(20230410-20230416)论文阅读简单记录和汇总
2023/04/09:很久没有动笔写东西了,这两周就要被抓着汇报了,痛苦啊呜呜呜呜呜
目录
- (CVPR 2023): Temporal Interpolation Is All You Need for Dynamic Neural Radiance Fields
- (ICCV 2021):Video Autoencoder: self-supervised disentanglement of static 3D structure and motion
- (CVPR 2023):DINER: Disorder-Invariant Implicit Neural Representation
- (CVPR 2023):Regularize implicit neural representation by itself
- (DCC 2023):RQAT-INR: Improved Implicit Neural Image Compression
- (arxiv 2023):DNeRV: Modeling Inherent Dynamics via Difference Neural Representation for Videos
1. (CVPR 2023)Temporal Interpolation Is All You Need for Dynamic Neural Radiance Fields
Paper: https://arxiv.org/pdf/2302.09311.pdf
1.1 摘要
在动态场景中,时间插值在学习有意义的表示中起着至关重要的作用。本文提出了一种基于特征向量时间插值的动态场景四维时空神经辐射场训练方法。两种特征插值方法的建议取决于底层表示,神经或网格表示。在神经表示中,我们通过多个神经网络模块从时空输入中提取特征,并根据时间框架进行插值。所提出的多层特征插值网络有效地捕获了短期和长期时间段的特征。在网格表示中,时空特征是通过四维哈希网格学习的。网格表示显著减少了训练时间,与神经网络模型相比,速度快100多倍,同时保持训练模型的渲染质量。静态和动态特征的拼接以及简单平滑项的加入进一步提高了模型的性能。尽管其网络结构简单,但我们证明了所提出的方法在神经表示方面表现出优于以往工作的性能,并且在网格表示方面表现出最快的训练速度。
1.2 方法
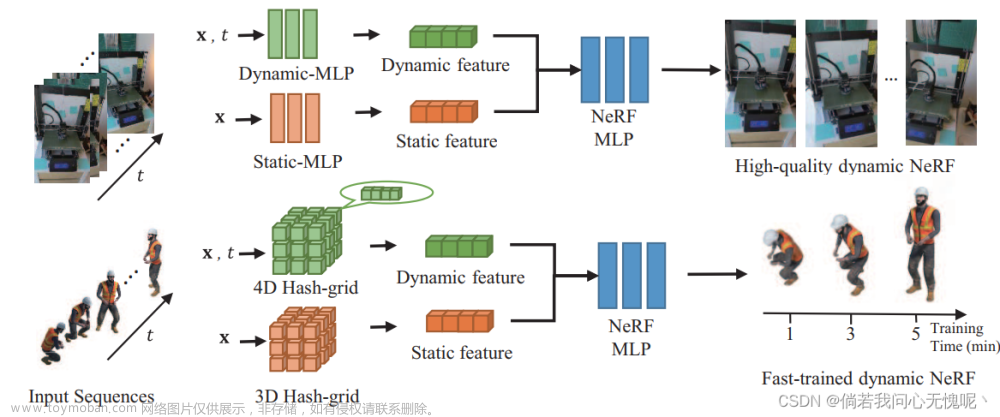
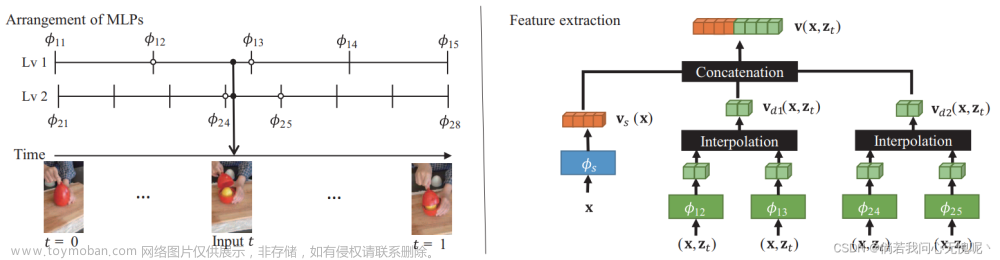
所提出方法的框架图还是挺简单的,我没有去看平滑项的部分,关于静态和动态特征的描述是场景中既包含了几乎不变的静态背景和随时间发生变化的物体形变、位移和闪出,仅采用随着
x
x
x和
t
t
t变化的嵌入编码作为输入特征向量是不够的。因此NeRF MLP的输入向量由静态特征和动态特征两部分组成,使用concat拼接起来。不同层次之间的动态特征由不同层次相邻的tiny MLP处理得到,最后也通过concat拼接得到。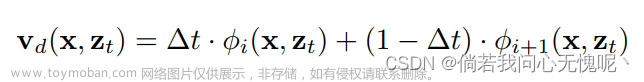
上方的示意图已经很好滴说明了动态特征是如何得到的了,可惜就是没有开源,对于网络的一些细节并不了解。
