TCP 非常重要,它的内容很多,今天只能讲解其中的一部分,但足以让你超越 80 % 的编程开发人员对于 TCP 的认知。
本篇内容非常多,非常干,希望你花点时间仔细研究,我相信会对你有所帮助。
1. TCP 协议是什么?
TCP 是 Transmission Control Protocol 的缩写,意思是传输控制协议。一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793 定义。
从这个定义里,有很多初学就首先懵了。
什么是面向连接?
什么是可靠的通信协议?
什么是面向字节流的?
为了让你对 TCP 有个初步的了解,我打算先从这个定义入手。
什么是面向连接?
面向连接,是相对于另一个传输层协议 UDP 而言的(后面会单独介绍)。
TCP 是面向连接的,所以在开始传输数据前要先经历三次握手建立连接。
而 UDP 即刻就可以传输数据,并不需要先三次握手来建立连接。
一个更可靠,而一个更开放。
就好比,你去医院看病,如果是专家号,一般要提前预约,对只要预约(三次握手建立了连接)上了,你去了就不会看不上病。这是 TCP 。
而如果你没有预约,就直接跑过去,那不好意思,你只能看普通门诊,而普通门诊等的人很多,你就不一定能看得上病了。这是 UDP。
既然是连接,必然是一对一的,就像绳子的两端。所以 TCP 是一对一发送消息。
而 UDP 协议不需要连接,可以一对一,也可以一对多,也可以多对多发送消息。
什么是可靠的通信协议?
可不可靠,也是相对于 UDP 而言的。
TCP 自身有三次握手和超时重传等机制,所以无论网络如何变化,主要不是主机宕机等原因都可以保证一个报文可以到达目标主机。
与之对比, UDP 就比较不负责任了,不管你收不收得到,反正我就无脑发,网络拥堵我也发,它的职责是发出去。
什么是面向字节流的?
与面向字节流相对的是,UDP 的面向报文。
面向报文的传输方式是应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。因此,应用程序必须选择合适大小的报文。若报文太长,则IP层需要分片,降低效率。若太短,会是IP太小。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。这也就是说,应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。
面向字节流的话,虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序看成是一连串的无结构的字节流。TCP有一个缓冲,当应用程序传送的数据块太长,TCP就可以把它划分短一些再传送。如果应用程序一次只发送一个字节,TCP也可以等待积累有足够多的字节后再构成报文段发送出去。
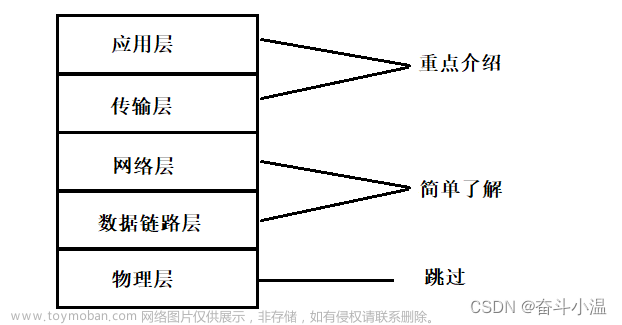
2. 完整解读 TCP 报文格式
搞懂一个通信协议,了解它的报文格式是必经之路。
TCP 的报文段结构,可以从下面这张图中非常清晰的看到。

