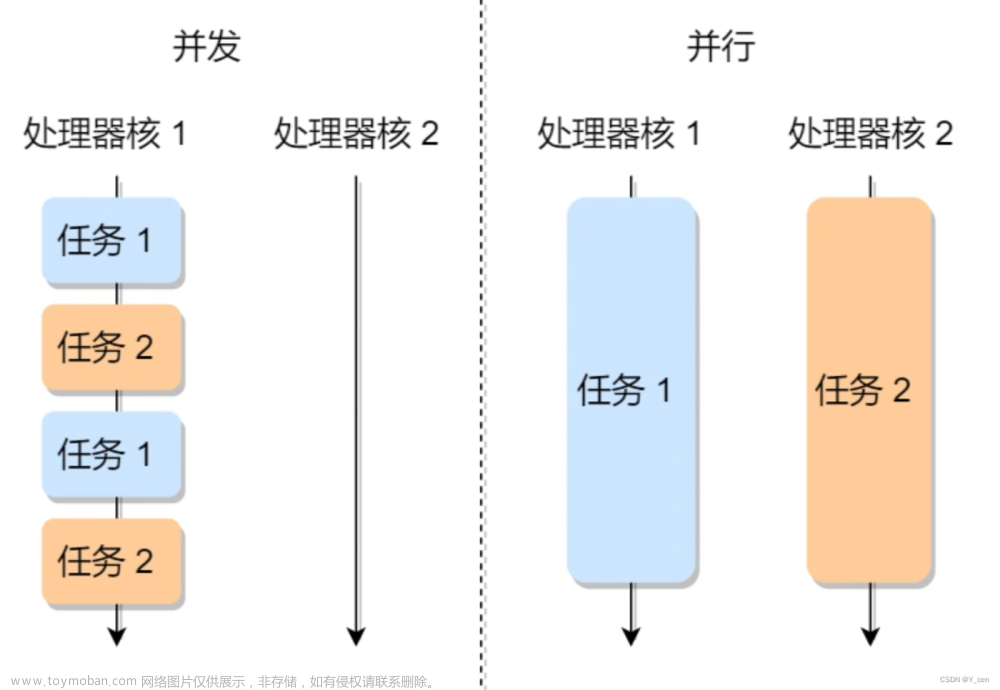
引言
上篇介绍了 ThreadPoolExecutor 配置和扩展相关的信息,本篇开始将介绍递归算法的并行化。
还记得我们在《Java并发编程学习11-任务执行演示》中,对页面绘制程序进行一系列改进,这些改进大大地提供了页面绘制的并行性。
我们简单回顾下相关的改进过程:
- 第一次新增时,页面绘制程序完全是串行执行;
- 第二次改进时,虽然用了两个线程,并行地执行了两个不同类型的任务【下载图像和渲染文本】,但它们仍然是串行地下载所有图像。
- 最后一次改进,将每个图像的下载操作视为一个独立任务,实现了更高的并发性。
从上面的改进过程中,我们可以看出:
如果循环中的迭代操作都是独立的,并且不需要等待所有的迭代操作都完成再继续执行,那么就可以使用
Executor将串行循环转换为并行循环。
1. 串行循环转并行循环
下面我们来看一下如下的示例【将串行执行转换为并行执行】:
public class Process {
/**
* 串行循环
*
* @param elements 待处理的数据列表
*/
public static void processSequentially(List<Element> elements) {
for (Element e : elements)
process(e);
}
/**
* 并行循环
*
* @param exec 线程池对象
* @param elements 待处理的数据列表
*/
public static void processInParallel(Executor exec, List<Element> elements) {
for (final Element e : elements)
exec.execute(new Runnable() {
@Override
public void run() {
process(e);
}
});
}
private static void process(Element e) {
// 处理单个数据
}
}
在上述的示例中,processInParallel 方法会在所有下载任务都进入了 Executor 的队列后就立即返回,而不会等待这些任务全部完成,因此调用 processInParallel 比调用 processSequentially 能更快地返回。
当串行循环中的各个迭代操作之间彼此独立,并且每个迭代操作执行的工作量比管理一个新任务时带来的开销更多,那么这个串行循环就适合并行化。
2. 串行递归转并行递归
在递归的算法中通常都会存在串行循环,这就可以用上面 1 中的方式进行并行化。
如果在每个迭代操作中,都不需要来自后续递归迭代的结果,那可以参考下面的 parallelRecursive 方法来对递归进行并行化改进:
public class Process {
/**
* 串行递归
*
* @param nodes 树节点集合
* @param results 结果集合
* @param <T> 树中元素的类型
*/
public static <T> void sequentialRecursive(List<Node<T>> nodes, Collection<T> results) {
for (Node<T> n : nodes) {
results.add(n.compute());
sequentialRecursive(n.getChildren(), results);
}
}
/**
* 并行递归
*
* @param exec 线程池对象
* @param nodes 树节点集合
* @param results 结果集合
* @param <T> 树中元素的类型
*/
public static <T> void parallelRecursive(final Executor exec, List<Node<T>> nodes, final Collection<T> results) {
for (final Node<T> n : nodes) {
exec.execute(new Runnable() {
@Override
public void run() {
results.add(n.compute());
}
});
parallelRecursive(exec, n.getChildren(), results);
}
}
}
上述示例中,
-
串行递归
sequentialRecursive方法,用深度优先算法遍历一棵树,在每个节点上执行计算并将结果放到一个集合里 -
并行递归
parallelRecursive方法,同样用深度优先遍历,但它并不是在访问节点时进行计算,而是为每个节点提交一个任务来完成计算。
当 parallelRecursive 返回时,树中的各个节点都已经访问过了,并且每个节点的计算任务也已经放入 Executor 的工作队列。
注意:
parallelRecursive中遍历树的过程仍然是串行的,只有树节点的计算操作才是并行执行的。
既然上面树节点计算已经并行,那么 sequentialRecursive 方法的调用者该如何获取所有的结果呢???
这就需要创建一个特定于遍历过程的 Executor,并使用 shutdown 和 awaitTermination 等方法。
