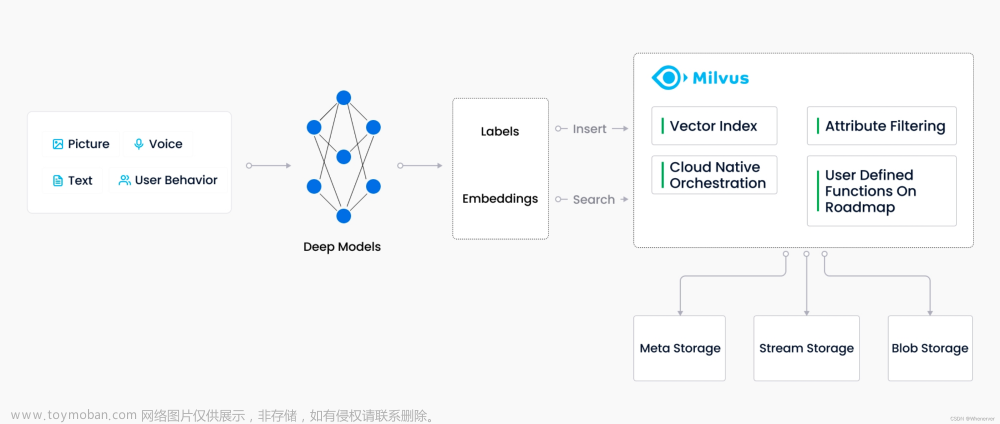
Milvus 特点
- 在万亿矢量数据集上实现惊人的搜索速度:在万亿矢量数据集上,矢量搜索和检索的平均延迟可达毫秒级。
- 简化的非结构化数据管理: Milvus 拥有专为数据科学工作流程设计的丰富 API。
- 可靠、始终在线的矢量数据库: Milvus 内置的复制和故障转移/故障恢复功能可确保数据和应用程序始终保持业务连续性。
- 高度可扩展和弹性: 组件级可扩展性使按需扩减成为可能。
- 混合搜索: 除了向量之外,Milvus 还支持布尔、字符串、整数、浮点数等数据类型。标量和向量可以混合过滤。
- 统一的 Lambda 结构: Milvus 将流式处理和批式处理相结合进行数据存储,平衡时效性和效率。
- 时间旅行: Milvus 维护所有数据插入和删除操作的时间线。它允许用户在搜索中指定时间戳以检索指定时间点的数据视图。
- 社区支持和行业认可:拥有超过 1,000 名企业用户、 GitHub 上超过 10,500 颗星以及活跃的开源社区,以及商业公司支持。
Milvus 架构
Milvus 独立版
Milvus 独立版包含三个组件:
- Milvus: 核心功能组件。
- etcd: 元数据引擎,访问并存储 Milvus 内部组件的元数据,包括 proxy、indexnode 等。
- MinIO: 存储引擎,负责 Milvus 的数据持久化。

Milvus 集群版
Milvus 集群版包含 8 个微服务组件和 3 个第三方依赖项。所有微服务都可以部署在 Kubernetes 上,彼此独立。
微服务组件
- Root coord: 负责处理数据定义语言(DDL)和数据控制语言(DCL)请求,管理 TSO(timestamp Oracle),并发布时间刻度消息。
- Proxy: 代理是用户访问 Milvus 的入口,负责不同请求的转发。
- Query coord: 负责管理查询节点的拓扑结构和负载均衡,以及从 growing segment 到 sealed segment 的转换操作。
- Query node: 负责对增量数据和历史数据执行向量和标量数据的混合搜索。
- Index coord: 负责管理索引节点的拓扑结构,并维护索引元数据。
- Index node: 负责为向量构建索引。
- Data coord: 负责管理数据节点的拓扑结构,维护元数据,触发 flush、compact 等后台数据操作。
- Data node: 数据节点通过订阅日志代理来获取增量日志数据,处理 mutation 请求,并将日志数据打包成日志快照存储在对象存储中。
第三方依赖项
- etcd: 存储集群中各个组件的元数据。
- MinIO: 负责集群中大文件的数据持久化,比如索引、二进制日志文件。
- Pulsar: 管理近期变异操作的日志,输出流式日志,并提供日志发布订阅服务。

集群版分层详细架构
Milvus 采用共享存储架构,存储和计算分离,计算节点可水平扩展。Milvus 遵循数据平面和控制平面分离的原则,包括四层:接入层、协调服务层、计算层和存储层。

接入层
访问层是整个系统的入口,将客户端连接的端点暴露给用户。它负责处理客户端连接、进行静态验证、对用户请求的基本动态检查、转发请求以及收集结果并将结果返回给客户端。代理本身是无状态的,可以借助负载均衡组件(Nginx、Kubernetes的Ingress、NodePort、LVS)向外界提供统一的访问地址和服务。
协调服务层
协调服务是系统的大脑,负责集群拓扑节点管理、负载均衡、时间戳生成、数据声明和数据管理。
计算层
包含所有的 QueryNode 和 DataNode,执行协调器服务发出的指令和代理启动的数据操作语言 (DML) 命令。Milvus 中的工作节点类似于 Hadoop 中的数据节点。
存储层
存储层是 Milvus 的基石,负责数据持久化。存储层分为三部分:
- Meta store: 负责存储元数据的快照,如集合 schema、节点状态、消息消费检查点等。Milvus 依赖 etcd 来实现这些功能,Etcd 还承担服务注册和健康检查的责任。
- 日志代理: 支持播放的 pub/sub 系统,负责流数据持久化、可靠的异步查询执行、事件通知和返回查询结果。当节点进行停机恢复时,日志代理通过回放机制来保证增量数据的完整性。Milvus 集群使用 Pulsar 作为日志代理,独立模式使用 RocksDB。Kafka、Pravega 等流存储服务也可以用作日志代理。
- 对象存储: 存储日志的快照文件、标量/向量索引文件以及中间查询处理结果。Milvus 支持 AWS S3 和 Azure Blob,以及轻量级开源对象存储服务 MinIO。
数据模型
在 Milvus 中,所有数据都是按照集合(collection)、分片(shard)、分区(partition)、段(segment)和实体(entity)来组织的。