1.3 限制
虽然本文提出的特征插补方法能够学习到有意义的时空特征,但也存在图8所示特征插补失败的情况。使用神经表示,当视频序列中的小物体快速移动时,很难恢复3D结构(图8左)。(那这里其实有点像NeRV中采用MLP从位置编码学习时空信息一样,插值效果还是很拉跨,这是否说明位置编码或神经表示是存在问题的?) 使用诸如光流之类的附加信息有助于估计在物理上有意义的3D空间中的对应关系,这将是有益的。与此同时,我们的特征插值框架由于估计在训练序列中不可见的动态区域而受到影响(图8右)。平滑项基本上假设不可见区域保持静态,在这种情况下可能会降低性能。
1.4 结论
在本文中,我们提出了一种简单而有效的特征插值方法来训练动态nerf。神经表示和网格表示都表现出了令人印象深刻的性能。由于这些方法与现有的变形建模或估计场景流的方法无关,我们认为所提出的方法为训练动态nerf提供了一个新的方向。平滑项应用于中间特征向量进一步提高了性能。
虽然由于神经网络的表示能力,神经表示模型显示了高质量的渲染结果,但它需要数小时的训练和数秒的渲染,这对实时应用造成了障碍。另一方面,网格表示在经过几分钟的训练后,能够在不到一秒钟的时间内渲染动态场景,这使得它在现实应用中更加实用。两种表示法是相互补充的,研究利用两种表示法的混合表示法将是一个有趣的研究方向。
2. (ICCV 2021)Video Autoencoder: self-supervised disentanglement of static 3D structure and motion
Project Page:https://zlai0.github.io/VideoAutoencoder/
Paper:https://arxiv.org/abs/2110.02951
Code:https://github.com/zlai0/VideoAutoencoder/
2.1 摘要
提出了一种视频自编码器,用于自监督地从视频中学习三维结构和摄像机姿态的解纠缠表示。基于视频中的时间连续性,我们的工作假设附近视频帧中的3D场景结构保持静态。给定一个视频帧序列作为输入,视频自动编码器提取场景的解纠缠表示,包括:(i)一个时间一致的深体素特征来表示3D结构;(ii)每个帧的相机姿态的3D轨迹。然后,这两种表示将重新纠缠以呈现输入视频帧。该视频自动编码器可以直接使用像素重建损失进行训练,无需任何地面真相3D或相机姿态注释。该解纠缠表示可以应用于一系列任务,包括新视图合成、摄像机姿态估计和通过运动跟踪生成视频。我们在几个大规模的自然视频数据集上评估了我们的方法,并在域外图像上显示了泛化结果。
2.2 方法
看了下对我没啥用,就不继续看了,以下是网络结构图。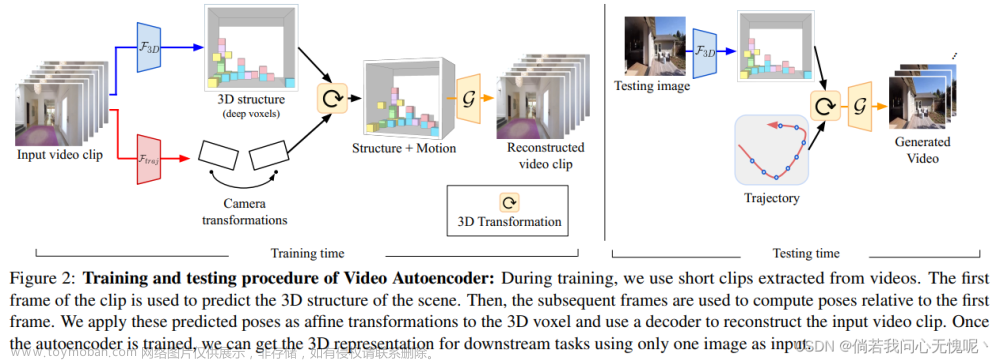
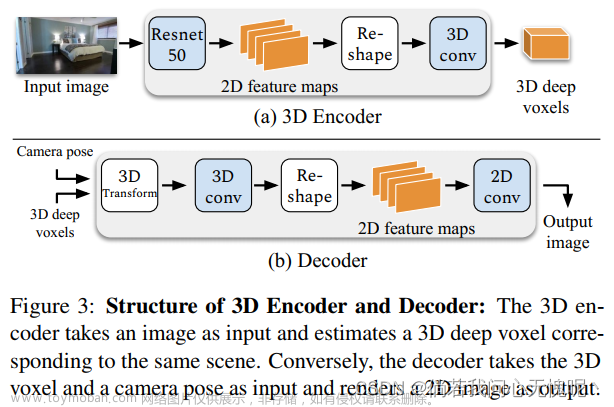
2.3 结论
我们提出了视频自动编码器,将视频编码为3D结构和相机姿态的解纠缠表示。该模型只使用原始视频进行训练,没有使用任何明确的3D监督或相机姿势。我们表明,我们的表示可以实现诸如摄像机姿态估计、新视图合成和通过运动跟踪生成视频等任务。我们的模型在所有任务上都表现出卓越的泛化能力,并在自监督相机姿态估计方面取得了最先进的结果。与训练中使用地面真实摄像机的方法相比,我们的模型在新视图合成方面也取得了相同的结果。