接下来,我会一个一个讲解这些字段的内容。
源端口 和 目标端口:各占 2 个字节。2 个字节,也就是 16个 bit,这应该也能说明为什么计算机端口的范围是 1-65535 (0 不使用,2^16=65536,最大位65536不使用)了吧?有了源端口和目标端口,加上 IP 首部里的源IP和目标IP,就可以唯一确定一个连接。
序列号:共占用 4个字节。说明序列号的范围是 [0, 2^32-1],也就是 [0, 4294967296]。当序号增加到 4294967296 后,下一个序号将回到0重新开始。在建立连接时由计算机生成的随机数作为其初始值(ISN,即Initial Sequence Number,初始序列号),通过 SYN 包传给接收端主机,每发送一次数据,就累加一次该「数据字节数」的大小(其中要注意的是 SYN 和 FIN 包的 seq 也要消耗一个序号)。用来解决网络包乱序问题。
确认号:共占用 4个字节。说明确认号的范围是 [0, 2^32-1],也就是 [0, 4294967296]。它表示期望收到对方下一次数据的序列号(所以 ack 一般都是上次接收成功的数据字节序号加1),发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。用来解决不丢包的问题。TCP在接收到数据后 200ms 才会发送ACK包,这种设定是为了等待是否有数据可以一起发送的。
数据偏移:共占 4 个bit,它表示的是TCP报文的数据起始处距离TCP报文起始处的距离有多远。实际生活中我们说距离多远,我们的单位通常是米,而这里距离有多远,单位是 4 个字节(也就是 32bit)。由于 4 个bit,能表示的最大整数是 15,也就说明 TCP 报文里数据开始的位置距离报文起点是 60 个字节(4*15)。这意味着 TCP 的首部(除数据外的都叫首部)长度是 20-60 个字节。
窗口:共占 16 个bit,因此最大的窗口大小为 2^16-1 = 65535 = 64k。这是早期的设计,对于现在的网络应用,可能会不太够,因此可以在选项里加一个 窗口扩大选项,来传输更多的数据。窗口指的是发送本报文段的一方的接受窗口(而不是自己的发送窗口)。窗口值告诉对方:从本报文段首部中的确认号算起,接收方目前允许对方发送的数据量(以字节为单位)。之所以要有这个限制,是因为接收方的数据缓存空间是有限的。总之,窗口值作为接收方让发送方设置其发送窗口的依据。
保留:占 6个bit,保留为今后使用,目前应置为0。
紧急指针:占16个bit。紧急指针仅在URG=1时才有意义,它指出本报文段中的紧急数据的字节数(紧急数据结束后就是普通数据) 。因此,在紧急指针指出了紧急数据的末尾在报文段中的位置。当所有紧急数据都处理完时,TCP就告诉应用程序恢复到正常操作。值得注意的是,即使窗口为0时也可以发送紧急数据。
标志位:
-
SYN(SYNchronization):在连接建立时用来同步序号。当SYN=1而ACK=0时,表明这是一个连接请求报文段。对方若同意建立连接,则应在响应的报文段中使SYN=1和ACK=1,因此SYN置为1就表示这是一个连接请求或连接接受报文。
-
ACK(ACKnowledgment):仅当ACK = 1时确认号字段才有效,当ACK = 0时确认号无效。TCP规定,在连接建立后所有的传送的报文段都必须把ACK置为1,如果你可以看下我后面 wireshark 抓的包里除了 最初建立连接的 SYN 包之外,其他的包也都有 ACK 标志。
-
RST(ReSet):当 RST=1 时,表示 TCP 连接中出现异常(如主机崩溃或其他原因)必须强制断开连接,然后再重新建立连接进行传输。RST置为1还用来拒绝一个非法的报文段或拒绝打开一个连接。
-
FIN(Finish):当FIN=1 时,表示今后不会再有数据发送,希望断开连接。
-
PSH(Push) 当两个应用进程进行交互式的通信时,有时在一端的应用进程希望在键入一个命令后立即就能收到对方的响应。在这种情况下,TCP就可以使用推送(push)操作。这时,发送方TCP把PSH置为1,并立即创建一个报文段发送出去。接收方TCP收到PSH=1的报文段,就尽快地(即“推送”向前)交付接收应用进程。而不用再等到整个缓存都填满了后再向上交付。
-
URG(Urgent):当URG=1时,表明开户了urgent mode,紧急指针就开始生效了。
选项:长度可变,最长可达40个字节。当没有使用“选项”时,TCP的首部长度是20字节。
-
MSS 选项:TCP报文段中的数据字段的最大长度,后面有详解。
-
窗口扩大选项:占用三个字节,使得接收端可接收更多的数据,由 2^16-1 扩充到 2^(16+14)-1,其中这个14是窗口移位记数器的最大值。详情请参见:TCP/IP详解 卷1 协议 P262
-
时间戳选项:共占 10 个字节,其中最主要的字段是时间戳字段(4字节)和时间戳回送回答字段(4字节)。
相关视频推荐
4个小时搞懂tcp/ip协议栈,从tcp/ip协议栈原理到实现一个网络协议栈
10道面试必问的经典网络八股文,让你在面试中逼格满满
dpdk让你的开发走向硬核,拉开与crud仔的区别
免费学习地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