集合(collection)
Milvus 中的集合可以比作关系存储系统中的表。集合是 Milvus 中最大的数据单元。
分片(shard)
为了在写入数据时充分利用集群的并行计算能力,Milvus 中的集合必须将数据写入操作分散到不同的节点。默认情况下,单个集合包含两个分片。根据您的数据集量,您可以在集合中拥有更多分片。Milvus 默认使用哈希方法进行分片。
分区(partition)
一个分片中也有多个分区。Milvus 中的分区是指集合中标记有相同标签的一组数据。常见的分区方式包括按日期、性别、用户年龄等分区。创建分区可以有利于查询过程,因为可以通过分区标签过滤大量数据。
相比之下,分片更多的是在写入数据时的扩展能力,而分区更多的是在读取数据时增强系统性能。
段(segment)

每个分区内都有多个小段。段是 Milvus 中系统调度的最小单位。有两种类型的段:增长段(GrowingSegment)和密封段(SealedSegment)。增长段由查询节点订阅,Milvus 用户不断将数据写入增长段中。当增长段的大小达到上限(默认为512 MB)时,系统将不允许向该增长段写入额外的数据,从而密封该段。索引建立在密封段上。
为了实时访问数据,系统会读取增长段和密封段中的数据。
实体
每个段都包含大量的实体。Milvus 中的实体相当于传统数据库中的一行。每个实体都有一个唯一的主键字段,该字段也可以自动生成。实体还必须包含时间戳(ts)和向量场——这是 Milvus 的核心。
Milvus 架构中的 Knowhere
狭义上,Knowhere 是一个操作接口,用于访问系统上层的服务和系统下层的 Faiss、Hnswlib、Annoy 等向量相似搜索库。此外,Knowhere 还负责异构计算。更具体地说,Knowhere 控制在哪个硬件(例如 CPU 或 GPU)上执行索引构建和搜索请求。这就是 Knowhere 名字的由来——知道在哪里执行操作。未来版本将支持更多类型的硬件,包括 DPU 和 TPU。
广义上,Knowhere 还整合了其他第三方索引库,例如 Faiss。因此,从整体上看,Knowhere 被公认为 Milvus 向量数据库中的核心向量计算引擎。
从 Milvus 2.0.1 开始,Knowhere 已独立于 Milvus 项目。

Knowhere 优点
Knowhere 不仅进一步扩展了 Faiss 的功能,还优化了性能。更具体地说,Knowwhere具有以下优点。
支持 BitsetView
最初,Milvus 中引入 bitset 的目的是为了软删除。软删除的向量仍然存在于数据库中,但在向量相似性搜索或查询期间不会被计算。位集中的每个位对应于一个索引向量。如果一个向量在位集中被标记为 1,则意味着该向量被软删除,并且在向量搜索期间不会涉及该向量。目前,Bitset 参数被添加到 Knowhere 中所有公开的 Faiss 索引查询 API 中,包括 CPU 和 GPU 索引。
支持更多相似度指标来索引二进制向量
除了 Hamming 之外,Knowhere还支持 Jaccard、Tanimoto、Superstruct、Substruct。Jaccard 和Tanimoto 可用于衡量两个样本集之间的相似性,而 Superstruct 和 Substruct 可用于衡量化学结构的相似性。
支持 AVX512 指令集
Faiss本身支持多种指令集包括 AArch64、SSE4.2、AVX2。Knowhere 通过添加 AVX512 进一步扩展了支持的指令集,与 AVX2 相比,可以将索引构建和查询的性能提高 20% 至 30% 。文章来源:https://www.toymoban.com/news/detail-529448.html
自动 SIMD 指令选择
Knowhere 旨在在具有不同 SIMD 指令(例如 SIMD SSE、AVX、AVX2 和 AVX512)的各种 CPU 处理器(本地和云平台)上良好运行。因此,挑战在于,给定一个软件二进制文件(即 Milvus),如何使其在任何 CPU 处理器上自动调用合适的 SIMD 指令。Faiss 不支持自动 SIMD 指令选择,用户需要在编译期间手动指定SIMD 标志(例如 -msse4)。然而,Knowhere 是通过重构 Faiss 的代码库构建的。依赖 SIMD 加速的常见功能(例如相似性计算)被排除在外。然后,对于每个功能,实现四个版本(即SSE、AVX、AVX2、AVX512),并将每个版本放入单独的源文件中。然后使用相应的 SIMD 标志进一步单独编译源文件。因此,在运行时,Knowhere 可以根据当前 CPU 标志自动选择最适合的 SIMD 指令,然后使用挂钩链接正确的函数指针。文章来源地址https://www.toymoban.com/news/detail-529448.html
到了这里,关于Milvus 介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!