3. (CVPR 2023)DINER: Disorder-Invariant Implicit Neural Representation
Project Page:https://ezio77.github.io/DINER-website/
Paper:https://arxiv.org/pdf/2211.07871.pdf
Code:https://github.com/Ezio77/DINER
CVPR 2023版本之后还有一个arxiv的16页扩展版《Disorder-invariant Implicit Neural Representation》,有兴趣的可以自己去找一下。
3.1 摘要
隐式神经表示(INR)将信号的属性表征为对应坐标的函数,成为求解逆问题的利器。然而,网络训练中的光谱偏置限制了INR的能力。在本文中,我们发现这样一个与频率相关的问题可以通过重新排列输入信号的坐标来很大程度上解决,为此我们提出了通过在传统的INR主干上增加哈希表来实现无序不变隐式神经表示(DINER)。给定具有相同属性直方图且排列顺序不同的离散信号,哈希表可以将坐标投影到相同的分布中,后续的INR网络可以更好地对映射信号进行建模,从而显著缓解频谱偏差。实验不仅揭示了DINER对于不同INR主干(MLP vs. SIREN)和各种任务(图像/视频表示、相位检索和折射率恢复)的泛化性,而且还显示了其在质量和速度上优于最先进的算法。
3.2 方法
作者首先提出现有方法的两个问题:
- 现有INR方法的性能受到信号自频分布的限制,通常需要更深或更宽的网络架构来提高拟合精度。
- 尽管参数编码具有收敛速度快、精度高的优势,但仍有一个关键问题没有得到解答,即这些特征的几何意义是什么?
同时作者分析了二维输入图像的频率分量对于INR拟合效果的影响,作者不改变图像的色彩直方图,将图像中的像素按顺序进行排列或者重新排列得到两幅图像进行INR拟合。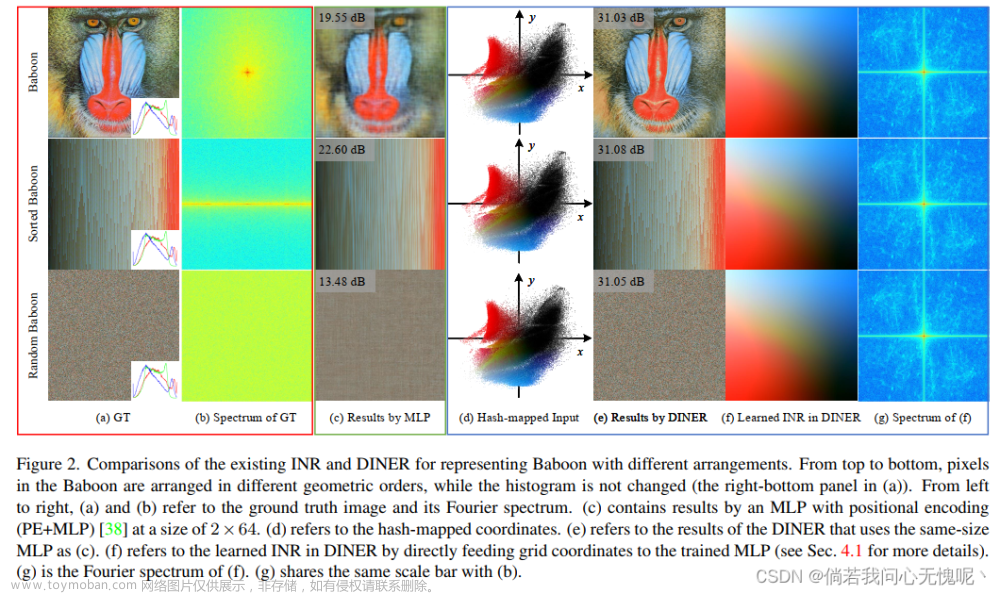
那么这里可以看出,针对不同调整过后的图像拟合效果是完全不同的,对于最后的随机像素排列图像,图像中存在大量高频信息导致INR拟合效果是非常差的。但是这也启发了作者另一个想法,INR的输入是坐标输出是像素值,采用不同顺序或者映射的输入输出对网络来说是没有变化的。
这句话可能有点拗口,我的意思是有正常图像中坐标 x 1 x_1 x1输入得到输出 y 1 y_1 y1,和输入 x 2 x_2 x2得到输出 y 2 y_2 y2;那么通过位置变换输入 x 3 x_3 x3时得到 y 1 y_1 y1,输入 x 4 x_4 x4时得到 y 2 y_2 y2,这完全是没有去别的。我只需要知道 x 3 x_3 x3输入得到的输出值对应的是 x 1 x_1 x1位置的像素即可,既如果每个像素点和网络输入之间的映射即可。但是输入坐标的不同对于INR拟合的效果是千差万别的,那么想当然可以有一个想法,我们把输入坐标映射(输入坐标映射到了d部分)成另一个呈现为比较平滑、低频分量较多的图像(上图中的f部分,其实就是INR学习了f这个图,映射坐标重新映射回去进行排列就会变成a部分的图)上去,就能够使INR拟合能力大大增强,并且这个映射关系是可以根据输入图像的性质进行学习的
