计算机视觉面试题-Transformer相关问题总结:https://zhuanlan.zhihu.com/p/554814230
计算机视觉面试31题 CV面试考点,精准详尽解析:https://zhuanlan.zhihu.com/p/257883797
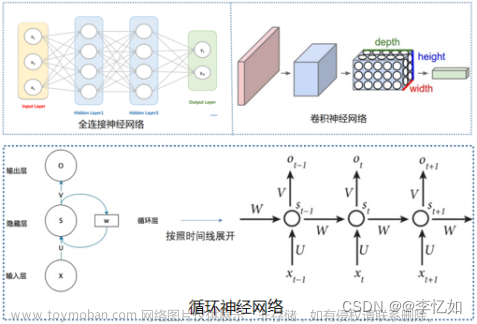
1. 循环神经网络(Recurrent Neural Networks, RNN)
RNN的出现是为了解决输入输出没有严格对应关系的问题,该模型的输入和输出长度不需固定。
RNN的框架结构如下,X0, X1, … , Xt是长度相同的输入词向量,A是参数矩阵,h0, h1, … , ht是长度相同的隐藏状态向量。最后一个隐藏状态向量ht就是RNN的最终输出

RNN和人的阅读方式类似,每次读取一个单字或单词向量Xt,然后用状态向量ht存储单词信息,并且该存储是累积式的。比如状态向量h0包含单字“祝”的信息,h1包含“祝你”两个单字的信息,而ht包含“祝你新年快”五个单字信息。模型中的参数模块A只有一个,它是机器学习的关键对象,A通常随机初始化,然后用训练数据学习A。
RNN 长记忆为什么会丢失?
RNN 用于信息传输通路只有一条,并且该通路上的计算包含多次非线性激活操作。众所周知,长记忆丢失的罪魁祸首是梯度消失,而梯度消失的主谋就是多层激活函数的嵌套,导致梯度反传时越乘越小(激活函数的导数<=1),如
0.
9
100
=
0.000026
0.9^{100}=0.000026
0.9100=0.000026 。所以后面的梯度传递不到前方,无法建立长时依赖,导致只能应对短序列,面对长序列存在记忆丢失(梯度传不过去)。

2. 长短期记忆网络(Long Short Trem Memory, LSTM)
LSTM 为了解决 RNN 的长记忆丢失问题而提出。
LSTM 如何解决该问题?
LSTM 引入了两条计算通道 ( C 和 h ) 用于信息传输,其中 C 通道上的计算相对简单,较多的是矩阵的线性转换,C 通道没有太多的非线性激活操作。梯度反传时可以在 C 通道上平稳的传输到前方,从而建立长时依赖。所以 C 通道主要用于建立长时依赖,h 通道用于建立短时依赖。
用 Ct 表示神经元在 t 时刻过后的“记忆”,这个向量涵盖了在 t+1 时刻前神经网络对于所有输入信息的“概括总结”
门 :控制信息通过与否的结构,组成:sigmoid输出01向量,0表示不允许信息通过,1表示允许信息通过。LSTM包含遗忘门、记忆门、输出门,这3个门。
遗忘门:决定从cell状态Ct-1中,丢弃哪些信息,输入Ht-1和xt,输出0-1的值。通过这种方式,LSTM可以长期记忆重要信息,并且记忆可以随着输入进行动态调整
记忆门:决定是否将在 t 时刻(现在)的数据xt存储入单元状态中Ct-1的控制单位。首先,用tanh函数层将现在的向量中的有效信息提取出来,然后使用左侧的sigmoid函数来控制这些记忆要放“多少”进入单元状态。
输出门:用于计算当前时刻的输出值的神经层。输出层会先将当前输入值与上一时刻输出值整合后的向量,用sigmoid函数提取其中的信息,接着,会将当前的单元状态Ct-1通过tanh函数压缩映射到区间(-1, 1)中,将经过tanh函数处理后的单元状态与sigmoid函数处理后的,整合后的向量点对点的乘起来就可以得到LSTM在 t 时刻的输出了!

