文章来源地址https://www.toymoban.com/news/detail-533274.html
一、设计目的
1、了解提高CPU性能的方法。
2、掌握流水线微处理器的工作原理。
3、理解数据冒险、控制冒险的概念以及流水线冲突的解决方法。
4、掌握流水线微处理器的测试方法。
二、设计要求
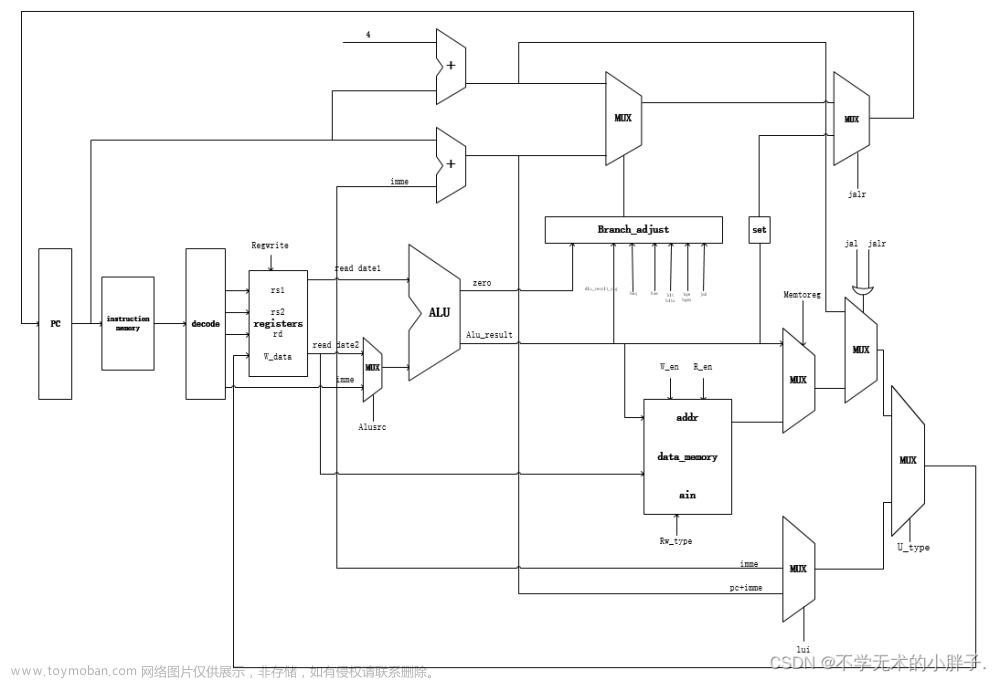
设计一种五级流水线的基于MIPS指令集的处理器,其可支持部分指令,能够处理指令相关和数据相关,使流水线能够正常运行。源码q3026159745
三、设计内容
1、各模块设计
1.1、存储器设计
Instruction指令存储器,ROM
存储微处理器的指令,读出对应地址的指令
Regfile寄存器堆
存储各个寄存器的值,0号地址存R0的值,1号地址存储R1的值,以此类推
Data数据存储器,RAM
存储用户的数据,本实验存储器中存储的数据是对应地址的值

图1.1存储器设计
1.2、ALU设计
ALU有A、B两个输入,F运算类型,Y为输出
F与CU的ALUControl相连,控制ALU的运算
具体功能如下
module alu(A,B,F,Y);
input [31:0]A;
input [31:0]B;
input [2:0]F;
output reg[31:0]Y;
always@(*)
begin
case(F)
3'b000:Y=A&B;
3'b001:Y=A|B;
3'b010:Y=A+B;
3'b011:Y=A/B;
3'b100:Y=A&~B;
3'b101:Y=A|~B;
3'b110:Y=A-B;
3'b111:Y=(A<B);
default:Y=32'bx;
endcase
end

图1.2ALU设计
1.3、ALUForward的设计
ALUForward由两个三路选择器和一个二路选择器组成,三路选择器输出SrcAE由ForwardAE控制
具体功能如下
moduleALU_Forward(ForwardAE,ForwardBE,RD1E,
RD2E,SignlmmE,ALUSrcE,ALUOutM,ResultW,
WriteDataE,SrcAE,SrcBE);
input[1:0]ForwardAE,ForwardBE;
inputALUSrcE;
input[31:0]ALUOutM,ResultW,RD1E,RD2E,SignlmmE;
outputreg[31:0]SrcAE,SrcBE,WriteDataE;
always@(*) begin
case(ForwardAE)
2'b00:SrcAE<=RD1E;
2'b01:SrcAE<=ResultW;
2'b10:SrcAE<=ALUOutM;
endcase
case(ForwardBE)
2'b00:WriteDataE<=RD2E;
2'b01:WriteDataE<=ResultW;
2'b10:WriteDataE<=ALUOutM;
endcase
if(ALUSrcE)
SrcBE<=SignlmmE;
else
SrcBE<=WriteDataE;
end
endmodule