作者总结本文的贡献为:
- 所提出DINER方法极大地提高了现有INR方法的精度,其中利用学习过的哈希表映射原始输入的坐标,以便在后续INR模型中更好地表征。
- 所提出的DINER为具有相同属性直方图和不同排列顺序的信号提供了一致的映射和表示能力。
- 所提出的DINER被推广到各种任务中,包括二维图像和三维视频的表示,无透镜成像中的相位检索,以及强度衍射层析成像中的3D折射率恢复,报告了现有最先进技术的显著性能增益
并提出了两个命题:
- 信号的不同排列有不同的频率分布,导致INR表示信号自身的能力不同。
- DINER是无序不变的,具有相同属性直方图分布的信号共享具有相同参数值的优化网络。(这一点也很有意思,那么对于相同直方图的图像可以仅采用一个INR进行压缩,只需要改变他的哈希表即可)


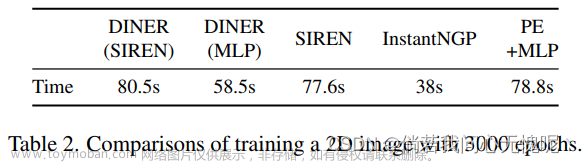
该表格也验证了现有方法在拟合图像时会趋向于拟合图像的低频部分,而对高频部分的拟合训练缓慢,这也是INR论文中常提的网络偏置或叫光谱偏差。实验中各个部分都充分证明了所提出方法的有效性,实验表现简而言之就是牛逼Plus, 45dB真是牛逼啊。
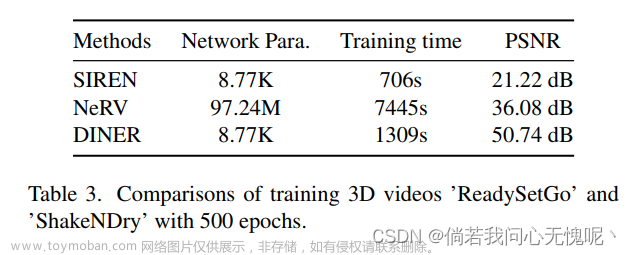

DINER仅采用8.77k的参数量实现了一个300帧 1080P视频的表征,这要是放在压缩任务真是吓死个人了,但是其实这用在压缩上应该是不切实际的,哈希表就会非常非常大。
此外,将原始输入通过哈希表映射,然后再输入网络得到颜色通道的值,大家看看本节最上图中的f部分,这个图像什么,像不像PS或者Visio里面的取色版(手动狗头Dog)。那么其实上面我的说法也错了,甚至不需要相同直方图,只需要一个足够大的SIREN或者MLP能够映射8位色彩中的所有颜色,即
25
6
3
=
(
2
8
)
3
=
2
24
256^3=(2^8)^3=2^{24}
2563=(28)3=224,那么只需要更换哈希表就可以表示所有的图像了。
我们有理由相信,DINER中INR部分其实是学习了一个色彩上的集合,没有任何实际意义,真正能体现图像的部分在哈希表中的坐标映射。我目前还没有看这个代码,不知道这个哈希表存储下来得有多大,不过在实验中对[1200,1200]大小图像采用了 2 21 2^{21} 221长度的哈希表,不可能太小- -。
3.3 讨论
前面提到的实验都集中在离散信号上。为了查询连续信号中不可见的坐标,建议对网络输出进行后插补操作,而不是向网络输入插值哈希键(如图11所示),例如Plenoxels的探索,它将密度和谐波系数的网格[8]插入,而不是直接向网络输入不可见的位置和方向坐标[22]。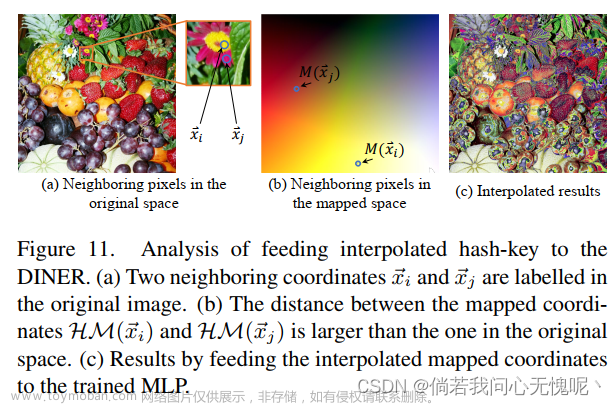
太对味了,太对味了!!从我们上面的粗体字分析很容易得出DINER完全不具备INR的插值能力!! ,因为他根本算不上一个INR!!MLP中除了拟合图像中的颜色信息,不包含任何关于图像的结构、纹理等信息!!MLP只是学了个调色盘!!他在插值方面注定是失败的!!

