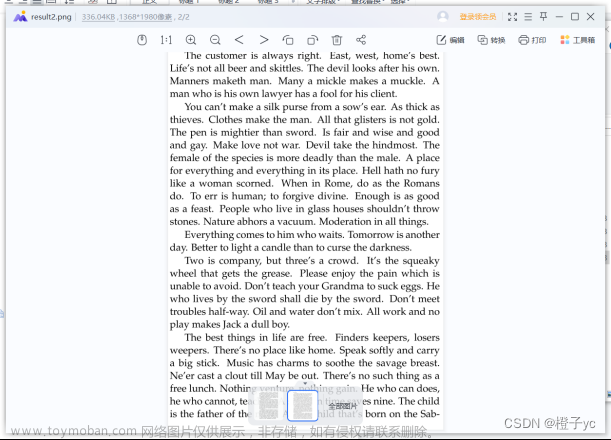
通过上述算法计算得到附件2的图片拼接顺序如下:
[3, 6, 2, 7, 15, 18, 11, 0, 5, 1, 9, 13, 10, 8, 12, 14, 17, 16, 4]
最终拼接得到的图片如下所示(result2.png文件):
问题二: 碎纸片拼接--纵切+横切
- 设计思路
相较于第一问,第二问的碎片加入了纵向的切割,且通过观察样本,可以得知有些图片存在空白行边缘,行与行之间有固定的间隔。本文先对图片中字的位置做特征提取,运用K-meanes聚类算法分出11类。得到每行的分类,对行内类元素进行相似度匹配排序。将行内排序好了的11行图片依据图片边缘相似度和行间距匹配度进行竖直方向的拼接。
- 算法步骤
- 对图像进行二值化处理
- 计算图片的行列数,求第一行、最后一行、第一列、最后一列的图像序号
通过对附件3所有图片计算图片与左边界的距离,得到11张距离相同、最大的图片作为第一列,同样计算图片与右边界的距离得到11张最后一列的图片序列。
其中,第一行和最后一行的计算可以在行聚类之后计算每行与底部的空白距离,也可以在此步骤进行计算,本文选择在聚类之后进行计算第一行和最后一行图片的序号。
3、对图像做掩码处理
图片存在首行缩进、段尾,会对行间的聚类有较大的影响,所以对这类图片进行掩码处理。首先计算统计出所有图片的空白行高度和字体高度,通过统计得到字宽和行宽,通过得到的字宽和行宽对以下三种图像进行掩码处理。如下为三种行空白掩码处理的结果:



4、特征提取
选择图片字像素所在的行数作为特征进行提取,如下图所示的红线即为该图片特征提取行数的示例图:

对于中文和英文碎片来说,其行间特征有不同,具体如图所示:

4、聚类
运用K-means算法进行聚类,可以得到11类行间类图片。
5、根据左右相似度进行行内排序,通过比较行间上下边缘相似度和上下行间距进行竖直方向的行间拼接。
其中相似度函数通过两个因素进行判断,一个是一行中归一化后灰度值为0的个数,一个是两行中像素相等的值,通过调整loss函数中两个因素的系数,计算相似度的值。
对于中文来说,特征提取可以直接统计该行灰度值是否等于列数,用于区分该位置(行)为空白行部分或文字部分;而对于英文的特征提取则需要用到灰度变化的斜率,当斜率大于一定值为空白行和字的交界处,从而用于判断提取空白行、文字位置特征。
python代码如下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
import skimage.io as io
from collections import Counter
from PIL import Image
import pandas as pd
from sklearn.cluster import KMeans#导入聚类模型
data_dir = './附件3'
path = data_dir +'/*.bmp'
coll = io.ImageCollection(path)#读入灰度图像
img_num = len(coll)
#*********转矩阵*******
img = np.asarray(coll)
for i in range(0,len(coll)):
img[i] = cv2.adaptiveThreshold(src=img[i], # 要进行处理的图片
maxValue=1, # 大于阈值后设定的值
adaptiveMethod=cv2.ADAPTIVE_THRESH_MEAN_C, # 自适应方法,ADAPTIVE_THRESH_MEAN_C:表区域内均值;ADAPTIVE_THRESH_GAUSSIAN_C:表区域内像素点加权求和
thresholdType=cv2.THRESH_BINARY, # 同全局阈值法中的参数一样
blockSize=11, # 方阵(区域)大小,
C=1) # 常数项,每个区域计算出的阈值的基础上在减去这个常数作为这个区域的最终阈值,可以为负数
print(img.shape)
#*******计算每张图片的左右边距*****
left = []
right = []
for i in range(0,img.shape[0]):
#计算每张图片同左边的距离
count = 0
for y in range(0,img.shape[2]):#列
panduan = 1
for x in range(0,img.shape[1]):#行
if(img[i][x][y]==0):
panduan = 0
break
if(panduan==1):
count = count+1
else:
break
left.append(count)
#计算每张图片同右边的距离
count = 0
for y in range(img.shape[2]-1, -1, -1):#列
panduan = 1
for x in range(0,img.shape[1]):#行
