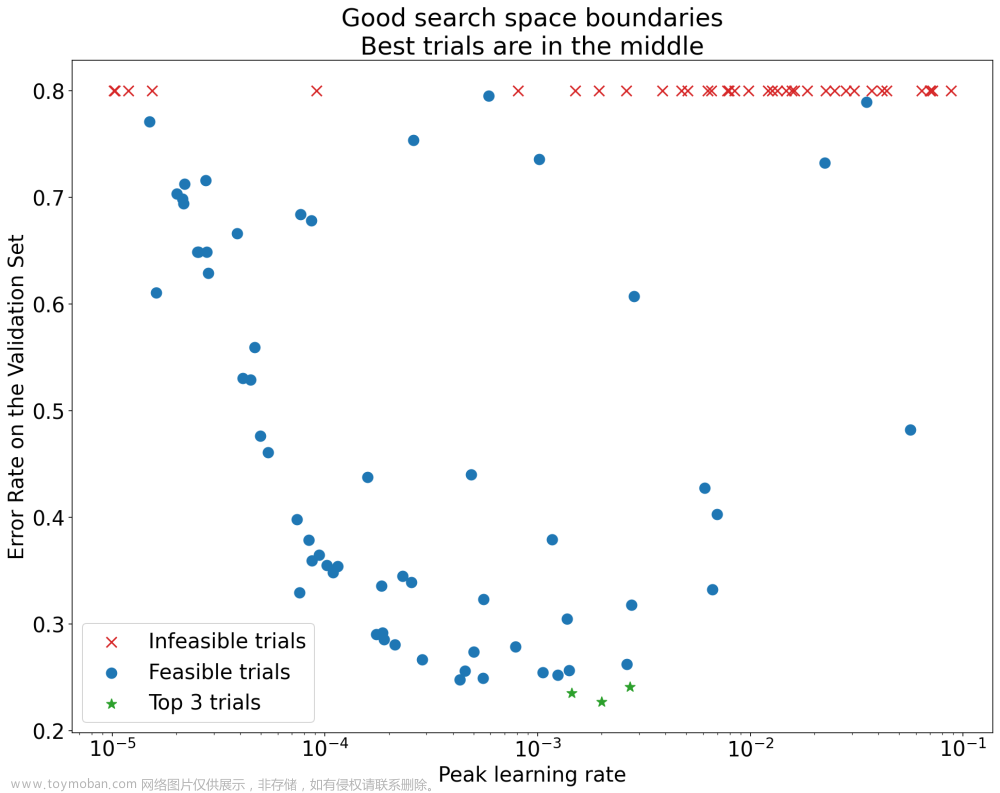
deep learning训练过程
如果对所有层同时训练,时间复杂度会太高;如果每次训练一层,偏差就会逐层传递。这会面临跟上面监督学习中相反的问题,会严重欠拟合(因为深度网络的神经元和参数太多了)。
2006年,hinton提出了在非监督数据上建立多层神经网络的一个有效方法,简单的说,分为两步,一是每次训练一层网络,二是调优,使原始表示x向上生成的高级表示r和该高级表示r向下生成的x’尽可能一致。方法是:
1、首先逐层构建单层神经元,这样每次都是训练一个单层网络。
2、当所有层训练完后,Hinton使用wake-sleep算法进行调优。
将除最顶层的其它层间的权重变为双向的,这样最顶层仍然是一个单层神经网络,而其它层则变为了图模型。向上的权重用于“认知”,向下的权重用于“生成”。然后使用Wake-Sleep算法调整所有的权重。让认知和生成达成一致,也就是保证生成的最顶层表示能够尽可能正确的复原底层的结点。比如顶层的一个结点表示人脸,那么所有人脸的图像应该激活这个结点,并且这个结果向下生成的图像应该能够表现为一个大概的人脸图像。Wake-Sleep算法分为醒(wake)和睡(sleep)两个部分。
1)wake阶段:认知过程,通过外界的特征和向上的权重(认知权重)产生每一层的抽象表示(结点状态),并且使用梯度下降修改层间的下行权重(生成权重)。也就是“如果现实跟我想象的不一样,改变我的权重使得我想象的东西就是这样的”。
2)sleep阶段:生成过程,通过顶层表示(醒时学得的概念)和向下权重,生成底层的状态,同时修改层间向上的权重。也就是“如果梦中的景象不是我脑中的相应概念,改变我的认知权重使得这种景象在我看来就是这个概念”。
deep learning训练过程具体如下:
1、使用自下上升非监督学习(就是从底层开始,一层一层的往顶层训练):
采用无标定数据(有标定数据也可)分层训练各层参数,这一步可以看作是一个无监督训练过程,是和传统神经网络区别最大的部分(这个过程可以看作是feature learning过程):
具体的,先用无标定数据训练第一层,训练时先学习第一层的参数(这一层可以看作是得到一个使得输出和输入差别最小的三层神经网络的隐层),由于模型capacity的限制以及稀疏性约束,使得得到的模型能够学习到数据本身的结构,从而得到比输入更具有表示能力的特征;在学习得到第n-1层后,将n-1层的输出作为第n层的输入,训练第n层,由此分别得到各层的参数。
2、自顶向下的监督学习(就是通过带标签的数据去训练,误差自顶向下传输,对网络进行微调):
基于第一步得到的各层参数进一步fine-tune整个多层模型的参数,这一步是一个有监督训练过程;第一步类似神经网络的随机初始化初值过程,由于DL的第一步不是随机初始化,而是通过学习输入数据的结构得到的,因而这个初值更接近全局最优,从而能够取得更好的效果;所以deep learning效果好很大程度上归功于第一步的feature learning过程。
Deep learning总结
深度学习是关于自动学习要建模的数据的潜在(隐含)分布的多层(复杂)表达的算法。换句话来说,深度学习算法自动的提取分类需要的低层次或者高层次特征。
