分布式消息服务设计
背景
为了解决当A系统的一个“操作”需要发送一个通知(生产者),由关心这个操作的业务(消费者)订阅消息并处理时,实现业务解耦,并适合分布式。本文主要讲解以消息中间件Rabbitmq作为通知服务.
技术选型
1.为什么选消息中间件?
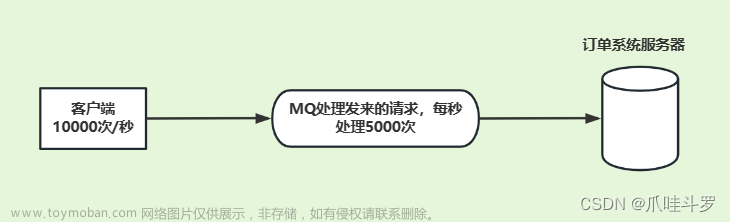
• 异步通信:提高相应速度和吞吐量
• 可靠性:持久化消息,确保可靠传输和处理
• 解耦合:提高可扩展性和可维护性
• 灵活性:支持多种模式和配置
• 透明性:提供监控、追踪、统计等功能,方便调试和性能优化
• 消息缓冲:可以作为消息缓冲区,暂时存储未处理的消息,平衡系统负载和压力
2.为什么选用rabbitmq
| 特性 |
ActiveMQ |
RabbitMQ |
RocketMQ |
Kafka |
| 单机吞吐量 |
万级,比RocketMQ、Kafka低一个数量级 |
同ActiveMQ |
10万级,支撑高吞吐 |
10万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic数量对吞吐量的影响 |
topic可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic |
topic从几十刀几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka尽量保证topic数量不要过多,如果要支撑大规模的topic,需要增加更多的机器资源 |
||
| 时效性 |
ms级 |
微秒级,这是RabbitMQ的一大特点,延迟最低 |
ms级 |
延迟在ms级以内 |
| 可用性 |
高,基于主从架构实现高可用 |
同ActiveMQ |
非常高,分布式架构 |
非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 |
有较低的概率丢失数据 |
经过参数优化配置,可以做到0丢失 |
同RocketMQ |
|
| 功能支持 |
MQ领域的功能极其完备 |
基于erlang开发,并发能力很强,性能极好 |
MQ功能较为完善,还是分布式,扩展性好 |
功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用 |
• 最早大家都用ActiveMQ,但是没有经过大规模吞吐量场景的验证,社区也不是很活跃,所以不推荐使用这个.
• RabbitMQ开源,支撑稳定,活跃度也高,对技术挑战不是特别高的企业可以选择.

• 越来越多的公司,会去用RocketMQ,虽然是阿里出品。但是社区不稳定,建议不要自行去搭建使用,除非你们公司基础架构研发实力较强.
• Kafka是业内标准处理大数据领域的实时计算、日志采集等场景。社区活跃度也很高.
所以,结合实际来看,如果是自住搭建,选择RabbitMQ;当然,如果不想那么费劲儿,可以选择直接购买阿里云的消息服务(RocketMQ).
技术说明
1.什么是RabbitMQ?
RabbitMQ简称MQ是一套实现了高级消息队列协议的开源消息代理软件,简单来说就是一个消息中间件,用来保存消息和传递消息的一个容器.
2.RabbitMQ的常见作用?
RabbitMQ的常见作用有三种,分别是服务间解耦、实现异步通信、流量削峰.
3.RabbitMQ的各个属性:
(1) 信道(channel):
与Rabbitmq Broker建立连接,这连接就是一个TCP连接,也就是connection.
建立TCP连接后,客户端可以创建一个AMQP信道(Channel),每个信道都会被指派一个唯一的ID。信道是建立在Connection之上的虚拟连接,RabbitMq处理的每条AMQP指令都是通过信道完成的.
Connection可以创建多个Channel实例,但是Channel实例不能在线程间共享,应用程序应该为每一个线程开辟一个Channel。多线程间共享Channel实例是非线程安全的(1.导致在网络上出现错误的通信帧交错 2.也会影响发送方确认机制的运行).