if(img[i][x][y]==0):
panduan = 0
break
if(panduan==1):
count = count+1
else:
break
right.append(count)
plt.scatter(range(0,len(left)),left)
plt.scatter(range(0,len(right)),right)
print(Counter(left))
print(Counter(right))
#*****确定行数********
#可以从图中找到11个最右边和最左边的图片
#剩余的点 中可以计算 行间距
#从散点图可以看出 行数为11
#列数为 209/11 = 19 209为img.shape[0]
fenge = 10 #看图确定 或 通过计算得出count的平均值
col = 19 #列数
row = 11 #行数 left 或 right 中count值大于 fenge的个数
#**********最后一列图片***********
end_index = []
for i in range(0,len(right)):
if(right[i]>=fenge):
end_index.append(i)
len(end_index)
#**********找出第一列的图片index*******
first_index = []
for i in range(0,len(left)):
if(left[i]>=fenge):
first_index.append(i)
len(first_index)
kong_width = []
zi_width = []
#********计算每张图片连续的1和0的长度********
for i in range(0,img.shape[0]):
width = 0
zj_kong = []
zj_zi = []
if(sum(img[i][0])==img.shape[2]):#空白行
qian = 0
else:
qian = 1
for x in range(0,img.shape[1]):
if(sum(img[i][x])!=img.shape[2]):#字
xian = 0
else:
xian = 1
if(qian!=xian):
if(qian == 0):
if(width):
zj_zi.append(width)
else:
if(width):
zj_kong.append(width)
width = 0
else:
width = width + 1
qian = xian
if(qian==0):#最后一行处理
zj_zi.append(width)
else:
zj_kong.append(width)
kong_width.append(zj_kong)
zi_width.append(zj_zi)
print(kong_width[0])
print(zi_width[0])
#统计分析
#得出字宽为40、39、38 空白行宽度为27、26、28
ans = []
for i in kong_width:
for j in i:
ans.append(j)
plt.scatter(range(0,len(ans)),ans)
print("空白行宽度统计:"+str(Counter(ans)))
ans = []
for i in zi_width:
for j in i:
ans.append(j)
plt.scatter(range(0,len(ans)),ans)
print("字宽统计:"+str(Counter(ans)))
img1 = img
#掩码补全 对于段首空行和段尾空行处理 为聚类做预处理
chuli_index_1 = []#需处理的图片 index 分为两种情况 如果需处理的行在第一行 需找到下界字的边缘行数
chuli_index_2 = []#如果不在第一行 需找到上界字的边缘行数
count = 0
for i in kong_width:
index = 0
for j in i:
if(j>40):
if(index==0):
chuli_index_1.append(count)
else:
chuli_index_2.append(count)
break
index = index + 1
count = count + 1
print("进行掩码处理的图片数量:"+str(len(chuli_index_1)+len(chuli_index_2)))
print("第一类需掩码处理的图片数量"+str(len(chuli_index_1)))
print("第二类需掩码处理的图片数量"+str(len(chuli_index_2)))
#处理
#第一种情况 需找到下界字的边缘行数
for index in chuli_index_1:
#找到第一行
first_index_ = 0
for x in range(0,img.shape[1]):#行