下面我们来看一下如下的示例【等待通过并行方式计算的结果】:
/**
* 等待通过并行方式计算的结果
*
* @param nodes 树节点集合
* @param <T> 树中元素的类型
* @return 计算结果集合
*/
public static <T> Collection<T> getParallelResults(List<Node<T>> nodes) throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
Queue<T> resultQueue = new ConcurrentLinkedDeque<>();
parallelRecursive(exec, nodes, resultQueue);
exec.shutdown();
exec.awaitTermination(Long.MAX_VALUE, TimeUnit.SECONDS);
return resultQueue;
}
3. 谜题
我们已经从上面初步了解了串行转并行的一些内容,其实这项技术的一个重要应用就是解决一些谜题,例如 “搬箱子”、“Hi-Q”、“四色方柱” 和 棋牌谜题等,这些谜题都需要找出一系列的操作从初始状态转换到目标状态。
现在我们给出谜题的定义,包含如下:
- 一个初始位置
- 一个目标位置
- 一个用于判断是否有效移动的规则集。它包含两部分:
- 计算从指定位置开始的所有合法移动
- 每次移动的结果位置
下面我们来看一下如下的示例【它表示 “搬箱子” 之类谜题的接口类】:
public interface Puzzle<P, M> {
P initialPosition();
boolean isGoal(P position);
Set<M> legalMoves(P position);
P move(P position, M move);
}
上述 Puzzle 表示谜题的接口类,其中的类型参数 P 和 M 表示位置类和移动类。
有了谜题的定义,我们再来看看谜题位置的定义【它用于谜题解决框架的链表节点】:
@Immutable
public class Node<P, M> {
final P pos;
final M move;
final Node<P, M> prev;
public Node(P pos, M move, Node<P, M> prev) {
this.pos = pos;
this.move = move;
this.prev = prev;
}
public List<M> asMoveList() {
List<M> solution = new LinkedList<>();
for (Node<P, M> n = this; n.move != null; n = n.prev)
solution.add(0, n.move);
return solution;
}
}
上述示例中,Node 代表通过一系列的移动到达的一个位置,其中保存了到达该位置的移动以及前一个 Node。只要沿着 Node 链接逐步回溯,就可以重新构建出到达当前位置的移动序列。
3.1 串行的谜题解答器
有了 Puzzle 和 Node,我们现在可以写一个简单的谜题框架的串行求解程序,该程序将在谜题空间中执行一个深度优先搜索,直到找到一个解答(当然这不一定是最短的解决方案)或者找遍了整个空间都没有发现答案。
下面我们来看一下如下的示例【串行的谜题解答器】:
public class SequentialPuzzleSolver<P, M> {
private final Puzzle<P, M> puzzle;
private final Set<P> seen = new HashSet<>();
public SequentialPuzzleSolver(Puzzle<P, M> puzzle) {
this.puzzle = puzzle;
}
public List<M> solve() {
P pos = puzzle.initialPosition();
return search(new Node<P, M>(pos, null, null));
}
private List<M> search(Node<P, M> node) {
if (!seen.contains(node.pos)) {
seen.add(node.pos);
if (puzzle.isGoal(node.pos))
return node.asMoveList();
for (M move : puzzle.legalMoves(node.pos)) {
P pos = puzzle.move(node.pos, move);
Node<P, M> child = new Node<P, M>(pos, move, node);
List<M> result = search(child);
if (result != null)
return result;
}
}
return null;
}
}
3.2 并发的谜题解答器
上面 3.1 中我们已经介绍了串行的谜题解答器 SequentialPuzzleSolver,那么下面我们来分析看看它哪里有可以利用的并发改进?
