版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/zaibeijixing/article/details/131581809
————————————————
目录
准备工作
1、MNN编译
2、yolov8-mnn文件夹构建
3、编译
4、执行
附:
yolov8_demo.cpp
CMakeLists.txt
准备工作
下载MNN,GitHub - alibaba/MNN ,并编译,生成依赖库。
下载 https://github.com/wangzhaode/yolov8-mnn/ 代码,主要用到.cpp和CMakeLists.txt,或者直接见文末附件,该代码可放在MNN的同级目录。
1、MNN编译
在MNN编译后,再按如下步骤再次编译,生成如下3个依赖项。
cd MNN
mkdir build_s
cmake -DMNN_BUILD_OPENCV=ON -DMNN_IMGCODECS=ON ..
make
cp libMNN.so express/libMNN_Express.so tools/cv/libMNNOpenCV.so ../yolov8-mnn/cpp/libs
2、yolov8-mnn文件夹构建
主要是构建文件结构,包括依赖的MNN头文件和上述生成的.so文件,以便正确链接编译。
此处此处直接按照readMe命令会发现路径可能细节不对或偏差,需要自己联系上下文改正即可,最好直接按照下图构建,最终的目的是达到如图操作。

其中:
build_s是编译生成所用;
include用来存放MNN的头文件;
libs用来存放MNN编译的依赖库;
s_存放执行命令所需文件,非必需,上述3个必需。
3、编译
上述文件夹构建完成,即可编译生成可执行文件
cd yolov8-mnn/cpp
mkdir build_s && cd build_s
cmake ..
make

4、执行
此时把生成的yolov8_demo,下载的yolov8n.mnn和图片bus.jpg放入S_路径下。执行命令:
./yolov8_demo yolov8n.mnn bus.jpg
输出如下:
### box: {670.723145, 375.684723, 809.897644, 873.593018}, idx: 8254, score: 0.866349
### box: {49.070282, 399.742523, 243.129242, 902.202576}, idx: 8243, score: 0.865096
### box: {219.769562, 405.623505, 345.611481, 858.568176}, idx: 8225, score: 0.829490
### box: {14.499327, 224.708481, 790.586121, 746.901184}, idx: 8188, score: 0.829328
### box: {-0.187493, 551.358398, 62.278885, 874.772766}, idx: 8280, score: 0.365177
result image write to `res.jpg`.
 文章来源:https://www.toymoban.com/news/detail-531900.html
文章来源:https://www.toymoban.com/news/detail-531900.html
附:
yolov8_demo.cpp
#include <stdio.h>
#include <MNN/ImageProcess.hpp>
#include <MNN/expr/Module.hpp>
#include <MNN/expr/Executor.hpp>
#include <MNN/expr/ExprCreator.hpp>
#include <MNN/expr/Executor.hpp>
#include <cv/cv.hpp>
using namespace MNN;
using namespace MNN::Express;
using namespace MNN::CV;
int main(int argc, const char* argv[]) {
if (argc < 3) {
MNN_PRINT("Usage: ./yolov8_demo.out model.mnn input.jpg [forwardType] [precision] [thread]\n");
return 0;
}
int thread = 4;
int precision = 0;
int forwardType = MNN_FORWARD_CPU;
if (argc >= 4) {
forwardType = atoi(argv[3]);
}
if (argc >= 5) {
precision = atoi(argv[4]);
}
if (argc >= 6) {
thread = atoi(argv[5]);
}
MNN::ScheduleConfig sConfig;
sConfig.type = static_cast<MNNForwardType>(forwardType);
sConfig.numThread = thread;
BackendConfig bConfig;
bConfig.precision = static_cast<BackendConfig::PrecisionMode>(precision);
sConfig.backendConfig = &bConfig;
std::shared_ptr<Executor::RuntimeManager> rtmgr = std::shared_ptr<Executor::RuntimeManager>(Executor::RuntimeManager::createRuntimeManager(sConfig));
if(rtmgr == nullptr) {
MNN_ERROR("Empty RuntimeManger\n");
return 0;
}
rtmgr->setCache(".cachefile");
std::shared_ptr<Module> net(Module::load(std::vector<std::string>{}, std::vector<std::string>{}, argv[1], rtmgr));
auto original_image = imread(argv[2]);
auto dims = original_image->getInfo()->dim;
int ih = dims[0];
int iw = dims[1];
int len = ih > iw ? ih : iw;
float scale = len / 640.0;