那么现在抛出另一个问题,实验中其实可以看出MLP结构和SIREN结构所学习到的调色盘是存在一定差别的,这种情况是什么呢?我的猜测是MLP和SIREN结构的网络偏差是不同的,SIREN由于采用了Sin激活函数,所以带有一定频率的网络偏置,会学习最适合这个频率的信息,那么在调色板上也会显示一定的变化出来。 有其他见解的朋友可以将你们的看法发在评论区
3.5 结论
在这项工作中,我们提出了DINER,通过引入额外的哈希表,可以大大提高当前INR骨干的准确性。我们指出了INR表示信号的性能是由信号中元素的排列顺序决定的。该方法可以将输入的离散信号映射成一个低频信号,在不改变属性直方图的情况下,仅改变排列顺序,低频信号是不变的。因此,不同INR骨干网的精度可以大大提高。 <—(结合这两句话去看这个文章所提出的方法会非常简单)大量的实验验证了所提出的DINER在信号拟合和反问题优化任务中具有较高的精度和效率。
然而,目前的DINER只能处理离散信号。在未来,我们将专注于连续映射方法,而不是基于离散哈希表的映射,以扩展连续信号的优势,例如有符号距离函数[26]。
4. (CVPR 2023) Regularize implicit neural representation by itself
Paper:https://arxiv.org/abs/2303.15484
简而言之就是一大堆公式懒得花时间看,对于提升INR表征能力应该是近乎于没有,作者采用迪利克雷能量和拉普拉斯矩阵平滑性复原图像,取得了优于原始INR的性能。(在我看来是利用MLP计算传统方法中的一些矩阵、能量等公式并使其最小化,和传统图像增强方法采用什么能量计算、局部方差对比度优化差不多?)
实验中采用的基本都是采样不均匀或者人为添加噪声的图像进行拟合实验,并不认为该方法真的增强了INR的泛化性,而是INR+传统套皮得到一个针对不均匀采样图像的增强表示,真有这么垃圾的图像我直接一波图像复原、图像补全再INR拟合不好吗。
当然最有可能的结论是我没看完所以在这瞎扯hhhhh,感兴趣的朋友可以看看这篇论文然后在评论区讨论233333
4.1 摘要
本文提出了一种隐式神经表示正则化器(INRR)提高隐式神经表示(INR)的泛化能力。INR是一个完全连接的网络,可以表示不受网格分辨率限制的细节信号。但是,它的泛化能力还有待提高,特别是对于非均匀采样数据。提出的INRR基于可学习的狄利克雷能量(DE),测量矩阵的行/列之间的相似性。通过使用一个极小的INR参数化DE可以进一步整合拉普拉斯矩阵的平滑性。INRR通过将信号的自相似性与拉普拉斯矩阵的平滑性完美地结合起来,实现了INR信号表示能力的泛化性提升。通过精心设计的数值实验,本文还揭示了INRR的一系列性质,包括收敛轨迹和多尺度相似等动量方法。此外,该方法可以提高其他信号表示方法的性能。
4.2 方法和贡献
作者总结滴贡献:
- 神经切核(NTK)[1]从理论上分析了INR的泛化能力,并给出了INR在非均匀采样情况下性能较差的原因。
- 在DE的基础上,提出了一种微小的INR参数化正则子INRR,该正则子将图像的自相似性和拉普拉斯矩阵的平滑性完美地结合在一起。
- 通过精心设计的数值实验,揭示了INRR的动量方法、多尺度相似性和泛化能力等一系列性质
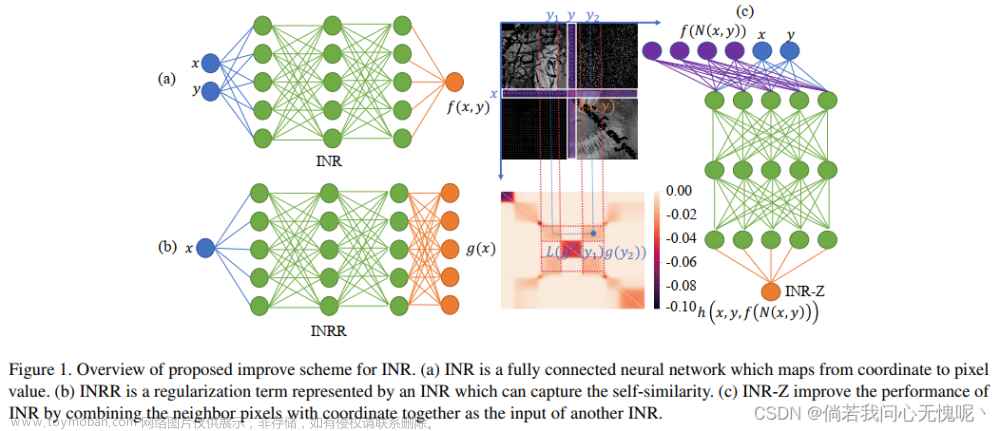

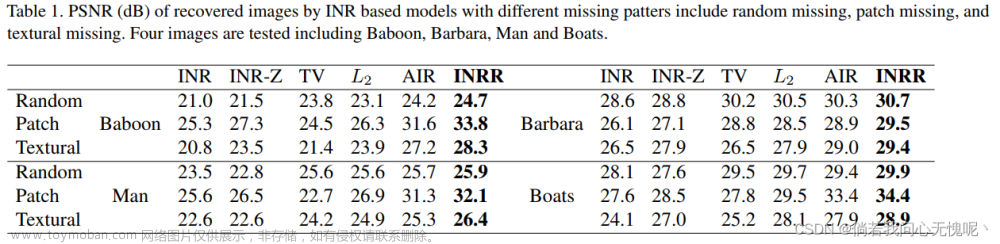
4.3 结论