多个TCP连接的建立和销毁是非常昂贵的开销,如果遇到使用高峰,性能瓶颈也随之显现。RabbitMq采用类似NIO(非阻塞I/O,包含核心三大部分:Channel信道、Buffer缓冲区和Seletor选择器。NIO基于Channel和Buffer进行操作,数据总是从信道读取数据到缓冲区,或者从缓冲区写去到信道中。Seletor用于监听多个信道的事件(比如链接打开,数据到达等)。因此,单线程可以监听多个数据的信道)的做法,选择TCP连接复用,不仅可以减少性能开销,同时也便于管理.
(2) 交换器(exchange):
-
type:
常见的交换器类型如fanout、direct、topic.
-
durable:
设置是否持久化,true表示持久化。持久化可以将交换器存盘,在服务器重启的时候不会丢失相关信息.
-
autoDelete:
设置是否自动删除。true表示自动删除。自动删除的前提是至少有一个队列或者交换器与这和交换器绑定,之后所有与这个交换器绑定的队列或者交换器都与此解绑。(不能错误的理解为:当于此交换器连接的客户端都断开时).
-
internal:
设置是否内置的。true表示是内置的交换器,客户端程序无法直接发送消息到这个交换器中,只能通过交换器路由到交换器这种方式.
-
备份交换器:
也可以称之为“备胎交换器”,生产者发送消息时,对应交换器未找到绑定的队列,消息会默认丢失掉,可以使用备份交换器(建议类型为fanout,如果为其他的类型,rountingKey不匹配同样会丢失)进行绑定,这样未被路由的消息会存储到备份交换器绑定的队列上。(在声明消息发送交换器时,增加参数alternate-exchange值为备份交换器名来实现).
Map<String, Object> args = new HashMap<String, Object>(); args.put("alternate-exchange", "exchange_backup_ly_demo"); //声明发送消息的交换器 channel.exchangeDeclare(EXCHANGE_NAME, "direct", true, false, args); //声明备份交换器 channel.exchangeDeclare("exchange_backup_ly_demo", "fanout", true, false, null); //声明发送消息的队列 channel.queueDeclare(QUEUE_NAME, true, false, false, null); //将交换器与队列通过路由键绑定 channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, ROUTING_KEY); //声明备份交换器的队列 channel.queueDeclare("queue_backup_ly_demo", true, false, false, null); //将交换器与队列通过路由键绑定 channel.queueBind("queue_backup_ly_demo", "exchange_backup_ly_demo", "");
(3) 队列(queue):
-
durable:
设置是否持久化。true表示持久化。持久化的队列会存盘,在服务器重启的时候可以保证不丢失相关信息.
-
exclusive:
设置是否排他。true表示队列是排他的。排他的队列仅对“首次”声明的连接可见,并在连接断开时自动删除。(这里“首次”是指如果一个连接已经声明了一个排他队列,其他的连接是不允许建立同名的排他队列)排他队列是基于连接可见的,同一个连接的不同信道是可以同时访问同一连接创建的排他队列。即使队列是持久化的,一旦连接关闭或者客户端退出,该排他队列都会被自动删除 ,这种队列适用于一个客户端同时发送和读取消息的应用场景.
-
autoDelete:
设置是否自动删除。true表示队列自动删除。前提是至少有一个消费者连接到这个队列,之后所有与这个队列连接的消费者都断开时,才会自动删除。注意:生产者客户端创建这个队列,或者没有消费者客户端与这个队列连接时,都不会自动删除这个队列.
-
arguments:
其他的一些结构化参数,比如:x-message-ttl、x-expires、x-max-length、x-max-length-bytes等.
-
DLX(死信队列):
消息在一个队列中变成死信之后,它能被重新发送到另一个交换器中.
场景:
A.消息被拒绝(消费者拒绝消费此消息,Basic.Reject/Basic.Nack),并且设置requeue参数为false.
B.消息过期.
C.队列达到最大长度
-
延迟队列:
延迟队列存储的对象是对应的延迟消息(指当消息被发送以后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费).
在AMQP协议中,或者RabbitMq本身没有直接支持延迟队列的功能,但是可以通过(DLX和TTL)模拟出延迟队列的功能.
-
优先级队列:
即具有高优先级的队列具有高的优先权,优先级高的消息具备优先被消费的特权.
先通过设置队列参数x-max-priority配置一个队列的最大优先级.
在发送消息中设置当前消息的优先级.(优先级默认最低为0, 最高为队列设置的最大优先级).
