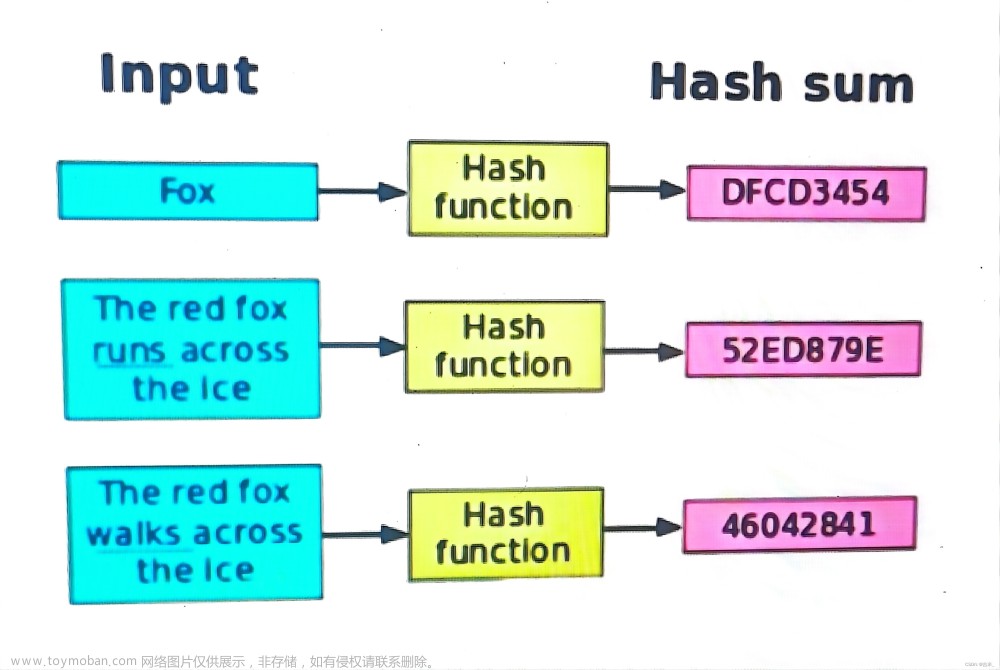
Hive中的HASH函数用于将任意长度的字符串或二进制数据映射为一个固定长度的整数值,其语法如下:
HASH(str)
其中,str是要进行哈希计算的字符串或二进制数据。
Hive中的哈希函数采用的是MurmurHash算法,这是一种非常高效的哈希算法。该算法将输入数据分为若干个块,每个块都进行哈希计算,最终将所有块的哈希值合并起来得到最终的哈希值。
由于哈希函数的特性,相同的输入数据每次计算得到的哈希值都是相同的,因此HASH函数可以用于对数据进行快速的去重或分组。
下面举一个简单的例子来说明HASH函数的使用。假设有如下一张表:
+----+--------+
| id | name |
+----+--------+
| 1 | Alice |
| 2 | Bob |
| 3 | Alice |
| 4 | Carol |
| 5 | Bob |
+----+--------+
如果我们想要按照姓名进行分组,并计算每个分组中记录的数量,可以使用如下的HiveQL语句:
SELECT name, COUNT(*) FROM my_table GROUP BY name;
这个查询语句将会产生如下的结果:文章来源:https://www.toymoban.com/news/detail-532677.html
+--------+--------+
| name | count |
+--------+--------+
| Alice | 2 |
| Bob | 2 |
| Carol | 1 |
+--------+--------+
在执行上述查询语句时,Hive会自动调用HASH函数对每个姓名进行哈希计算,并将具有相同哈希值的姓名放入同一个分组中,最终对每个分组进行统计计算。文章来源地址https://www.toymoban.com/news/detail-532677.html
到了这里,关于Hive中的HASH函数规则及示例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!