3. 如何模拟 TCP 连接?
只搞懂报文格式,没有实战的话,就永远只停留在字面上,无法深刻地理解它。
所以接下来我会使用 wireshark 进行对三次握手、数据传输、四次挥手进行一次抓包并分析这个过程。
但是在开始之前 ,首先要学会模拟建立一个 tcp 连接,好能让我们轻松使用过滤器来显示结果。
为此我使用 Python 写了两个小脚本
1、服务端
监听 13200 端口,如果有客户端连接就发送 hello 字符串
# tcp_server.py
import socket # 导入 socket 模块
import time
s = socket.socket() # 创建 socket 对象
host = socket.gethostname() # 获取本地主机名
port = 13200 # 设置端口
s.bind((host, port)) # 绑定端口
s.listen(5) # 等待客户端连接
while True:
c, addr = s.accept() # 建立客户端连接
c.send('hello'.encode("utf-8"))
c.send('world'.encode("utf-8"))
time.sleep(1)
c.close() # 关闭连接运行后,可以使用 lsof 命令查看 13200 端口是否处于监听中

2、客户端
连接 13200 端口,并接收并打印服务端发送的内容
# tcp_client.py
import socket # 导入 socket 模块
import time
s = socket.socket() # 创建 socket 对象
host = socket.gethostname() # 获取本地主机名
port = 13200 # 设置端口号
s.connect((host, port))
print(s.recv(1024))
time.sleep(2)
s.close()4. Wireshark 抓包实战分析
一切准备就绪后,打开我们的 wireshark ,并设置捕获过滤器 port=13200

然后开启抓包,最后执行上面的 客户端代码tcp_client.py,就可以在 wireshark 上看到如下内容。

三次握手
三次握手的过程可以参考下面这张图来帮助理解

使用 wireshark 抓到的三次握手的包如下所示

客户端要连接上服务端,首先要发送一个 SYN 包表示请求连接。这个SYN 包的 seq 为0。这是第一次握手。
当服务端接收这个 SYN 包时,知道了有人要连接自己,就发了一个 ACK 包说:你要连接这件事,我已经知道啦。但是连接是双方的事情,我也要连接客户端呀,因此 服务端实际上也会发送一个 SYN 包给客户端,请求连接。此时 ACK 和 SYN 如果分开发,服务端觉得太麻烦了,于是就把这两个包合并在一起发,所以实际上只发一个 SYN+ACK 的包。这一点说重要也不重要,说不重要也重要,因为面试的时候经常会问到,**为什么不是四次握手呢?**答案就在这里,因为一个包可以解决的事情没必要发两个包。这是第二次握手。
当客户端接收到服务端发送的 SYN+ACK 包时,知道服务端同意了自己的请求,并且也要求连接自己,有来就有往,客户端连忙回了个 ACK 包表示同意。这就是第三次握手。
数据传输
在上面的 Python 代码中,服务端会向客户端发送了两次数据:hello 和 world
那么这个数据是在哪里发送的呢?
仔细看 wireshark 抓到的包,有两个 PSH 的包,意思就是有数据传输的意思。
打开这两个包分析一下
首先是第一个包

然后是第二个包
这里需要你理解的有两点
1、为什么这里的 seq 为6呢?
因为第一次的 seq 为1,len=5,一共发了5个字节,所以第二次发送,要从6开始计数啦。
2、为什么第一次 ack 为1,而第二次ack还是1呢?
因为客户端没有向服务端发送数据,所以 ack 将始终为1,直到客户端要向服务端发送数据。