std::vector<int> padvals { 0, len - ih, 0, len - iw, 0, 0 };
auto pads = _Const(static_cast<void*>(padvals.data()), {3, 2}, NCHW, halide_type_of<int>());
auto image = _Pad(original_image, pads, CONSTANT);
image = resize(image, Size(640, 640), 0, 0, INTER_LINEAR, -1, {0., 0., 0.}, {1./255., 1./255., 1./255.});
auto input = _Unsqueeze(image, {0});
input = _Convert(input, NC4HW4);
auto outputs = net->onForward({input});
auto output = _Convert(outputs[0], NCHW);
output = _Squeeze(output);
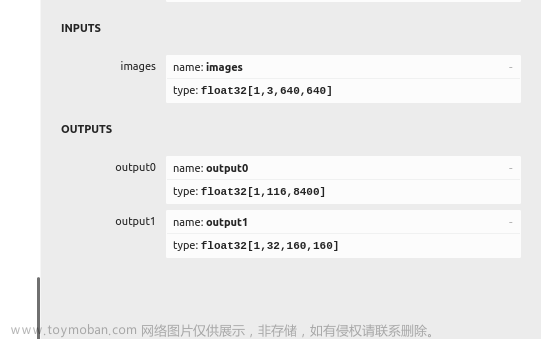
// output shape: [84, 8400]; 84 means: [cx, cy, w, h, prob * 80]
auto cx = _Gather(output, _Scalar<int>(0));
auto cy = _Gather(output, _Scalar<int>(1));
auto w = _Gather(output, _Scalar<int>(2));
auto h = _Gather(output, _Scalar<int>(3));
std::vector<int> startvals { 4, 0 };
auto start = _Const(static_cast<void*>(startvals.data()), {2}, NCHW, halide_type_of<int>());
std::vector<int> sizevals { -1, -1 };
auto size = _Const(static_cast<void*>(sizevals.data()), {2}, NCHW, halide_type_of<int>());
auto probs = _Slice(output, start, size);
// [cx, cy, w, h] -> [y0, x0, y1, x1]
auto x0 = cx - w * _Const(0.5);
auto y0 = cy - h * _Const(0.5);
auto x1 = cx + w * _Const(0.5);
auto y1 = cy + h * _Const(0.5);
auto boxes = _Stack({x0, y0, x1, y1}, 1);
auto scores = _ReduceMax(probs, {0});
auto ids = _ArgMax(probs, 0);
auto result_ids = _Nms(boxes, scores, 100, 0.45, 0.25);
auto result_ptr = result_ids->readMap<int>();
auto box_ptr = boxes->readMap<float>();
auto ids_ptr = ids->readMap<float>();
auto score_ptr = scores->readMap<float>();
for (int i = 0; i < 100; i++) {
auto idx = result_ptr[i];
if (idx < 0) break;
auto x0 = box_ptr[idx * 4 + 0] * scale;
auto y0 = box_ptr[idx * 4 + 1] * scale;
auto x1 = box_ptr[idx * 4 + 2] * scale;
auto y1 = box_ptr[idx * 4 + 3] * scale;
auto class_idx = ids_ptr[idx];
auto score = score_ptr[idx];
printf("### box: {%f, %f, %f, %f}, idx: %d, score: %f\n", x0, y0, x1, y1, idx, score);
rectangle(original_image, {x0, y0}, {x1, y1}, {0, 0, 255}, 2);
}
if (imwrite("res.jpg", original_image)) {
MNN_PRINT("result image write to `res.jpg`.\n");
}
rtmgr->updateCache();
return 0;
}CMakeLists.txt
cmake_minimum_required(VERSION 3.0)
project(yolov8_demo)#yolov8-mnn
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11")
# include dir
include_directories(${CMAKE_CURRENT_LIST_DIR}/include/)
# libs dir
link_directories(${CMAKE_CURRENT_LIST_DIR}/libs)
# source files
FILE(GLOB SRCS ${CMAKE_CURRENT_LIST_DIR}/yolov8_demo.cpp)
# target
add_executable(yolov8_demo ${SRCS})
# link
if (MSVC)
target_link_libraries(yolov8_demo MNN)
else()
target_link_libraries(yolov8_demo MNN MNN_Express MNNOpenCV)
endif()本文主要参考https://github.com/wangzhaode/yolov8-mnn 并对其中的疏漏和错误进行了修改。文章来源地址https://www.toymoban.com/news/detail-531900.html
到了这里,关于yolov8-mnn C++部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[C++]使用纯opencv部署yolov8旋转框目标检测](https://imgs.yssmx.com/Uploads/2024/04/858578-1.jpeg)