简单分析下,计算某次移动的过程在很大程度上与计算其他移动的过程是相互独立的,因此我们可以以并行方式来计算下一步移动以及目标条件。
当然这里说“很大程度上”,是因为在各个任务之间会共享一些可变状态,例如已遍历位置的集合。
下面我们来看一下如下的示例【并发的谜题解答器】:
public class ConcurrentPuzzleSolver<P, M> {
private final Puzzle<P, M> puzzle;
private final ExecutorService exec;
private final ConcurrentMap<P, Boolean> seen;
final ValueLatch<Node<P, M>> solution = new ValueLatch<>();
public ConcurrentPuzzleSolver(Puzzle<P, M> puzzle, ExecutorService exec, ConcurrentMap<P, Boolean> seen) {
this.puzzle = puzzle;
this.exec = exec;
this.seen = seen;
}
public List<M> solve() throws InterruptedException {
try {
P p = puzzle.initialPosition();
exec.execute(newTask(p, null, null));
// 阻塞直到找到解答
Node<P, M> solnNode = solution.getValue();
return (solnNode == null) ? null : solnNode.asMoveList();
} finally {
exec.shutdown();
}
}
protected Runnable newTask(P p, M m, Node<P, M> n) {
return new SolverTask(p, m, n);
}
private class SolverTask extends Node<P, M> implements Runnable {
SolverTask(P p, M m, Node<P, M> n) {
super(p, m, n);
}
@Override
public void run() {
if (solution.isSet() || seen.putIfAbsent(pos, true) != null)
return; // 已经找到了解答 或者 已经遍历了这个位置
if (puzzle.isGoal(pos))
solution.setValue(this);
else
for (M m : puzzle.legalMoves(pos))
exec.execute(newTask(puzzle.move(pos, m), m, this));
}
}
}
在上面的并发的谜题解答器 ConcurrentPuzzleSolver 中,我们使用了一个内部类 SolverTask,该类扩展了 Node 并实现了 Runnable 接口,其中它的 run 方法实现了如下的功能:
- 首先计算出下一步可能到达的所有位置,并去掉已经达到的位置;
- 然后判断(这个任务或者其他某个任务)是否已经成功地完成;
- 最后将尚未搜索过的位置提交给
Executor。
还记得上面我们在串行版本中引入了一个 Set 对象,它的作用就是为了避免无限循环,其中保存了之前已经搜索过的所有位置信息。
同样在 ConcurrentPuzzleSolver 中,我们使用 ConCurrentHashMap 也实现了相同的功能。这种做法不仅提供了线程安全性,还避免了在更新共享集合时存在的竞态条件,因为 putIfAbsent 只有在之前没有遍历过的某个位置才会通过原子方式添加到集合中。
上述串行版本的谜题解答器,执行深度优先搜索,因此搜索过程将受限于栈的大小。而并发版本的谜题解答器执行广度优先搜索,因此不会受到栈大小的限制(但如果待搜索的或者已搜索的位置集合大小超过了可用的内存总量,那么仍可能耗尽内存)。
下面我们来思考一下,并发场景下,我们如何才能在找到某个解答后停止搜索呢???