四次挥手
四次挥手的过程可以参考下面这张图来帮助理解

使用 wireshark 抓到的四次挥手的包如下所示

wireshark 四次挥手
在服务端发送完两次数据后,调用一次了 close 方法,发送了一个 FIN 包请求关闭连接,这是第一次挥手,这个 FIN 包里的 seq 为11,是两次发送的数据长度+1,很容易理解,ack 始终为 1,上面讲过了也好理解。
当客户端收到了服务端发来的 FIN 包后,知道了服务端要关闭连接了,于是就回了一个 ACK 的应答包(这是第二次挥手),告诉服务端:恩,我知道了。但由于客户端这边还有一些事情要做(可能是还有数据要发送之类的),所以要晚点才能关闭连接。这里的 ACK 包,seq 号 是取第一次挥手的 ack 号,而 ack 号是取 第一次挥手的 seq +1.
等客户端事情也做完了(time.sleep 结束),也会主动发送一个 FIN 包(代码里是通过调用 close 方法实现)告诉服务端:我这边也结束了,可以关闭连接啦。这是第三次挥手。这个 FIN 包里的 seq 号还是取第一次挥手的 ack 号,而 ack 号也是取 第一次挥手的 seq +1,这和第二次挥手时是一样的。
既然是一样的,那为什么不一起发送呢?
这个问题很好。当服务端数据都发送完了要关闭连接,而客户端自己也没什么事情 要做了也要关闭连接,确实是可以一起发送。这时候就四次挥手就变成了三次挥手,所以挥手并不总是四次的。
上面详细解析了三次挥手,还差最后一次。
最后一次挥手,就是服务端接收到客户端的 FIN 包后,知道了客户端要关闭连接了,就回了一个 ACK 应答包。此时的 seq 为第三次挥手的 ack,而 ack 为 第三次挥手的 seq +1。
至此,四次挥手全部完成。
5. 拷问灵魂的四个问题
问题1:为什么要三次握手?
在建立连接前要经历三次握手,几乎是人尽皆知的事情。
但是为什么需要三次握手,这是一个值得思考的问题。
在大多数的文章里面,讲到三次握手都会用形象的比喻来跟你解释,比如和女朋友打电话的场景。
她:“你可以听到了吗?” 我:“可以呀,你呢,你可以听到我的吗?” 她:“我也可以听到了。” # 确认对应可以听到了再对话 我:“你吃饭了吗?“ 她:“吃啦。“
从这个例子里,可以提炼出一点,就是三次握手就是在确保连接的双方都能发送且接收到对方的消息。
这个例子是好的,但是只讲这个例子又是不够的。
这会让读者对三次握手停留在表层,导致无法真正去学习 TCP 的精髓之处。
接下来,我会说说我对 TCP 的理解。
关于 为什么需要握手(注意:这里还没开始讨论为什么要三次握手),我认为应该有两个理由:
-
同步起始序列号,为后续数据传输做准备
-
保证双方都可能发送数据且能接收数据
关于第一点,其实两次握手就可以,客户端把自己的 seq 通过 SYN 包告诉服务端,而服务端把自己的 seq 通过 SYN+ACK 包告诉客户端。
而第二点呢,必须要三次握手才能保证,这个大家应该能够理解,不再赘述。
除此之外,在网络上,你会经常看到还有第三个理由
他们的论据是在 RFC 793 中可以找出下面这句话
The principle reason for the three-way handshake is to prevent old duplicate connection initiations from causing confusion.
翻译一下,就是三次握手的最主要原因是为了防止旧的重复连接初始化造成混乱。
怎么理解这句话呢?举个例子吧
由于网络环境是错综复杂的,当我们发送了一个SYN包 a 后,很有可能过了很久还没有到达目标机器,此时,客户端会重新发送一个 SYN 包 b重新请求连接。