(4) 工作模式:
-
简单模式:
一个生产者、一个消费者,不需要设置交换机(使用默认的交换机)
-
工作队列模式:
一个生产者、多个消费者(竞争关系),不需要设置交换机(使用默认的交换机)
-
发布订阅模式:
需要设置类型为fanout的交换机,并且交换机和队列进行绑定, 当发送消息到交换机 后,交换机会将消息发送到绑定的队列.
-
路由模式 Routing
需要设置类型为direct的交换机,交换机和队列进行绑定,并且指定routing key,当发送消息到交换机后,交换机会根据routing key将消息发送到对应的队列。
-
通配符模式Topic
需要设置类型为topic的交换机,交换机和队列进行绑定,并且指定通配符方的routing key,当发送消息到交换机后,交换机会根据routing key将消息发送到对应的队列.
PS:消息是存在队列中的,如果要衡量RabbitMq当前的QPS只需看队列的即可。
生产者例子:
package com.ly.liyong.rabbitmq;
import com.rabbitmq.client.*;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
public class PublisherController {
private static final String EXCHANGE_NAME = "exchange_ly_demo";
private static final String ROUTING_KEY = "routing_ly_demo";
private static final String QUEUE_NAME = "queue_ly_demo";
private static final String IP_ADDRESS = "47.105.121.99";
private static final int PORT = 5672;
public static void main(String[] args) throws IOException,
TimeoutException, InterruptedException {
//定义连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(IP_ADDRESS);
factory.setPort(PORT);
factory.setUsername("lpadmin");
factory.setPassword("lpadmin");
//创建连接
Connection connection = factory.newConnection();
//创建信道
Channel channel = connection.createChannel();
//direct模式的持久化、非自动删除的交换器
channel.exchangeDeclare(EXCHANGE_NAME, "direct", true, false, null);
//持久化、非排他的、非自动删除的队列
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
//将交换器与队列通过路由键绑定
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, ROUTING_KEY);
for (int i = 1; i < 5; i++) {
//发送一条持久的消息
String msg = "大帅哥,你好!" + i;
byte[] msgByte = msg.getBytes();
System.out.println("send: " + msg);
// channel.basicPublish(EXCHANGE_NAME, ROUTING_KEY, MessageProperties.PERSISTENT_TEXT_PLAIN, msgByte);
//设置消息相关属性
//delivery_mode设置为2,即消息会被持久化(即存入磁盘)在服务器中
//priority设置这条消息的优先级为0
// channel.basicPublish(EXCHANGE_NAME, ROUTING_KEY,
// new AMQP.BasicProperties.Builder()
// .contentType("text/plain")
// .deliveryMode(2)
// .priority(1)
// .build(), msgByte);
//发送带有headers的消息,并设置消息过期时间为10s
Map<String, Object> headers = new HashMap<String, Object>();
headers.put("localtion", "here");