本文提出了一种新的正则化子INRR,该正则化子显著提高了INR的表示性能,特别是在任意采样训练数据的情况下。INRR将DE中的拉普拉斯矩阵参数化了一个极小的INR,然后自适应地学习隐藏在图像数据中的非局部相似性。INRR是一个通用框架,用于将多个先验函数集成到一个正则化函数中,从而减少正则化函数的冗余。INRR、动量项、内隐偏差和多尺度自相似度之间的联系值得进一步的理论分析。
5. (DCC 2023):RQAT-INR: Improved Implicit Neural Image Compression
Paper:https://arxiv.org/abs/2303.03028
5.1 摘要
近年来,用于图像和视频压缩的深度变分自编码器获得了巨大的吸引力,因为与数十年之久的传统编解码器(如AVC、HEVC或VVC)相比,它们有潜力提供具有竞争力或更好的压缩率。但由于其复杂性和能耗,这些方法离工业实际应用还有很长的路要走。近年来,基于隐式神经表示(INR)的编解码器已经出现,与传统的解码方法相比,它具有更低的复杂度和能量消耗。但是,他们的表现与目前最先进的方法还不能相提并论。在这项研究中,我们首先证明了基于INR的图像编解码器比基于VAE的方法具有更低的复杂度,然后我们提出了基于INR的图像编解码器的几个改进,并在很大程度上优于基线模型。
5.2 方法
RQAT-INR里面提出了三个方法:绝对最大值归一化量化、边界感知熵模型和正则化量化感知训练。看了下感觉前两个都是比较简单的方法呀,最后一项加了个正则项略微有点意思。这里就给个正则化的损失(这个正则化量化感知训练类似于知识蒸馏操作),其他的有兴趣就自己去看原文了。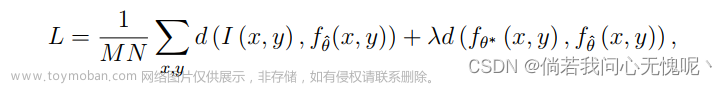
编码后的比特流情况和解码操作如下图所示
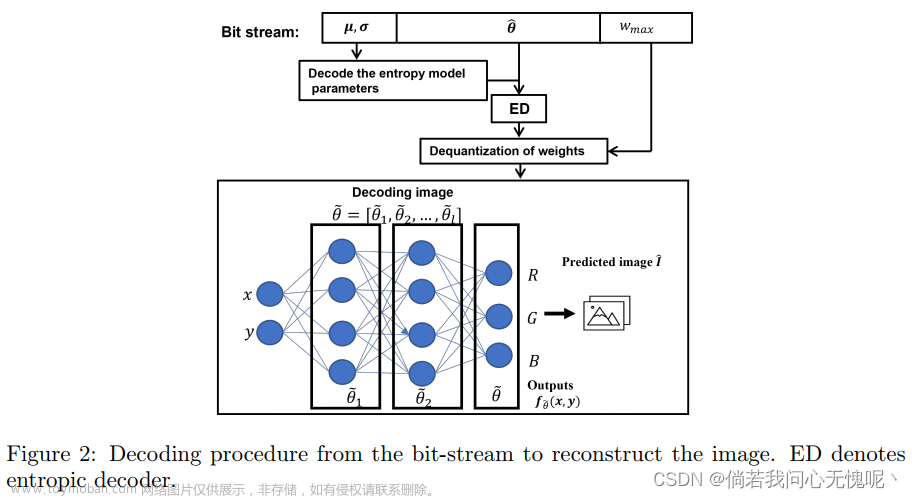
实验效果方面相比于COIN和COIN++是有较明显的提升,作者主要还展示了与VAE模型之间的复杂度比较,INR的方法与VAE方法之间的Flops差别差不多在1-2个数量级。
5.3 结论
在本文中,我们证明了基于INR的压缩方法比基于VAE的压缩方法具有更低的解码复杂度。此外,我们提出了正则化量化感知训练和边界感知熵模型,以提高基于隐式神经表示的图像压缩的压缩率。与现有方法相比,我们的方法带来了32-41%的比特率增益。然而,这种改进目前还不足以与最先进的模型竞争,特别是在高码率标准下。从图4b可以看出,INR的PSNR损失是按码率增加的。这可以解释为选择的MLP体系结构并不是熵约束下图像逼近的最优体系结构。在较低的速率下,由于参数的数量较低,网络的可能架构也受到限制。因此,所选择的MLP可能与最优体系结构相差不远。然而,在高码率条件下,INR网络的可能结构随着网络参数数量的增加而呈指数增长。因此,寻找最好的通用架构和/或图像自适应架构将是摆脱这个问题的某种方式,我们建议在未来的工作中解决这个问题。 此外,我们的量化是为了将权重编码到比特流中,而不是降低模型的复杂性。我们的解码器仍然对去量化参数执行单精度浮点运算。为了进一步降低解码网络的复杂度,将INR解码网络用整数网络实现是我们今后的工作方向。
6. (arxiv 2023)HyperINR: A Fast and Predictive Hypernetwork for Implicit Neural Representations via Knowledge Distillation
Paper: https://arxiv.org/abs/2304.04188