b 包比 a 包先到达了目标机器(即使a包是先发的),当目标机器收到了 b 包,就会回复给源机器一个回包,当后面 a 包也到达了目标机器后,对于目标机器来说,虽然a 和 b 是来源于同一机器 同一端口,但是它才不管是不是重复连接,因为对于目标机器来说,只要来请求连接我都欢迎,收一个我回一个,至于哪个才是最新的连接,哪个是重复的?它不管,它把这个职责交还给了客户端,毕竟哪个包才是最新的,它最清楚了。
那问题就来了,源机器是如何决定 a 包过期的呢?
源机器 收到了来自目标机器 对 a 包的 ACK 回应后,通过自身的上下文信息,知道了这是一个历史连接(序列号过期或超时),那么客户端就会发送 RST 报文给服务端,表示中止这一次连接。
由此,我们可以看到,三次握手可以解决这个重复连接的问题。
这里请注意,我说的是 可以解决,而不是说 因此我们需要三次握手。
没有第三次握手会有多个重复连接导致浪费资源,是建立在三次请求才会建立连接的基础上才会出现的问题,这不是设计三次请求的原因。只是三次握手刚好也解决了这个问题,这个逻辑要搞清楚。
问题2:为什么不是握手两次?
这个问题可以转换成『只握手两次就建立连接会出现什么样的问题?』
还是用给女朋友打电话这个例子,男朋友如果没有跟女朋友确认对方是否可以听到自己的话,就自己一直在说说说,最后只能尴尬收场。这就是我们所说的不可靠的连接,只是单向,而不是双向。
她:“你可以听到了吗?” 我:“可以呀” # 没有向对方确认是否可以听到自己就开始一直说说说 我:“你吃饭了吗?“ 我:“人呢?“ 我:“喂?“ 我:“去哪啦?“
在实际应用上,其实只握手两次还会出现更严重的问题,那就是资源浪费。
还是上面那个例子,a 包由于网络拥堵,迟迟没有发到目标机器 ,由于超时源机器会重新发送一个 SYN 包 b,如果只进行了两次握手,目标机器就建立了连接,那么当 b 包到达后,目标机器又会创建一个连接,而这个连接是无用的、多余的。

这里仅仅假设只超时重发一次就成功了,如果超时重发了 10 次,甚至更多呢?本来TCP 传输只需要一个连接就行了,现在服务端却创建了 n 个 连接,对于服务器资源来说无疑是非常浪费的。
问题3:为什么不是握手四次?
看到这里,你应该很清楚 三次握手的流程了。
那么握手四次是什么样的呢?
还是以给女朋友打电话的例子来说明
她:“你可以听到了吗?” 我:“可以呀!” 我:“你呢,你可以听到我的吗?” 她:“我也可以听到了。”
和三次握手相对比,其实就是把原来第二次握手的内容拆分成两次发送。

所以为什么不握手四次?
因为三次握手就可以完成的事,为什么要四次握手呢?没必要。
问题4:为什么不握手五次或更多?
这个问题有点迷,你可能还不太清楚,还是以跟女朋友打电话为例
她:“你可以听到了吗?” 我:“可以呀,你呢,你可以听到我的吗?” 她:“恩,我也可以听到了。你呢,现在还可以听到吗?” 我:“可以呀,现在你那边还听到我的吗?” 她:“是的,可以,你呢,可以听到我现在说的吗” 我:“可以听到,那你呢?” ... ...
在每一次跟确认可以听到对方的声音时,还生怕这个消息对方收不到这个消息,所以两个人就一直在确认,跟个zz一样。
所以你问我,为什么不握手五次或更多?
因为三次是基本保障,再多一个,就是多余,容易死循环。
6. MTU 和 MSS 是什么?
MTU
Maximum Transmission Unit,最大传输单元。
在TCP/IP协议族中,指的是IP数据报能经过一个物理网络的最大报文长度,其中包括了IP首部(从20个字节到60个字节不等)。
由此我们知道,MTU 为多大跟链路层的介质有关,我们接触最多的以太网的 MTU 设为1500字节。
其他的你可以参考 下面这张图(摘自维基百科)

如果上层协议(如 TCP)交给IP协议的内容实在是太多,使得 IP 报文的大小超过了 MTU ,以以太网为例,如果 IP 报文大小超过了1500 Bytes ,那么IP报文就必须要分片传输,到达目的主机或目的路由器之后由其进行重组分片。
IP分片发生在IP层,不仅源端主机会进行分片,中间的路由器也有可能分片,因为不同的网络的MTU是不一样的,如果传输路径上的某个网络的MTU比源端网络的MTU要小,路由器就可能对IP数据报再次进行分片。而分片数据的重组只会发生在目的端的IP层。
MSS
Maximum Segment Size ,它表示的是 TCP 报文段中的数据字段的最大长度。
数据字段加上TCP首部才等于整个的TCP报文段。所以MSS并不是整个TCP报文段的最大长度,而是“TCP报文段长度减去TCP首部长度”。
MSS 和 MTU 的关系是:
MSS = MTU - IP首部大小 - TCP首部大小

