小程序搜索“ 源码轻舟 ”后续将推出算法和面试模块
坚持学习,好文每日送达!

业务系统对分布式ID的要求
-
唯一性:在分布式系统中,每个节点都需要生成唯一的标识符来确保数据的唯一性。传统的单点生成ID方式无法满足分布式环境下的需求,而分布式ID能够在整个系统中保证每个节点生成的ID都是唯一的。
-
顺序性:某些场景下,需要生成的ID具有一定的顺序性,例如按时间顺序记录事件或日志。分布式ID生成策略能够在保证唯一性的同时,尽可能地保持ID的顺序性,方便对数据进行排序和分析。
-
性能:分布式ID生成策略通常被设计为高性能的方案,能够在高并发的情况下快速生成ID。这对于分布式系统中大量的并行操作和高频率的请求是至关重要的,以确保系统的吞吐量和响应时间。
-
可扩展性:在分布式系统中,节点数量可能会随着系统的扩展而增加。使用分布式ID可以避免单点生成ID的瓶颈,并且能够轻松地扩展到更多的节点,以适应系统的增长和负载的增加。
-
无依赖性:分布式ID生成策略通常是独立于外部资源或服务的,因此不需要依赖特定的数据库或其他中心化的组件。这使得系统更加灵活和独立,减少了对外部资源的依赖性和单点故障的风险。
分布式ID生成方案
-
UUID
-
数据库自增
-
号段模式
-
Redis实现
-
雪花算法(SnowFlake)
-
美团Leaf
-
滴滴TinyID
UUID
UUID(Universally Unique Identifier)是一种标识符,用于在分布式系统中生成唯一的标识值。它是由一组字母和数字组成的128位(16字节)的字符串,通常以连字符分隔成五段,形如:aa82878d-60cb-4a01-9719-b4af90490fbd
-
优点:唯一性、简单易用、高性能(基于本地算法生成)
-
缺点:长度较长,浪费存储空间、可读性差、无序性、不支持自增
数据库自增
假设在一个大型电商项目中,将订单表拆分放在db_0、db_1的两个数据库中,其中db_0数据库中有t_order_01、t_order_02两张订单表,db_1数据库中也有t_order_03、t_order_04两张订单表,如果使用数据库自增来生成分布式ID,那么t_order_01、t_order_02、t_order_03、t_order_04的默认值分别是:1、2、3、4,每次插入数据时的步长是4。如下图所示