简而言之,第一段看完就不想看了,当然意思不是说他不好,只是我看不懂。
6.1 摘要
内隐神经表征(INRs)最近在科学可视化领域表现出巨大的潜力,用于数据生成和可视化任务。然而,这些表示通常由大型多层感知器(mlp)组成,一次向前传递需要数百万次操作,因此阻碍了交互式视觉探索。虽然减少mlp的大小和采用有效的参数编码方案可以缓解这个问题,但它损害了不可见参数的泛化性,使其不适用于时间超分辨率等任务。在本文中,我们介绍了HyperINR,一种新型的超网络结构,能够直接预测紧凑型INR的权重。通过统一利用多分辨率哈希编码单元的集成,所得到的INR获得了最先进的推理性能(高达100倍更高的推理带宽),并支持交互式照片现实体可视化。此外,通过结合知识蒸馏,实现了出色的数据和可视化生成质量,使我们的方法对实时参数探索有价值。我们通过一项全面的消融研究验证了HyperINR架构的有效性。我们展示了HyperINR在三个不同可视化任务中的多功能性:新颖的视图合成、体数据的时间超分辨率和动态全局阴影的体绘制。HyperINR同时实现了效率和通用性,为INR在更广泛的科学可视化应用中应用铺平了道路。
- 我们设计了HyperINR:一种超级网络,可以有效地为给定参数生成常规INR的权重,实现最先进的推理性能,并实现高质量的交互式体积路径跟踪。
- 我们介绍了一个通过知识蒸馏优化HyperINR的框架,为不可见参数获得最先进的数据泛化质量,并支持实时参数探索。
- 我们展示了HyperINR出色的推理性能,以及在各种科学可视化任务中生成有意义的数据和可视化的能力。
6.2 结论
我们介绍了HyperINR,这是一种创新的超网络,可以为不可见的场景参数条件生成inr。通过使用大量小型多分辨率哈希编码器、共享MLP和深度嵌入的权重插值操作,HyperINR实现了令人印象深刻的100倍更高的推理带宽和交互式体渲染,具有出色的真实感。此外,通过知识蒸馏我们的方法获得了最先进的数据和可视化生成表现。我们的结果强调了HyperINR在各种可视化任务中的潜力,展示了其有效性和效率。我们相信HyperINR代表了科学可视化及其他领域内基于隐式神经表示的方法的发展向前迈出了一步。
7. (arxiv 2023)DNeRV: Modeling Inherent Dynamics via Difference Neural Representation for Videos 基于差分神经表征的视频固有动态建模
Paper: https://arxiv.org/abs/2304.06544
看了一眼是昨天上传的文章,今天就给我逮住了hhhhhh,还是马展老师课题组的文章。
7.1 摘要
现有的隐式神经表示(INR)方法不能充分利用视频中的时空冗余。基于索引的INRs忽略了特定于内容的空间特征,而混合INRs忽略了相邻帧的上下文依赖性,导致对大运动或动态场景的建模能力较差。我们从函数拟合的角度分析了这种局限性,揭示了帧差的重要性。为了使用显式运动信息,我们提出了视频差分神经表示(DNeRV),它由内容流和帧差流组成。我们还引入了一个协作内容单元,用于有效地融合特征。我们测试DNeRV用于视频压缩、修补和插值。DNeRV在960 × 1920视频的下游修补和插值方面取得了与最先进的神经压缩方法相比具有竞争力的结果,并优于现有的隐式方法。
7.2 方法