高层次特征,一是指该特征可以分级(层次)地依赖其他特征,例如:对于机器视觉,深度学习算法从原始图像去学习得到它的一个低层次表达,例如边缘检测器,小波滤波器等,然后在这些低层次表达的基础上再建立表达,例如这些低层次表达的线性或者非线性组合,然后重复这个过程,最后得到一个高层次的表达。
Deep learning能够得到更好地表示数据的feature,同时由于模型的层次、参数很多,capacity足够,因此,模型有能力表示大规模数据,所以对于图像、语音这种特征不明显(需要手工设计且很多没有直观物理含义)的问题,能够在大规模训练数据上取得更好的效果。
此外,从模式识别特征和分类器的角度,deep learning框架将feature和分类器结合到一个框架中,用数据去学习feature,在使用中减少了手工设计feature的巨大工作量(这是目前工业界工程师付出努力最多的方面),因此,不仅仅效果可以更好,而且,使用起来也有很多方便之处,因此,是十分值得关注的一套框架,每个做ML的人都应该关注了解一下。
当然,deep learning本身也不是完美的,也不是解决世间任何ML问题的利器,不应该被放大到一个无所不能的程度。
Deep learning未来
深度学习目前仍有大量工作需要研究。目前的关注点还是从机器学习的领域借鉴一些可以在深度学习使用的方法特别是降维领域。例如:目前一个工作就是稀疏编码,通过压缩感知理论对高维数据进行降维,使得非常少的元素的向量就可以精确的代表原来的高维信号。
另一个例子就是半监督流行学习,通过测量训练样本的相似性,将高维数据的这种相似性投影到低维空间。另外一个比较鼓舞人心的方向就是evolutionary programming approaches(遗传编程方法),它可以通过最小化工程能量去进行概念性自适应学习和改变核心架构。
Deep learning还有很多核心的问题需要解决:
(1)对于一个特定的框架,对于多少维的输入它可以表现得较优(如果是图像,可能是上百万维)?
(2)对捕捉短时或者长时间的时间依赖,哪种架构才是有效的?
(3)如何对于一个给定的深度学习架构,融合多种感知的信息?
(4)有什么正确的机理可以去增强一个给定的深度学习架构,以改进其鲁棒性和对扭曲和数据丢失的不变性?
(5)模型方面是否有其他更为有效且有理论依据的深度模型学习算法?
探索新的特征提取模型是值得深入研究的内容。此外有效的可并行训练算法也是值得研究的一个方向。当前基于最小批处理的随机梯度优化算法很难在多计算机中进行并行训练。文章来源:https://www.toymoban.com/news/detail-529712.html
通常办法是利用图形处理单元加速学习过程。然而单个机器GPU对大规模数据识别或相似任务数据集并不适用。在深度学习应用拓展方面,如何合理充分利用深度学习在增强传统学习算法的性能仍是目前各领域的研究重点。文章来源地址https://www.toymoban.com/news/detail-529712.html
到了这里,关于Deep Learning-学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!