虽然数据库的自增看起来是没问题的,但是如果继续扩容是一件很麻烦的事情,因为要重新设置步长,如一开始是4张订单表,步长为4,后面将订单表扩容为8,那么步长就变成8,并且还需要将旧数据重新迁移。
号段模式
- 设计一个专门生成号段的ID生成器,一般是一个单独的服务或者模块,在该服务中维护生成区段号的表,表结构如下,max_id是当前id的最大值,step是步长,一次请求过来,则返回[max_id + 1,max_id + step]的区间,biz_type是业务类型
CREATE TABLE id_generator (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '当前最大id',
step int(20) NOT NULL COMMENT '号段的布长',
biz_type int(20) NOT NULL COMMENT '业务类型'
PRIMARY KEY (`id`)
) - 当需要ID时则向ID生成器请求一个区段,ID生成器则根据max_id和step计算一个号段返回,如[max_id + 1,max_id + step]
优点:高效性、并发性、可扩展
缺点:ID的使用不连续,造成资源浪费、号段的分配和更新需要进行协调和管理,增加了系统的复杂性和管理成本
Redis实现
在Redis中创建一个计数器,通过Redis的原子性操作来生成递增的ID
优点:由于Redis是基于内存操作的,具有高性能、高并发性、可通过搭建Redis集群来支撑更大规模和高负载的系统
缺点:单点故障、需引进Redis组件
雪花算法(SnowFlake)
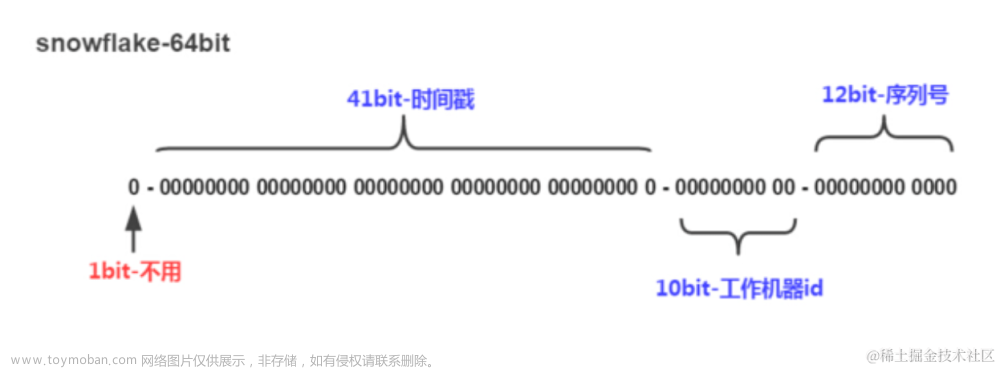
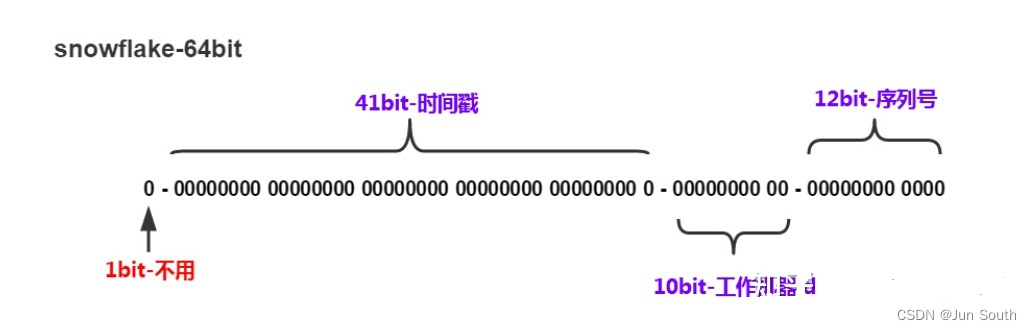
雪花算法是Sharding-jdbc默认的分布式ID生成算法,由64bit的整数组成,结构如下图所示,可分成4部分
-
第一部分的1bit是符号位,0表示是正数,1表示负数,一般都是0
-
第二部分41bit是时间戳,记录生成ID的时间戳,精确到毫秒级。可以有2的41次方种组合,可以使用时间大概是59年。
-
第三部分的10bit是工作节点ID,表示在同一毫秒内生成的ID的节点标识。可以分配给不同的节点,最多可以有1024个不同的节点。
-
第四部分的12bit是序列号,表示同一毫秒内生成的自增序列号。如果在同一毫秒内生成的ID超过了4096个,会等到下一毫秒再继续生成。
-
优点:雪花算法生成的ID是趋势递增,不依赖数据库等第三方系统,生成ID的效率非常高,稳定性好,可以根据自身业务特性分配bit位,比较灵活
-
缺点:雪花算法强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。如果恰巧回退前生成过一些ID,而时间回退后,生成的ID就有可能重复。

美团(Leaf)
Leaf提供两种生成ID的模式,分别是号段模式(Leaf-segment)和snowflake模式(Leaf-snowflake)
-
号段模式
美团Leaf的号段模式对上面讲的号段模式做了优化,在服务端与数据库之间增加了Leaf中间层,由Leaf中间层事先向数据库获取一批ID段缓存起来,当服务端需要获取ID时,直接从Leaf中间层的内存中获取即可。虽然增加了Leaf中间层解决了数据库压力问题,但是当Leaf缓存中的ID用完时,就需要向数据库获取新的号段,这次请求会显得很耗时,为了解决这个问题,美团 Leaf 采用了「双 Buffer + 预加载」的策略,即在内存中维护两个 ID 段,并在上一个 ID 段使用达到 10% 的时候去预加载。

-
Leafsnowflake方案
Leafsnowflake是美团基于SnowFlake雪花算法设计的,解决了雪花算法的时钟回拨问题。美团 Leaf 引入了 zookeeper 来解决时钟回拨问题,其大致思路为:每个 Leaf 运行时定时向 zk 上报时间戳。每次 Leaf 服务启动时,先校验本机时间与上次发 ID 的时间,再校验与 zk 上所有节点的平均时间戳。如果任何一个阶段有异常,那么就启动失败报警。

滴滴TinyID
Tinyid是基于号段模式实现,再简单啰嗦一下号段模式的原理:就是从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,业务服务将号段在本地生成1~1000的自增ID并加载到内存。
Tinyid会将可用号段加载到内存中,并在内存中生成ID,可用号段在首次获取ID时加载,如当前号段使用达到一定比例时,系统会异步的去加载下一个可用号段,以此保证内存中始终有可用号段,以便在发号服务宕机后一段时间内还有可用ID。文章来源:https://www.toymoban.com/news/detail-530873.html
 文章来源地址https://www.toymoban.com/news/detail-530873.html
文章来源地址https://www.toymoban.com/news/detail-530873.html
到了这里,关于分布式主键ID生成策略的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!