LSTM 真的解决长记忆丢失问题了吗?
答案是否定的。在序列长度达到300+的场景中,LSTM 仍然会出现长记忆丢失问题(梯度消失)。严格来说,引入的 C(cell) 通道只是缓解了梯度消失,并没有从根本上解决该问题(注意力机制从根本上解决了该问题,后面会介绍),因为lstm仍然是一个非常深的网络,对于反向传播仍然不利,同时LSTM是不可迁移学习的。
LSTM 沿用了 RNN 的所有优势,采用顺序输入的方式将序列位置信息融入建模之中。该方式比较 make sense,因为从前往后依次进行,更符合人对序列的理解方式。但是顺序输入也严重影响了模型的并行性,后一个词的计算依赖于前一个词计算得到的结果,所以必须依次进行,导致了此类模型训练复杂度高的问题。
3. Tramsformer
Transformer 最有价值的就是其满身的自注意力机制。注意力机制更接近于人对序列的理解方式,而且可以彻底解决长记忆丢失问题。
注意力机制的思考方式?
做不同任务时赋予序列中 token 不同的权重,比如在对 “我喜欢你” 这句话做情感分类时,关注点肯定放在 “喜欢” 上,而不是泛指的人称代词。注意力机制就是在学习的过程中自适应的给予每个词对应的权重,自适应的学习应该关注的重点位置,人的思考方式亦是如此。
彻底解决长记忆丢失问题?
不同于 LSTM,Transformer 引入的自注意力机制从根本上解决了长记忆丢失问题。注意力机制会以遍历的方式计算序列中任意两个词之间的相关性,所以不管两个词相隔多远,都能捕捉到之间的依赖关系,从根本上解决难以建立长时依赖的问题。但是注意力机制的计算复杂度较大,通常为O(n^2),n 序列长度,提升模型表达能力的同时,也引入了较高的训练复杂度,所以此类模型通常都比较笨重。Transformer 摒弃了顺序输入的方式,一次性输入一个序列的所有词进行计算。这给模型带来了很好的可并行性,可批量的对多个序列进行计算。
但却丢失了对序列中词的相对位置的建模,对于语言来说,位于一维空间的序列,词的相对位置是比较重要的信息。如果不考虑词的位置信息,就会导致打乱输入序列中词的位置,不会影响到输出结果。但事实是: 我喜欢你≠你喜欢我 (舔狗的悲哀)
所以为了考虑词的位置信息,Transformer 采用函数式绝对位置编码方式,使用三角函数为每个词计算一个唯一的位置向量表示,然后加到对应的词向量上。第一次看到时不由得惊叹这是什么操作?这也能 work? 感觉这种考虑位置信息的方式只是权宜之计。后来又有参数式绝对位置(BERT)、函数式相对位置(NEZHA)的编码方式,说不上孰好孰坏。
LSTM 与 Transformer 的对比:
- 位置编码方式: LSTM 以顺序输入的方式考虑位置信息,Transformer 采用函数式绝对位置编码的方式,个人觉得顺序输入的方式更合理一些。
- 模型表达能力: Transformer 采用多层注意力叠加的方式展现了强大的学习能力,其实单层的 Transformer Encoder 表达能力比较有限,有些场景比不上单层的 LSTM。模型蒸馏得到的双层Bi-LSTM可以达到类似的效果,说明 LSTM 的表达能力并不弱。
- 并行能力: Transformer 的并行能力远远优于 LSTM,所以适合训练多层叠加的模型,多层的LSTM 复杂度难以承受,没有强大的算力别来沾边。
CNN,RNN,LSTM,Transformer之间的优缺点
RNN / LSTM
涉及该问题的递归神经网络和长期短期记忆模型的核心属性几乎相同:
第一个属性是顺序处理(递归计算) 无法并行训练RNN和LSTM:句子必须逐字处理。过去的信息通过过去的隐藏状态保留:序列到序列模型遵循Markov属性,假定每个状态仅取决于先前看到的状态。为了将第二个单词编码为一个句子,我需要先前计算出的第一个单词的隐藏状态,因此我需要首先计算该单词。