那为什么要规定一个最大报文长度MSS呢?
这并不是考虑接受方的接收缓存可能存放不下TCP报文段中的数据。实际上,MSS与接收窗口值没有关系。我们知道,TCP报文段的数据部分,至少要加上40字节的首部(TCP首部20字节和IP首部20字节,这里还没有考虑首部中的可选部分)才能组装成一个IP数据报。
若选择较小的MSS长度,网络的利用率就降低。设想在极端情况下,当TCP报文段只含有1字节的数据时,在IP层传输的数据报的开销至少有40字节(包括TCP报文段的首部和IP数据报的首部)。这样,对网络的利用率就不会超过1/41。到了数据链路层还要加上一些开销。
但反过来,若TCP报文段非常长,那么在IP层传输时就有可能要分解成多个短数据报片。在终点要把收到的各个短数据报片组成成原来的TCP报文段,当传输出错时还要进行重传。
IP层是没有超时重传机制的,如果IP层对一个数据包进行了分片,只要有一个分片丢失了,只能依赖于传输层进行重传,结果是所有的分片都要重传一遍,这个代价有点大。
因此,MSS应尽可能大些,只要在IP层传输时不需要分片就行。由于IP数据报所经历的路径是动态变化的,因此在这条路径上确定的不需要的分片的MSS,如果改走另一条路径就可能需要进行分片。因此最佳的MSS是很难确定的。
在连接过程中,双方都把自己能够支持的MSS写入这一字段,以后就按照这个数值传输数据,两个传送方向可以有不同的MSS值。若主机未填写这一项,则MSS的默认值是536字节长。因此,所有在互联网上的主机都应该接受的报文段长度是536+20(固定首部长度)=556字节。
7. 网络编程的常规步骤
上面为了方便抓包,我写了一个服务器和客户端程序进行通信。
这里有必要说一下,面向 TCP 进行网络编程的常规步骤

