Kafka消费者是pull(拉)还是push(推)模式,这种模式有什么好处?
一、概述回答
Kafka中的Producer和consumer采用的是push-and-pull模式,即Producer只管向broker push消息,consumer只管从broker pull消息,两者对消息的生产和消费是异步的。
二、这种模式的好处是什么
1、控制权
使用pull(拉)模式主动权在消费者,消费者可以自由控制拉取数据的频率和数量,进而更好的控制消费的进度,更好的适应不同的使用场景。
2、异步处理
使用pull模式的消费者可以异步处理消息,即在拉取到消息之后不需要立即进行处理,可以选择在适当的时候进行处理,从而提高了系统的吞吐量和并发性能。
3、消费者本地缓存
使用pull模式的消费者,可以在本地缓存拉取到消息,从而降低频繁地I/O操作对系统性能的影响。同时,缓存一定量的消息,消费者还可以避免在消费方出现问题时丢失未被处理的消息。
Kafka消费者在拉取消息后,默认会将消息缓存在本地。这样做的目的是为了提高消费性能和降低对Kafka服务的依赖。
Kafka消费者会从Broker中拉取一批消息,并将这些消息缓存在本地的内存中,以供应用程序进一步处理。消费者可以自由控制批量拉取的大小和频率,以满足应用程序的需求。缓存可以减少与Kafka服务器的网络交互次数,提高了消费者的吞吐量。
消费者在缓存消息时,会根据配置的提交偏移量(offset)的策略,将拉取到的消息的偏移量提交到Kafka服务器。这样做可以确保消费者在下次拉取消息时,能够从正确的位置开始读取。
需要注意的是,消息缓存在消费者端的内存中,如果消费者进程或服务异常终止,缓存中的消息会丢失。因此,消费者需要定期将处理过的消息持久化,或者使用自动提交偏移量到Kafka服务器,以便在重启后可以从正确的位置继续消费。文章来源:https://www.toymoban.com/news/detail-526741.html
三、这种模式有什么缺点,如何规避
1、Kafka消费者在拉取时会在一段时间内频繁的向Kafka服务器发送请求,这个过程中会大量的使用网络带宽,如果每个消费者都这么做就会浪费当了的带宽。
规避方法:
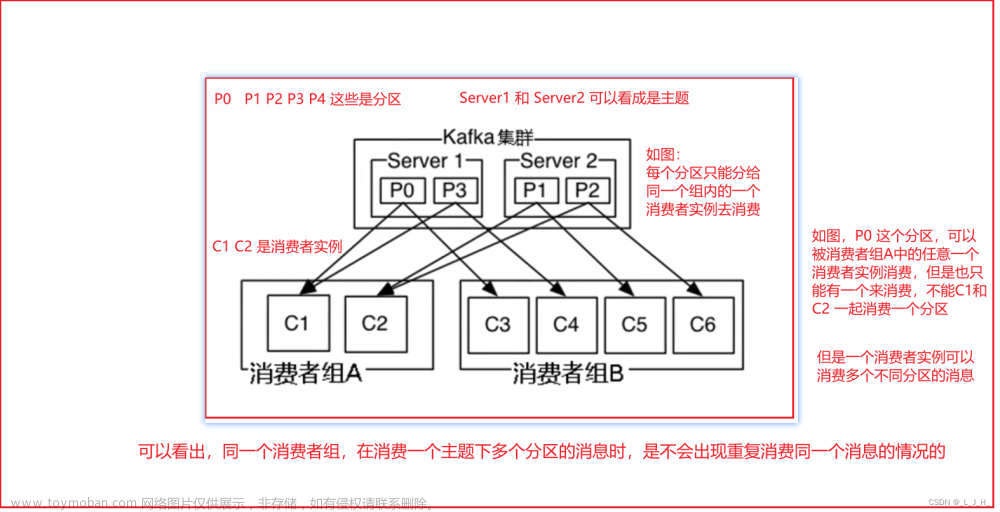
使用Kafka集群提供的Consumer Group能力,多个消费者共同消费一个主题,每个消费者只消费被分配到的分区的数据,而不是整个主题的数据,这样就能避每个消费者都向Kafka服务器频繁的请求数据。文章来源地址https://www.toymoban.com/news/detail-526741.html
到了这里,关于【Kafka面试题1】Kafka消费者是pull(拉)还是push(推)模式,这种模式有什么好处?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!