很显然,这个时候就需要通过某种方式来检查是否有线程已经找到了一个解答。
细心的读者可能已经发现了,在 ConcurrentPuzzleSolver 中我们定义了 ValueLatch,它是使用 CountDownLatch 来实现所需的闭锁行为,并且使用锁定机制来确保解答只会被设置一次。
@ThreadSafe
public class ValueLatch<T> {
@GuardedBy("this")
private T value = null;
private final CountDownLatch done = new CountDownLatch(1);
public boolean isSet() {
return (done.getCount() == 0);
}
public synchronized void setValue(T newValue) {
if (!isSet()) {
value = newValue;
done.countDown();
}
}
public T getValue() throws InterruptedException {
done.await();
synchronized (this) {
return value;
}
}
}
每个任务首先查询 solution 闭锁,找到一个解答就停止。而在此之前,主线程需要等待,ValueLatch 中的 getValue 将一直阻塞,直到有线程设置了这个值。
ValueLatch 提供了一种方式来保存这个值,只有第一次调用才会设置它。调用者能够判断这个值是否已经被设置,以及阻塞并等候它被设置。在第一次调用 setValue 时,将更新解答方案,并且 CountDownLatch 会递减,从 getValue 中释放主线程。
第一个找到解答的线程还会关闭 Executor,从而阻止接受新的任务。如果要避免处理 RejectedExecutionException,需要将拒绝执行处理器设置为 “抛弃已提交的任务”。然后,所有未完成的任务最终将执行完成,并且在执行任何新任务时都会失败,从而使 Executor 结束。
3.3 无解答的并发解答器
讲到这里都是说的有某个解答的情况,如果谜题本身就不存在解答的话,那 ConcurrentPuzzleSolver 就无法很好地处理这种情况了:如果已经遍历了所有的移动位置都没有找到解答,那么在 getValue 调用中将永远等待下去。
那么并发场景下,如果没有解答,有没有什么方法可以结束程序呢?
有一种方法就是记录活动任务的数量,当该值为零时将解答设置为 null。
下面我们来看一下如下的示例【在解答器中找不到解答的场景】:
public class PuzzleSolver<P, M> extends ConcurrentPuzzleSolver<P, M> {
private final AtomicInteger taskCount = new AtomicInteger(0);
public PuzzleSolver(Puzzle<P, M> puzzle, ExecutorService exec, ConcurrentMap<P, Boolean> seen) {
super(puzzle, exec, seen);
}
protected Runnable newTask(P p, M m, Node<P, M> n) {
return new CountingSolverTask(p, m, n);
}
class CountingSolverTask extends SolverTask {
CountingSolverTask(P pos, M move, Node<P, M> prev) {
super(pos, move, prev);
taskCount.incrementAndGet();
}
@Override
public void run() {
try {
super.run();
} finally {
if (taskCount.decrementAndGet() == 0)
solution.setValue(null);
}
}
}
}
3.4 进一步的改进
我们知道,真实解题时,找到解答的时间可能比等待的时间要长,因此在解答器中还需要包含下面的结束条件:文章来源:https://www.toymoban.com/news/detail-527288.html
- 时间限制。这种可以在
ValueLatch中实现一个限时的getValue(其中将使用限时版本的await),如果getValue超时,那么关闭Executor并声明出现一个失败。 - 达到最大搜索深度或步数。为了避免无限循环或无限搜索的情况,可以设置一个最大搜索深度或步数作为结束条件。当解答器达到了这个限制时,搜索将终止
- 用户中断。在一些交互式的谜题解答环境中,用户可以随时中断解答器的执行,提前结束搜索过程
总结
对于可以并发执行的任务,Executor 框架提供了大量可调节的选项,例如创建线程和关闭线程的策略,处理队列任务的策略,处理过多任务的策略,并且提供了几个钩子方法来扩展它的行为。通过使用这些可调节的选项,我们可以根据具体需求来配置和扩展 Executor 框架的行为,以满足不同的并发处理需求。文章来源地址https://www.toymoban.com/news/detail-527288.html
到了这里,关于Java并发编程学习18-线程池的使用(下)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!