如果是服务端:
-
用函数socket() 创建一个socket;
-
用函数setsockopt() 设置socket属性; 可选步骤
-
用函数bind() 绑定IP地址、端口等信息到socket上;
-
用函数listen() 开启监听;
-
用函数accept() 接收客户端上来的连接;
-
用函数send()和recv() 或者 read()和write() 收发数据;
-
关闭网络连接;
-
关闭监听;
而如果是客户端:
-
用函数socket() 创建一个socket;
-
用函数setsockopt() 设置socket属性 ;可选步骤
-
用函数bind() 绑定IP地址、端口等信息到socket上; 可选步骤
-
用函数connect() 对方的IP地址和端口连接服务器 ;
-
用函数send()和recv() 或者 read()和write() 收发数据;
-
关闭网络连接;
其中最主要、最关键的有三个函数:
connect()
它是一个阻塞函数,通过 TCP 三次握手与服务器建立连接。
一般的情况下 客户端的connect函数 默认是阻塞行为 直到三次握手阶段成功为止。
listen()
不是一个阻塞函数:它会将套接字 和 套接字对应队列的长度告诉Linux内核
他是被动连接的 一直监听来自不同客户端的请求 listen函数只要 作用将socketfd 变成被动的连接监听socket 其中参数backlog作用 设置内核中队列的长度 。
accpet()
是一个阻塞函数,它会从处于 established 状态的队列中取出完成的连接。
当队列中没有完成连接时候就会阻塞,直到取出队列中已完成连接的用户连接为止。
那如果服务器没有及时调用 accept 函数取走完成连接的队列怎么办呢?
服务器的连接队列满掉后,服务器不会对再对建立新连接的 SYN 进行应答,所以客户端的 connect 就会返回 ETIMEDOUT。
8. 注意事项
ack 和 ACK 有区别吗?
上面的分析三次握手和四次挥手时,有一个细节问题,可能不是那么重要,但是需要你搞清楚。
就是 ack 和 ACK 是否一致?答案是否定的
如果是 大写的 ACK ,表示的是标志位里的 flag,除了最初建立连接时的 SYN 包之外,后续的所有包此位都会被置为 1。
如果是 小写的 ack,表示的是希望确认号,表示的是希望接收到对方下一次数据的序列号, ack 一般都是上次接收成功的数据字节序号加1。
TCP 包最多可传输多少数据?
对于TCP协议来说,整个包的最大长度是由最大传输大小(MSS,Maxitum Segment Size)决定,MSS就是TCP数据包每次能够传输的最大数据分段。
为了达到最佳的传输效能 TCP协议在建立连接的时候通常要协商双方的MSS值。
通讯双方会根据双方提供的 MSS值的较小值来确定为这次连接的 MSS值。
在以太网中,MTU 为 1500 Bytes,减去IP数据包包头的大小20Bytes 和 TCP数据段的包头20Bytes,TCP 层最大的 MSS 为 1460。
9. 异常情况分析
试图与一个不存在的端口建立连接(主机正常)
这里的不存在的端口是指在服务器端没有程序监听在该端口。我们的客户端就调用connect,试图与其建立连接。这时会发生什么呢?
这种情况下我们在客户端通常会收到如下异常内容:
Traceback (most recent call last):
File "/Users/MING/Code/Python/tcp_client.py", line 8, in <module>
s.connect((host, port))
ConnectionRefusedError: [Errno 61] Connection refused试想一下,服务端本来就没有程序监听在这个接口,因此在服务端是无法完成连接的建立过程的。我们参考三次握手的流程可以知道当客户端的SYNC包到达服务端时,TCP协议没有找到监听的套接字,就会向客户端发送一个错误的报文,告诉客户端产生了错误。而该错误报文就是一个包含RST的报文。这种异常情况也很容易模拟,我们只需要写一个小程序,连接服务器上没有监听的端口即可。如下是通过wireshark捕获的数据包,可以看到红色部分的RST报文。

试图与一个某端口建立连接但该主机已经宕机(主机宕机)
这也是一种比较常见的情况,当某台服务器主机宕机了,而客户端并不知道,因此会重复发送SYNC数据包.
如下图所示,可以看到客户端每隔一段时间就会向服务端发送一个SYNC数据包。这里面具体的时间是跟TCP协议相关的,具体时间不同的操作系统实现可能稍有不同。

建立连接时,服务器应用被阻塞(或者僵死)
还有一种异常情况是,客户端建立连接的过程中服务端应用处于僵死状态,这种情况在实际中也会经常出现(我们假设仅仅应用程序僵死,而内核没有僵死)。
对于TCP的服务端来说,当它收到SYN数据包时,就会创建一个套接字的数据结构并给客户端回复ACK,再次收到客户端的ACK时会将套接字数据结构的状态转换为ESTABLISHED,并将其加入就绪队列。
当上面的套接字处于就绪队列时,accept函数才被唤醒了,可以从套接字中读取数据。
在 accept 返回之前,客户端也是可以发送数据的,因为数据的发送与接收都是在内核态进行的。客户端发送数据后,服务端的网卡会先接收,然后通过中断通知IP层,再上传到TCP层。TCP层根据目的端口和地址将数据存入关联的缓冲区。
到此,可以得出几点结论。
-
在 accept 返回之前,三次握手已经完成。
-
TCP的客户端是否可以发送数据与服务端程序是否工作没有关系。
但是如果内核也处于僵死状态,那情况可就完全不一样了。文章来源:https://www.toymoban.com/news/detail-532133.html
此时由于机器完全卡死,TCP服务端无法接受任何消息,自然也无法给客户端发送任何应答报文,也不会有后续发送数据的环节了。文章来源地址https://www.toymoban.com/news/detail-532133.html
到了这里,关于扒开 TCP 的外衣,看清 TCP 的本质的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!