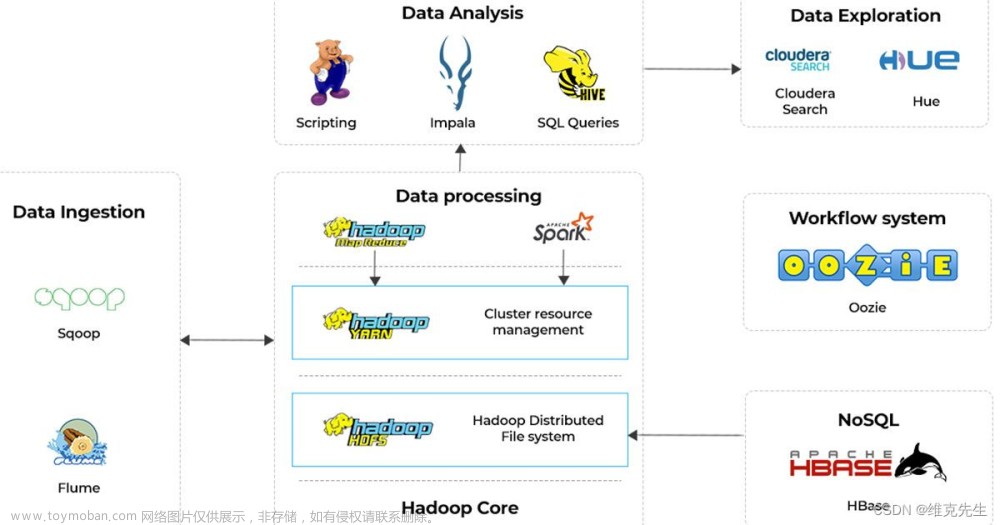
Hive和HBase是两个在大数据领域中常用的开源项目,它们有不同的功能和用途:
-
Hive(Apache Hive):
- Hive是一个基于Hadoop的数据仓库基础架构,它提供了一种类似于SQL的查询语言(HiveQL)来处理和分析大规模的结构化数据。
- Hive旨在使非技术用户能够使用类似于SQL的语言进行数据查询和分析,无需编写复杂的MapReduce程序。
- Hive使用Hadoop的MapReduce框架来执行查询,将HiveQL语句转换为MapReduce作业,并在Hadoop集群上执行这些作业。
- Hive适用于处理和分析大规模的结构化数据,通常用于数据仓库、数据分析和数据处理任务。
-
HBase(Apache HBase):
- HBase是一个分布式、面向列的NoSQL数据库,构建在Hadoop之上,并利用HDFS(Hadoop分布式文件系统)进行数据存储。
- HBase提供了高可靠性、高扩展性和高性能的数据存储解决方案,适用于大规模数据的实时读写操作。
- HBase使用分布式存储模型,数据以表格形式组织,具有动态扩展性和自动分区功能,能够处理海量数据和高并发读写请求。
- HBase的数据访问接口类似于传统数据库,支持原子性的读写操作和强一致性。
联系和区别:文章来源:https://www.toymoban.com/news/detail-532072.html
- Hive和HBase都是基于Hadoop生态系统的项目,它们可以共同使用并处理大数据。
- Hive主要用于数据查询和分析,支持类似于SQL的查询语言,而HBase则是一个分布式数据库,用于实时读写操作。
- Hive适用于大规模结构化数据的分析和处理,而HBase适用于海量数据的实时读写操作。
- 在某些场景下,Hive和HBase可以结合使用。例如,使用Hive进行数据分析后,将结果存储到HBase中以供实时查询和访问。
总之,Hive和HBase是在大数据领域中用于不同目的的两个重要工具。Hive主要用于数据分析和查询,而HBase用于实时读写操作的分布式数据库。文章来源地址https://www.toymoban.com/news/detail-532072.html
到了这里,关于什么是hive?什么是hbase?它们有什么区别与联系。的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!