if(sum(img[index][x])!=img.shape[2]):
break
first_index_ = x
if(x-27-40<0):
first = 0
else:
first = int(x-27-40)
for x in range(first,x-27):
for y in range(0,img.shape[2]):
img1[index][x][y] = 0
#第二种情况 需找到上界字的边缘行数
for index in chuli_index_2:
#找到上界行数
width = 0
zj_kong = []
hang = []
zj_zi = []
if(sum(img[index][0])==img.shape[2]):#空白行
qian = 0
else:
qian = 1
for x in range(0,img.shape[1]):
if(sum(img[index][x])!=img.shape[2]):#字
xian = 0
else:
xian = 1
if(qian!=xian):
if(qian == 0):
if(width):
zj_zi.append(width)
else:
if(width):
zj_kong.append(width)
hang.append(x)
width = 0
else:
width = width + 1
qian = xian
if(qian==0):#最后一行处理
zj_zi.append(width)
else:
zj_kong.append(width)
hang.append(x)
Max = 0
for i in range(0,len(zj_kong)):
if(zj_kong[i]>Max):
Max = zj_kong[i]
first_index_ = hang[i]-zj_kong[i]
if(first_index_+27+40>=img.shape[1]):
end = img.shape[1]
else:
end = first_index_ + 27 + 40
for x in range(first_index_+27,end):
for y in range(0,img.shape[2]):
img1[index][x][y] = 0
#***********聚类***********
#提取特征
tezhe = []
for i in range(0,img.shape[0]):
width = 0
zj = []
if(sum(img1[i][0])==img.shape[2]):#空白行
qian = 0
else:
qian = 1
for x in range(0,img.shape[1]):
if(sum(img1[i][x])!=img.shape[2]):#字
xian = 0
else:
xian = 1
if(qian!=xian):
if(width>10):#防止出现 文字中间有间隔部分的情况
zj.append(x)
width = 0
else:
width = width + 1
qian = xian
tezhe.append(zj)
ans = []
for i in range(0,len(tezhe)):
zj = []
zj.append(tezhe[i][0])
zj.append(tezhe[i][1])
# zj.append(tezhe[i][2])
# zj.append(tezhe[i][3])
ans.append(zj)
x_train = pd.DataFrame(ans)
kmeansmodel = KMeans(n_clusters=11, init='k-means++')
y_kmeans = kmeansmodel.fit_predict(x_train)
print("聚类结果统计:"+str(Counter(y_kmeans)))
#分类结果
ans = {}
count = 0
for i in y_kmeans:
if(i in ans.keys()):
ans[i].append(count)
else:
zj = []
zj.append(count)
ans[i] = zj
count += 1
ans_lei = ans
#*******行内排序******
img1 = img
img = np.asarray(coll)
for i in range(0,len(coll)):
img[i] = cv2.adaptiveThreshold(src=img[i], # 要进行处理的图片
maxValue=1, # 大于阈值后设定的值
adaptiveMethod=cv2.ADAPTIVE_THRESH_MEAN_C, # 自适应方法,ADAPTIVE_THRESH_MEAN_C:表区域内均值;ADAPTIVE_THRESH_GAUSSIAN_C:表区域内像素点加权求和
thresholdType=cv2.THRESH_BINARY, # 同全局阈值法中的参数一样
