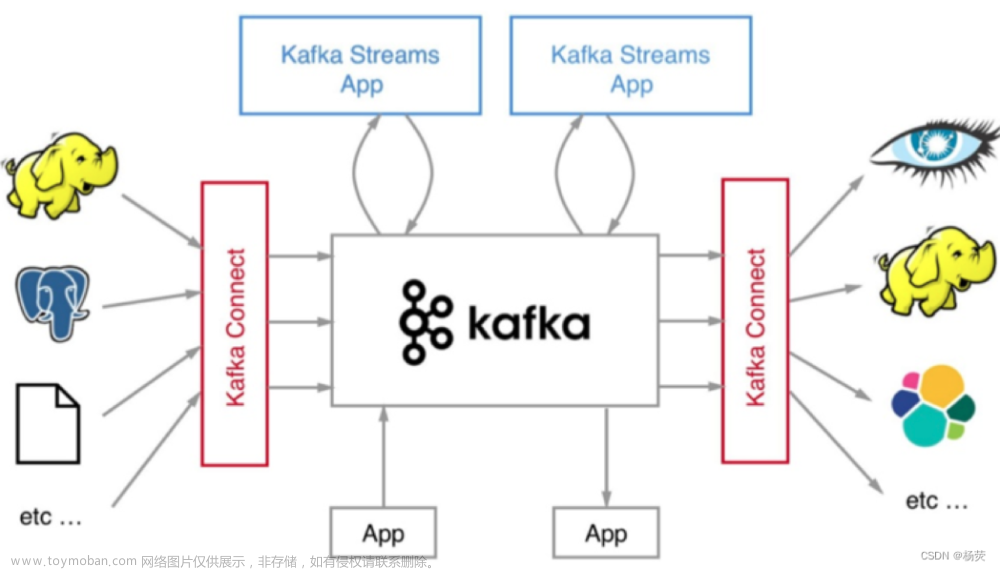
上一篇文章是生产数据:python向kafka发送json数据_grfstc的博客-CSDN博客
1.安装kafka支持库
pip install kafka-python
2.创建python文件
import time
from kafka import KafkaConsumer
consumer = KafkaConsumer(
'FaultRecordLog',
group_id='test_id',
bootstrap_servers=['192.168.1.214:9092'], # 要发送的kafka主题
auto_offset_reset='earliest', # 有两个参数值,earliest和latest,如果省略这个参数,那么默认就是latest
)
for msg in consumer:
print(msg)
print(f"topic = {msg.topic}") # topic default is string
print(f"partition = {msg.partition}")
print(f"value = {msg.value.decode()}") # bytes to string
print(f"timestamp = {msg.timestamp}")
print("time = ", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(msg.timestamp / 1000)))
3.运行该python文件
 注意:
注意:
该python文件会持续消费kafka数据,如果要停止消费,需手动退出程序。

或者可以设置达到特定偏移量退出for循环来停止消费:
lastOffset = 42
for msg in consumer:
print(msg)
print(f"topic = {msg.topic}") # topic default is string
print(f"partition = {msg.partition}")
print(f"value = {msg.value.decode()}") # bytes to string
print(f"timestamp = {msg.timestamp}")
print("time = ", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(msg.timestamp / 1000)))
if msg.offset == lastOffset - 1:
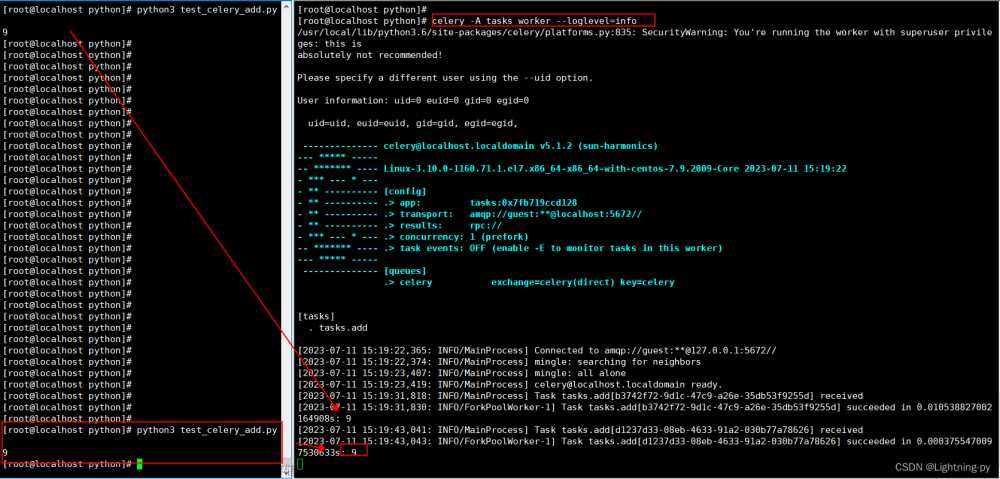
break运行效果:

文章来源地址https://www.toymoban.com/news/detail-528635.html
文章来源:https://www.toymoban.com/news/detail-528635.html
到了这里,关于python消费kafka数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!