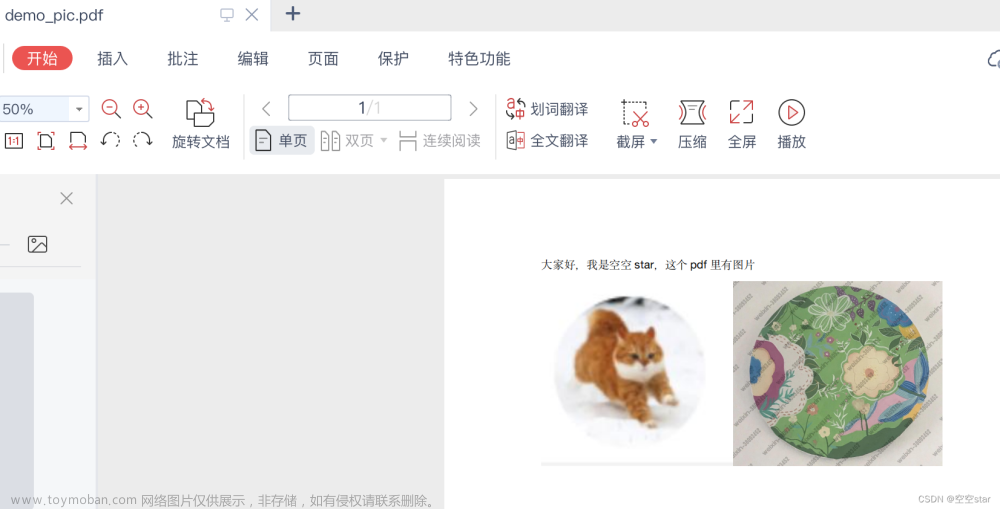
出现这样的原因有可能是因为,在进行页面读取的时候未指定读取的dpi是多少,使得默认读取去96dpi
所以在进行读取时使用
page = doc.load_page(page_number)
# 获取页面的图像对象
pix = page.get_pixmap(dpi=200)
遇到苦难找文档哦
牢记
:
\color{red}{牢记:}
牢记:help()和查看官方文档呀文章来源:https://www.toymoban.com/news/detail-531745.html
import fitz
from PIL import Image
# 打开PDF文件
doc = fitz.open(r"C:\Users\O-c-O\Desktop\11.pdf")
# 遍历每个页面
for page_number in range(doc.page_count):
# 加载页面
page = doc.load_page(page_number)
# 获取页面的图像对象
matrix = fitz.Matrix(1.0, 1.0) # 1.0 表示原始尺寸
# pix = page.get_pixmap(matrix=matrix,dpi=200)
pix = page.get_pixmap(dpi=200,alpha=False)
print(pix.width,pix.height)
# 将图像转换为Pillow的Image对象
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
# 保存图像为PNG格式,不进行压缩
dpi = 120 # 设置所需的 DPI 值
img.save(f'output_{page_number}.png', dpi=(dpi, dpi),)
# img.save(f'output_{page_number}.png',)
# 关闭文档对象
doc.close()
相关的其他参数还有:文章来源地址https://www.toymoban.com/news/detail-531745.html
- matrix:指定应用于页面的转换矩阵(fitz.Matrix 对象)。默认为
None,表示不应用任何转换。通过调整缩放、旋转和裁剪等操作,可以对页面进行自定义的转换。 - clip:指定是否裁剪图像以适应页面边界框。默认为 False,表示不进行裁剪。
- alpha:指定是否提取图像的透明通道。默认为 False,表示不提取透明通道。
- dpi:指定图像的采样密度(每英寸像素数量)。默认为 None,表示使用默认的采样密度。
- band_width:指定每个带宽条的像素宽度。默认为 0,表示禁用带宽条。
- band_height:指定每个带宽条的像素高度。默认为 0,表示禁用带宽条。
- band_sep:指定带宽条之间的像素间隔。默认为 0,表示禁用带宽条。
- band_rows:指定在图像传输期间要生成的带宽条的行数。默认为 0,表示禁用带宽条。
到了这里,关于为什么使用fitz读取pdf转为图片模糊的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!