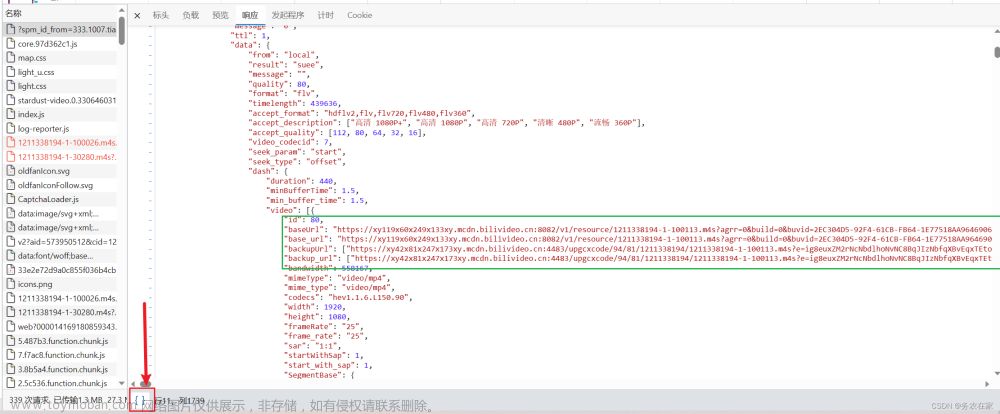
还是很久之前写的爬虫,爬取某站的视频,因为某站的视频和音频是分开的,所以最后还需要合成在一起。
某站的舞蹈区大家都知道有很多的黑丝、白丝。嗯。。。都懂的,所以,下载下来被窝里偷偷看。
详细解释都在注释区文章来源:https://www.toymoban.com/news/detail-528709.html
大家爬取的时候要注意延时一段时间,某站的访问量是很大。太快爬取会被封的。文章来源地址https://www.toymoban.com/news/detail-528709.html
import requests
from fake_useragent import UserAgent
import jsonpath
import re
import os
import time
# 请求头
headers = {"User-Agent": UserAgent().random,
"referer": "你自己的refer"}
# 创建存放视频的文件夹
if not os.path.exists("创建的文件夹名"):
os.mkdir("创建的文件夹名")
# 更改文件路径
os.chdir(r"你想要存放的路径")
# # 视频列表页url
for i in range(1, 3):
# 因审核的原因,接口不能放出来,大家可以自行找找接口,加上即可食用
# 获取up主的视频列表接口。mid=后面的一串数字更改为其他up主的,即可爬取其他up主的视频列表页
url = "up主的视频列表接口"
time.sleep(0.5)
response = requests.get(url, headers=headers).json()
# 解析网页
bvid = jsonpath.jsonpath(response, "$..bvid")
# 拼接网址
link = "某站的网址后加上 /video/ 即可"
detail_url = [link + i for i in bvid]
# 循环下载
for url_link in detail_url:
time.sleep(0.3)
res = requests.get(url_link, headers=headers).text
# 提取视频名
title = re.findall(r'class="video-title tit">(.*?)</h1>', res)
title = [re.sub("/", "", i) for i in title]
# 提示视频
str = re.findall('<script>window.__playinfo__=(.*?)</script>', res)[0]
vid = re.findall(r'"video":\[{"id":\d+,"baseUrl":"(.*?)"', str)
# 提取音频
aud = re.findall(r'"audio":\[{"id":\d+,"baseUrl":"(.*?)"', str)
# 下载视频音频
for n, v, a in zip(title, vid, aud):
vid_res = requests.get(url=v, headers=headers).content
aud_res = requests.get(url=a, headers=headers).content
print("Downloading", n)
with open(f'{n}.mp4', "wb") as f:
f.write(vid_res)
with open(f'{n}.mp3', "wb") as f:
f.write(aud_res)
# 因为该站是将音频和视频分开的,所以需要将下载视频音频进行合成为一个完成的视频。
os.system(f'ffmpeg.exe -i {n}.mp4 -i {n}.mp3 -c copy {n + " new"}.mp4')
到了这里,关于黑丝,白丝,全都要。某站的视频爬取加合成的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!