blockSize=11, # 方阵(区域)大小,
C=1) # 常数项,每个区域计算出的阈值的基础上在减去这个常数作为这个区域的最终阈值,可以为负数
hang_index = []
for i in range(0,len(ans_lei)):
ans_index = [] #用于记录的排序
ans_index.append(first_index[i]) #插入第一张图片的索引
count1 = 0
while(count1<len(ans_lei[y_kmeans[first_index[i]]])-2):
count1 = count1 + 1
Max = -1
index = 0
zj = ans_index[len(ans_index)-1]
for j in ans_lei[y_kmeans[first_index[i]]]:
if(ans_index.count(j)==1 or end_index.count(j)==1):
if(end_index.count(j)==1):
yc = j
continue
count = 0
for x in range(0,img.shape[1]):#遍历行遍历 左右元素
if(img[j][x][0]==img[zj][x][img.shape[2]-1] ):
if(img[j][x][0]==0):
count +=0.6
count = count + 1
count2 = abs(sum(img[j][0])-sum(img[zj][img.shape[1]-1]))
loss = count*0.5 -count1*0.8
if(loss>Max):
Max = loss
index = j
ans_index.append(index)
ans_index.append(yc)
print(ans_index)
hang_index.append(ans_index)
#******按行拼接图片查看效果********排序效果很好
ans_hang_img = []
for i in range(0,len(hang_index)):
ans_img = coll[hang_index[i][0]]
for j in range(0,len(hang_index[i])):
if(j==0):
continue
ans_img = np.hstack((ans_img, coll[hang_index[i][j]])) # 水平合并
ans_hang_img.append(ans_img)
im = Image.fromarray(ans_hang_img[5]) # to Image
img_ = np.array(ans_hang_img)
img_.shape#11行图片
#二值化 加快运算速度
for i in range(0,len(img_)):
img_[i] = cv2.adaptiveThreshold(src=img_[i], # 要进行处理的图片
maxValue=1, # 大于阈值后设定的值
adaptiveMethod=cv2.ADAPTIVE_THRESH_MEAN_C, # 自适应方法,ADAPTIVE_THRESH_MEAN_C:表区域内均值;ADAPTIVE_THRESH_GAUSSIAN_C:表区域内像素点加权求和
thresholdType=cv2.THRESH_BINARY, # 同全局阈值法中的参数一样
blockSize=11, # 方阵(区域)大小,
C=1) # 常数项,每个区域计算出的阈值的基础上在减去这个常数作为这个区域的最终阈值,可以为负数
#*******将以上拼接好的行图片进行竖方向的拼接
#***找到第一行index
Max = 0
first_hang_index = 0
for i in range(0,img_.shape[0]):
#计算每张行图片同顶部的距离
for x in range(0,img_.shape[1]):#行
if(sum(img_[i][x])!=img_.shape[2]):
if(x>Max):
Max = x
first_hang_index = i
break
#***找到最后一行index
Max = 0
end_hang_index = 0
for i in range(0,img_.shape[0]):
#计算每张行图片同顶部的距离
for x in range(img_.shape[1]-1,-1,-1):#行
if(sum(img_[i][x])!=img_.shape[2]):
if(179-x>Max):
Max =179- x
end_hang_index = i
break
#列排序
lie_index = []
lie_index.append(first_hang_index)#行排序 列的第一个 行图片index
while(1):
Max = -1
index = 0
zj = lie_index[len(lie_index)-1]