headers.put("time", "tody");
channel.basicPublish(EXCHANGE_NAME, ROUTING_KEY,
new AMQP.BasicProperties.Builder()
.headers(headers)
.expiration("10000")
.build(), msgByte);
}
//关闭资源
channel.close();
connection.close();
}
}消费者例子:
package com.ly.liyong.rabbitmq;
import com.rabbitmq.client.*;
import java.io.IOException;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
public class ConsumerController {
private static final String QUEUE_NAME="queue_ly_demo";
private static final String IP_ADDRESS="47.105.121.99";
private static final int PORT=5672;
public static void main(String[] args) throws IOException,
TimeoutException, InterruptedException {
Address[] addresses = new Address[]{
new Address(IP_ADDRESS, PORT)
};
ConnectionFactory factory = new ConnectionFactory();
factory.setUsername("lpadmin");
factory.setPassword("lpadmin");
//创建连接
Connection connection = factory.newConnection(addresses);
//创建信道
final Channel channel = connection.createChannel(50);
//设置客户端最多接收未被ack的消息的个数
channel.basicQos(64);
//推模式
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties,
byte[] body)
throws IOException {
System.out.println("推模式: " + new String(body));
//1s后消费
try{
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
//手动ack确认消费
channel.basicAck(envelope.getDeliveryTag(), false);
}
};
//消费模式
channel.basicConsume(QUEUE_NAME, consumer);
//拉模式(每次只拉取一条消息)
// GetResponse response = channel.basicGet(QUEUE_NAME, false);
// System.out.println("拉模式: " + new String(response.getBody()));
// channel.basicAck(response.getEnvelope().getDeliveryTag(), false);
//请求Broker重新发送未被确认的消息(1次)
// channel.basicRecover();
//等待回调函数执行完毕之后,关闭资源
// TimeUnit.SECONDS.sleep(5);
// channel.close();
// connection.close();
}
}
实现方案
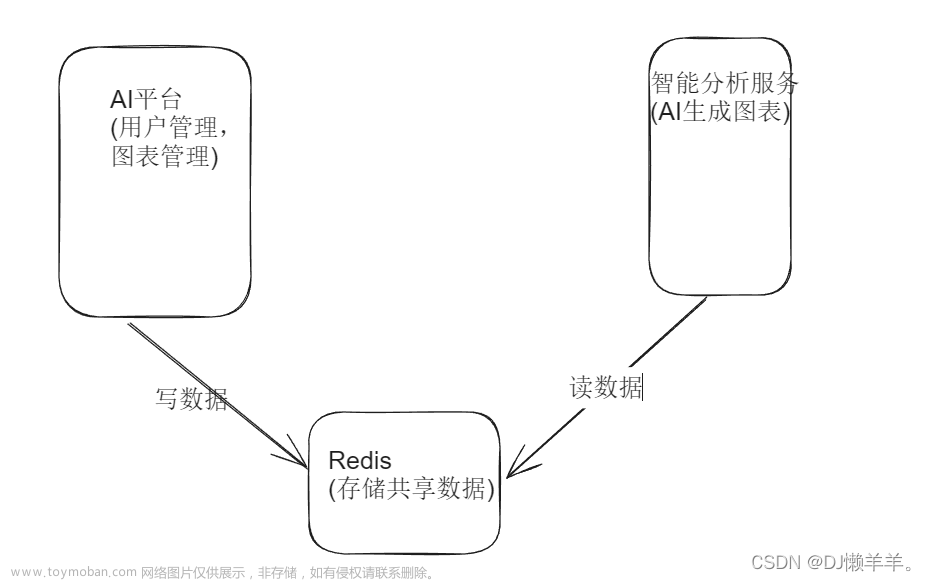
 简单的网络拓扑图
简单的网络拓扑图
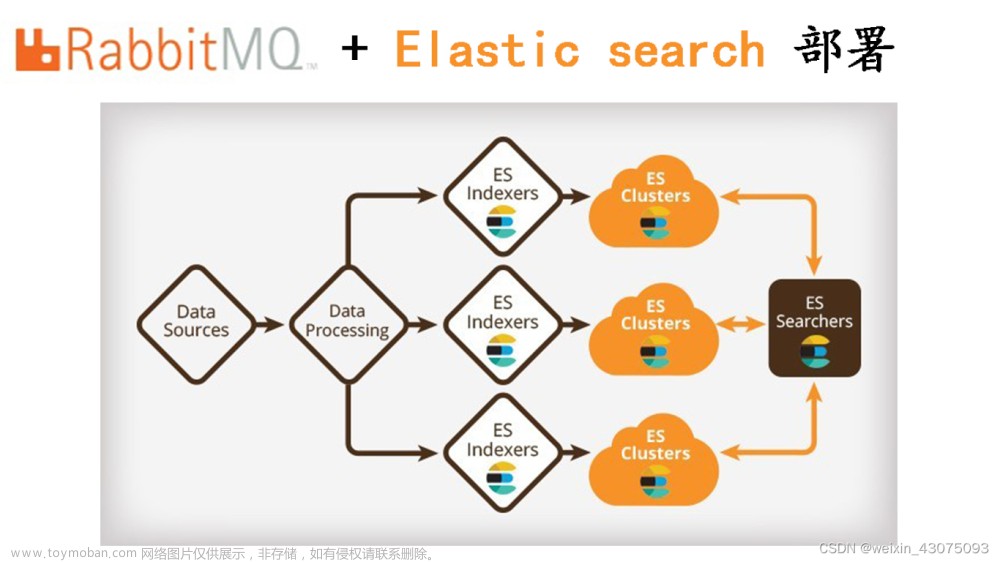
 简单的消息设计图文章来源:https://www.toymoban.com/news/detail-532875.html
简单的消息设计图文章来源:https://www.toymoban.com/news/detail-532875.html
延迟消息通过消息体的过期时间、备份交换机和死信队列的机制来实现.文章来源地址https://www.toymoban.com/news/detail-532875.html
到了这里,关于分布式消息服务设计的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!