个人认为作者(Qi Zhao)挂在arxiv的这篇文章还是一个初稿,很多地方的描述略显生涩,很多地方需要更加详细的打磨,例如Fig3和Fig4之间的不匹配,Related Work中部分描述存在错误,Motivation中的公式和推理个人认为需要继续打磨,无法构成一个完备合理的推理过程,部分公式存在格式错误和不合理的现象。Fig5中缺少高码率下的RD曲线,并且这张图应该扩大已展现所提出方法的性能优势,Fig5中两张图并列放在双栏中的左栏中实在是太小了。
由于本文并未在期刊或会议进行公开发表,并且论文中仍存在一些问题,因此不详细阐述本文方法,有兴趣的读者可以自行搜索阅读。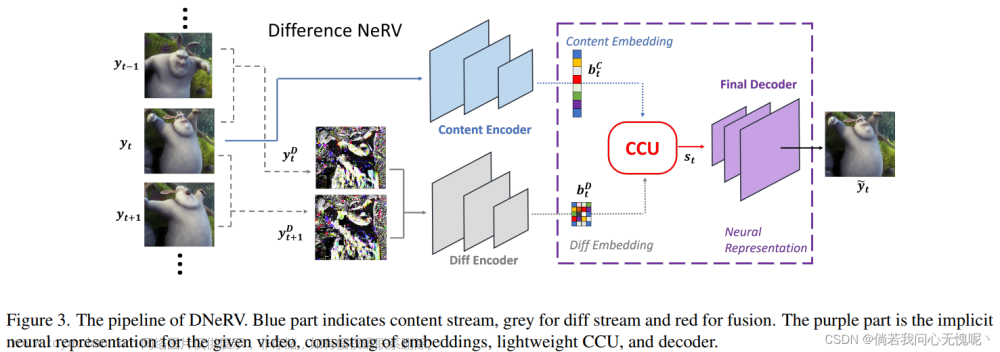
7.3 结论
在本文中,我们提出了视频差分神经表示(DNeRV)来建模上下文帧的固有动态。DNeRV基于差分流和协同内容单元,在视频回归、压缩、修补和插值等方面保持了其重构质量的优势。实验结果表明,本文提出的DNeRV算法能够较好地逼近隐式映射,实现视频的有效鲁棒表示,超越现有的NeRV方法。
7.4 未来方向
DNeRV显示了它在各种视觉任务上的潜力。基于DNeRV改进的任务特定方法有望挑战最先进的方法。此外,基于inr的网络 g θ g_\theta gθ通过梯度下降拟合有限训练元组上的连续 f f f,还需要改进严格的理论分析。
8. (CVPR 2023)Towards Scalable Neural Representation for Diverse Videos
Project:https://boheumd.github.io/D-NeRV/
Paper和Code链接都在其中,本文是Hao Chen课题组的后续工作,第一作者是同课题组中的Bo He。文章来源:https://www.toymoban.com/news/detail-530012.html
8.1 摘要
隐式神经表征(INR)在表示3D场景和图像方面得到了越来越多的关注,最近已被应用于视频编码(例如NeRV [1],E-NeRV[2])。在取得可喜成果的同时,现有基于inr的方法仅限于编码少量具有冗余视觉内容的短视频(例如,UVG数据集中的7个5秒视频),导致模型设计单独适合单个视频帧,并且不能有效地扩展到大量不同的视频。本文的重点是为更实际的设置开发神经表示-编码具有不同视觉内容的长视频和/或大量视频。我们首先证明,与将视频划分为小子集并使用单独的模型编码相比,使用统一的模型联合编码长且不同的视频可以获得更好的压缩结果。基于这一观察,我们提出了D-NeRV,一种新的神经表示框架,旨在通过(i)将剪辑特定的视觉内容与运动信息解耦,(ii)将时间推理引入隐式神经网络,以及(iii)使用面向任务的流作为中间输出以减少空间冗余来编码不同的视频。我们的新模型在很大程度上超越了NeRV和传统的视频压缩技术在UCF101和UVG数据集。此外,当用作有效的数据加载器时,在相同压缩比的UCF101数据集上,D-NeRV动作识别任务的准确率比NeRV高3%-10%。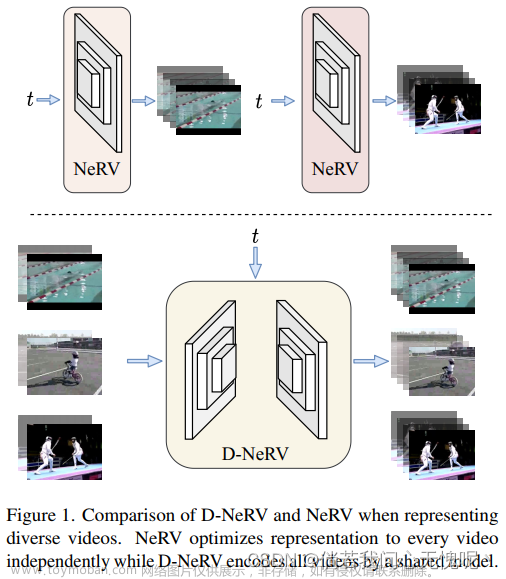 文章来源地址https://www.toymoban.com/news/detail-530012.html
文章来源地址https://www.toymoban.com/news/detail-530012.html
8.2 方法
到了这里,关于【论文阅读】(20230410-20230416)论文阅读简单记录和汇总的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!