for j in range(0,img_.shape[0]):
if(lie_index.count(j)==1 or j == end_hang_index):
continue
count = 0
for y in range(0,img_.shape[2]):#遍历行遍历
if(img_[j][0][y]==img_[zj][img_.shape[1]-1][y] ):
if(img_[j][0][y]==0):
count +=0.3
count = count + 1
count1 = abs(sum(img_[j][0])-sum(img_[zj][img_.shape[1]-1]))
loss = count*0.5 -count1*0.3
if(loss>Max):
Max = loss
index = j
lie_index.append(index)
if(len(lie_index)>=img_.shape[0]-1):
break
lie_index.append(end_hang_index)
print("列排序:"+str(lie_index))
#******图片列拼接 输出最终拼接图片 基于拼接好的ans_hang_img图片矩阵
ans_img = []
ans_img = ans_hang_img[lie_index[0]]
for i in range(0,len(lie_index)):
if(i==0):
continue
ans_img = np.vstack((ans_img, ans_hang_img[lie_index[i]])) #
im = Image.fromarray(ans_img) # to Image
im.save('result3.png')
结果:
- 字宽和行宽
以下为中文字宽和行宽的个数统计,可以看出空白行宽的大小应为27、26、28;字宽的大小应为40、39、38。
空白行宽度统计:Counter({27: 177, 26: 80, 28: 74, 29: 28, 21: 15, 24: 14, 18: 14, 30: 13, 58: 13, 8: 13, 2: 10, 15: 10, 14: 9, 95: 9, 5: 9, 12: 8, 7: 8, 37: 8, 1: 7, 6: 7, 20: 6, 36: 5, 70: 5, 57: 5, 31: 4, 25: 4, 96: 4, 38: 3, 82: 3, 13: 3, 3: 3, 83: 3, 9: 3, 94: 2, 99: 2, 39: 2, 97: 2, 92: 1, 4: 1, 23: 1, 56: 1, 17: 1, 98: 1, 68: 1, 19: 1, 59: 1, 40: 1, 44: 1, 93: 1, 16: 1, 64: 1, 71: 1, 55: 1, 84: 1})
字宽统计:Counter({40: 137, 39: 134, 38: 61, 37: 33, 36: 19, 21: 17, 27: 16, 3: 15, 15: 15, 5: 14, 11: 14, 17: 14, 34: 13, 33: 12, 24: 11, 18: 10, 4: 10, 41: 9, 35: 8, 23: 5, 14: 4, 0: 4, 19: 4, 16: 3, 12: 3, 20: 3, 10: 3, 26: 2, 25: 2, 22: 2, 9: 2, 2: 1, 8: 1, 28: 1, 6: 1, 32: 1})
以下为英文字宽和行宽的个数统计,可以看出空白行宽的大小应为25;字宽的大小应为36、24、37。
空白行宽度统计:Counter({25: 93, 26: 61, 38: 59, 24: 50, 37: 43, 17: 34, 4: 32, 27: 28, 7: 26, 8: 24, 30: 18, 11: 17, 18: 16, 29: 15, 12: 14, 3: 12, 31: 11, 19: 10, 14: 10, 9: 9, 47: 8, 13: 8, 28: 8, 60: 6, 10: 6, 90: 5, 20: 5, 51: 5, 61: 5, 6: 5, 40: 5, 36: 4, 103: 4, 49: 4, 91: 3, 2: 3, 39: 3, 5: 3, 64: 3, 16: 3, 15: 2, 50: 2, 23: 2, 52: 2, 114: 1, 105: 1, 101: 1, 48: 1, 56: 1, 89: 1, 32: 1, 33: 1, 92: 1, 102: 1, 86: 1, 104: 1})
字宽统计:Counter({36: 98, 24: 96, 37: 89, 35: 46, 23: 38, 34: 37, 1: 31, 5: 28, 31: 25, 2: 23, 50: 21, 22: 19, 0: 17, 32: 13, 13: 13, 21: 11, 14: 9, 49: 8, 4: 8, 9: 7, 3: 5, 30: 5, 33: 5, 27: 4, 45: 4, 12: 3, 48: 3, 20: 3, 11: 2, 7: 2, 6: 2, 41: 1, 47: 1, 40: 1, 17: 1, 28: 1, 8: 1, 43: 1, 15: 1, 42: 1})