图1.3ALUForward的设计
1.4、Control_Unit设计
采用op 和 funct进行译码,产生各个模块的控制信号。
根据操作码译出相应控制信号

图1.4
moduleControl_Unit(
op,
funct,
RegWriteD,
RegDstD,
AluSrcD,
BranchD,
MemWriteD,
MemtoRegD,
ALUControlD
);
input[5:0]op;
input[5:0]funct;
outputreg RegWriteD;
outputreg RegDstD;
outputreg AluSrcD;
outputreg BranchD;
outputreg MemWriteD;
outputreg MemtoRegD;
outputreg[2:0]ALUControlD;
always@(*)
begin
case (op)
6'b000000:
begin
case (funct)
6'b100000:beginRegWriteD<=1;RegDstD<=1;AluSrcD<=0;BranchD<=0;MemWriteD<=0;MemtoRegD<=0;ALUControlD<=3'b010;end//add
6'b100001:beginRegWriteD<=1;RegDstD<=1;AluSrcD<=0;BranchD<=0;MemWriteD<=0;MemtoRegD<=0;ALUControlD<=3'b110;end//sub
6'b100100:beginRegWriteD<=1;RegDstD<=1;AluSrcD<=0;BranchD<=0;MemWriteD<=0;MemtoRegD<=0;ALUControlD<=3'b000;end//and
6'b100101:beginRegWriteD<=1;RegDstD<=1;AluSrcD<=0;BranchD<=0;MemWriteD<=0;MemtoRegD<=0;ALUControlD<=3'b001;end//or
6'b101010:beginRegWriteD<=1;RegDstD<=1;AluSrcD<=0;BranchD<=0;MemWriteD<=0;MemtoRegD<=0;ALUControlD<=3'b111;end//slt
6'b111111:beginRegWriteD<=1;RegDstD<=1;AluSrcD<=0;BranchD<=0;MemWriteD<=0;MemtoRegD<=0;ALUControlD<=3'b011;end//div
default: beginRegWriteD <= 0;RegDstD <= 0;AluSrcD <= 0;BranchD <= 0;MemWriteD<= 0;MemtoRegD <= 0;ALUControlD <= 3'b000;end //NOP
endcase
end
6'b100011:beginRegWriteD<=0;RegDstD<=0;AluSrcD<=1;BranchD<=0;MemWriteD<=1;MemtoRegD<=0;ALUControlD<=3'b010;end //sw
6'b101011:beginRegWriteD<=1;RegDstD<=0;AluSrcD<=1;BranchD<=0;MemWriteD<=0;MemtoRegD<=1;ALUControlD<=3'b010;end //lw
6'b001000:beginRegWriteD<=1;RegDstD<=0;AluSrcD<=1;BranchD<=0;MemWriteD<=0;MemtoRegD<=0;ALUControlD<=3'b010;end //addi
6'b001000:beginRegWriteD<=1;RegDstD<=0;AluSrcD<=1;BranchD<=0;MemWriteD<=0;MemtoRegD<=0;ALUControlD<=3'b110;end //subi
6'b000100:beginRegWriteD<=0;RegDstD<=0;AluSrcD<=0;BranchD<=1;MemWriteD<=0;MemtoRegD<=0;ALUControlD<=3'b110;end //beq
6'b000101:beginRegWriteD<=0;RegDstD<=0;AluSrcD<=0;BranchD<=1;MemWriteD<=0;MemtoRegD<=0;ALUControlD<=3'b110;end //bne
default: begin RegWriteD <=0;RegDstD <= 0;AluSrcD <= 0;BranchD <= 0;MemWriteD <= 0;MemtoRegD<= 0;ALUControlD <= 3'b000;end //NOP
endcase
end
endmodule
1.5、五级流水线clk设计
1.5.1clkPC
(1)取指令阶段,如果复位rst不为低电平,则每次时钟上升沿PCF刷新,若为低电平则PCF赋值为零
(2)StallF停顿,StallF为低电平,则PCF保持不变
(3)PCF的值即为本次取指令的地址,取出Instruction中的指令
(4)PCF来源有两个,一个是PC的累加,一个是相对转移地址
moduleclkPC(clk,rst,StallF,PC,PCF);
inputclk,rst,StallF;
input[31:0] PC;
output reg[31:0] PCF;
always @(posedge clk)
begin
if(!rst)
PCF <= 32'b0;
else if(StallF==1'b0)
PCF <= PC;
else
PCF <= PCF;
end
endmodule