第二个属性存在严重的长期依赖问题。由于先前计算出的隐藏状态,因此保留了RNN和LSTM中的信息。关键是特定单词的编码仅在下一个时间步被保留,这意味着单词的编码仅强烈影响下一个单词的表示,在几个时间步长之后其影响很快消失。由于通过特定单位对隐藏状态进行了更深的处理(带有要训练的参数数量增加),LSTM通过引入包含了遗忘门、输入门、输出门的结构改善了RNN中存在的长期依赖问题,但是,问题本质上与递归有关,如果序列过长仍然,仍然面临长期依赖问题。另外网络较深,会出现计算量大和耗时偏多的问题。
Transofrmer
相较于RNN系列模型的优点是避免递归,以便允许并行计算(减少训练时间),并减少由于长期依赖性而导致的性能下降。
第一点是并行计算:句子是整体处理的,而不是逐字处理。(将RNN和LSTM中的递归计算变为矩阵乘法的并行计算);
第二点是transofrmer不受长期依赖问题困扰:原始transofrmer不依赖于过去的隐藏状态来捕获对先前单词的依赖性,而是使用self attention整体上处理一个句子,这就是为什么不存在丢失(或“忘记”)过去信息的风险的原因。此外,多头注意力和位置嵌入都提供有关不同单词之间关系的信息。多头注意力,各个attention head可以学会执行不同的任务(比如8个head分别学习纹理、颜色、轮廓、语义…)。位置嵌入PE,引入了另一种替代复发的创新。这个想法是使用固定或学习的权重,该权重对与句子中标记的特定位置有关的信息进行编码。
缺点:局部信息的获取不如RNN和CNN强;
CNN概念:
传统意义上的多层神经网络是只有输入层、隐藏层、输出层,其中隐藏层的层数按需决定。而卷积神经网络CNN,在传统的多层神经网络基础上,全连接层前面加入了部分连接的卷积层、激活层和池化层操作,使得实际应用场景中能够构建更加深层、功能更强大的网络。
CNN优点:
CNN主要用于识别位移、缩放及其它扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以能够避免显示的特征抽取,隐式地从训练数据中进行学习。另外,CNN局部权重共享的结构可以使得网络并行学习,较好的处理高维数据,更接近于实际的生物神经网络,
CNN缺点:
(1)当网络层数太深时,采用反向传播调整内部参数会使得接近于输入层的变化较慢;
(2)采用梯度下降进行迭代时很容易使得训练结果收敛于局部最优而非全局最优;
(3)池化层会丢失一定的有价值信息,忽略了局部与整体之间的关联性;
(4)特征提取的物理含义不是十分明确,导致可解释性一般。
Transformer优点:
(1)突破了RNN模型不能并行计算的限制
(2)相比CNN,计算两个位置之间的关联所需要的操作次数不会随着距离的增长而增加;
(3)attention机制可以产生更具可解释性的模型,可以从模型中检查attention分布,同时多头注意力的,文章来源:https://www.toymoban.com/news/detail-530657.html
Transformer缺点:
(1)
(2)位置信息编码存在问题,因为位置编码在语义空间中并不具备词向量的可线性变换,只是相当于人为设计的一种索引,所以并不能很好表征位置信息;
(3)由于transformer模型实际上是由残差模块和层归一化模块组合而成,并且层归一化模块位于两个残差模块之间,导致如果层数较多时连乘计算会使得顶层出现梯度消失问题。文章来源地址https://www.toymoban.com/news/detail-530657.html
到了这里,关于LSTM已死,Transformer永生(面试问答RNN/LSTM/Transformer)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!