- K-mewns聚类结果:
如下为聚类类别统计:

如下为每张图片所属的类别序号:
[ 4, 3, 2, 5, 6, 9, 1, 4, 0, 0, 9, 2, 5, 8, 5, 7, 8,
7, 3, 1, 1, 8, 2, 3, 0, 0, 3, 7, 2, 9, 3, 5, 4, 7,
10, 0, 1, 9, 0, 5, 6, 3, 10, 10, 9, 4, 0, 10, 9, 2, 3,
5, 1, 4, 2, 9, 4, 2, 10, 9, 7, 1, 3, 1, 9, 2, 8, 1,
4, 1, 4, 7, 1, 5, 0, 9, 3, 10, 1, 1, 7, 0, 5, 7, 10,
7, 3, 3, 0, 6, 10, 2, 9, 4, 10, 2, 1, 10, 9, 1, 3, 6,
6, 0, 9, 0, 8, 5, 6, 8, 8, 9, 10, 6, 6, 5, 1, 6, 2,
6, 3, 10, 0, 6, 10, 8, 4, 10, 5, 2, 0, 1, 7, 7, 5, 5,
10, 4, 4, 8, 6, 2, 3, 2, 10, 8, 6, 3, 0, 10, 8, 6, 7,
4, 6, 6, 7, 8, 4, 5, 5, 0, 1, 1, 10, 7, 4, 0, 3, 5,
7, 9, 9, 8, 4, 4, 5, 1, 2, 3, 9, 8, 8, 10, 8, 6, 2,
8, 2, 0, 2, 3, 2, 0, 6, 3, 4, 8, 7, 5, 7, 9, 7, 5,
8, 7, 9, 6, 4]
- 行列排列顺序
行内排序:
[7, 208, 138, 158, 126, 68, 175, 45, 174, 0, 137, 53, 56, 93, 153, 70, 166, 32, 196]
[14, 128, 3, 159, 82, 199, 135, 12, 73, 160, 203, 169, 134, 39, 31, 51, 107, 115, 176]
[29, 64, 111, 201, 5, 92, 180, 48, 37, 75, 55, 44, 206, 10, 104, 98, 172, 171, 59]
[38, 24, 35, 81, 189, 122, 103, 130, 193, 88, 167, 25, 8, 105, 161, 9, 46, 148, 74]
[49, 54, 65, 143, 186, 2, 57, 192, 178, 118, 190, 95, 11, 22, 129, 28, 91, 188, 141]
[61, 19, 78, 67, 69, 99, 162, 96, 131, 79, 63, 116, 163, 72, 6, 177, 20, 52, 36]
[71, 156, 80, 33, 202, 198, 15, 133, 170, 205, 85, 152, 165, 27, 83, 132, 200, 17, 60]
[89, 146, 4, 101, 113, 194, 119, 114, 40, 151, 207, 155, 140, 185, 108, 117, 102, 154, 123]
[94, 34, 84, 183, 90, 47, 121, 42, 124, 144, 77, 112, 149, 97, 136, 164, 127, 58, 43]
[125, 13, 182, 109, 197, 16, 184, 110, 187, 66, 106, 150, 21, 173, 157, 181, 204, 139, 145]
[168, 100, 76, 62, 142, 30, 41, 23, 147, 191, 50, 179, 120, 86, 195, 26, 1, 87, 18]
列排序:
[4, 5, 1, 8, 9, 2, 0, 10, 3, 6, 7]
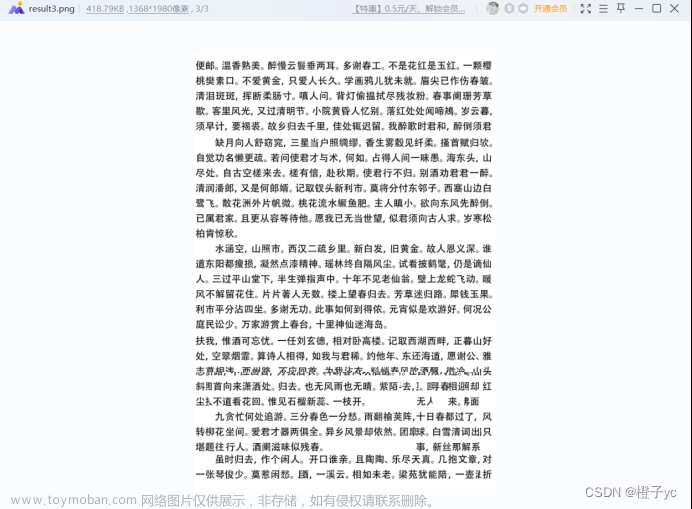
- 图片复原结果
如下图所示(result3.png文件)文章来源:https://www.toymoban.com/news/detail-526462.html
 文章来源地址https://www.toymoban.com/news/detail-526462.html
文章来源地址https://www.toymoban.com/news/detail-526462.html
到了这里,关于(数学建模)2013年国赛B题-碎纸片复原python代码的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!