图1.5.1clkPC clkFetch_Decode
1.5.2clkFetch_Decode
时钟上升沿判断
(1)是否有停顿,若有停顿则clk模块输出的信号保持不变;
(2)clr是否为高电平,若是,则将模块输出信号清零
(3)若停顿和清零信后均为低,则模块输入值对应赋给输出值
moduleclkFetch_Decode(clk,clr,StallD,RD,PCPlus4F,InstrD,PCPlus4D);
inputclk,clr,StallD;
input[31:0] RD,PCPlus4F;
outputreg[31:0] InstrD,PCPlus4D;
always @(posedge clk)
begin
if(StallD)begin
InstrD<=InstrD;
PCPlus4D<=PCPlus4D;
end
else if(clr)begin
InstrD <= 32'b0;
PCPlus4D<=32'b0;
end
else begin
InstrD<=RD;
PCPlus4D <= PCPlus4F;
end
end
endmodule
1.5.3 clkDecode_Excute
每当时钟信号上升沿判断FLUSH信号是否为高电平,若是,则清零模块的输出信号,若否则输入信号赋给相应的输出信号。
Branch信号单周期在ALU判断Rt和Rs是否相等并转移,而流水线CPU中可以提前判断是否转移
moduleclkDecode_Excute(clk,clr,RegWriteD,RegDstD,ALUSrcD,
BranchD,MemWriteD,MemtoRegD,
ALUControlD,RD1,RD2,RsD,RtD,RdD,SignlmmD,RegWriteE,RegDstE,ALUSrcE,
MemWriteE,MemtoRegE,ALUControlE,RD1E,RD2E,RtE,RdE,RsE,SignlmmE);
inputclk,clr,RegWriteD,RegDstD,ALUSrcD,MemWriteD,MemtoRegD,BranchD;
input[2:0] ALUControlD;
input[4:0] RtD,RdD,RsD;
input[31:0] RD1,RD2,SignlmmD;
outputreg RegWriteE,RegDstE,ALUSrcE,MemWriteE,MemtoRegE;
outputreg[2:0] ALUControlE;
outputreg[4:0] RtE,RdE,RsE;
outputreg[31:0] RD1E,RD2E,SignlmmE;
always @(posedge clk)
begin
if(!clr)
begin
RegWriteE<=RegWriteD;
RegDstE<=RegDstD;
ALUSrcE<=ALUSrcD;
MemWriteE<=MemWriteD;
MemtoRegE<=MemtoRegD;
ALUControlE<=ALUControlD;
RD1E<=RD1;
RD2E<=RD2;
RsE<=RsD;
RtE<=RtD;
RdE<=RdD;
SignlmmE<=SignlmmD;
end
else
begin//清空流水线
RegWriteE<=0;
RegDstE<=0;
ALUSrcE<=0;
MemWriteE<=0;
MemtoRegE<=0;
ALUControlE<=3'b0;
RD1E<=32'b0;
RD2E<=32'b0;
RsE<=5'b0;
RtE<=5'b0;
RdE<=5'b0;
SignlmmE<=32'b0;
end
end
endmodule

图1.5.3clkDecode_Excute
1.5.4 clkExcude_Memory
moduleclkExcude_Memory(clk,RegWriteE,MemtoRegE,MemWriteE,
ALUResult,WriteDataE,WriteRegE,
RegWriteM,MemtoRegM,MemWriteM,ALUOutM,WriteDataM,WriteRegM);
input clk,RegWriteE,MemtoRegE,MemWriteE;
input [4:0] WriteRegE;
input [31:0] ALUResult,WriteDataE;
output reg RegWriteM,MemtoRegM,MemWriteM;
output reg[4:0] WriteRegM;
output reg[31:0] ALUOutM,WriteDataM;
always @ (posedge clk)
begin
RegWriteM<=RegWriteE;
MemWriteM<=MemWriteE;
MemtoRegM<=MemtoRegE;
ALUOutM<=ALUResult;
WriteDataM<=WriteDataE;
WriteRegM<=WriteRegE;
end
endmodule
1.5.5 clkMemory_Writeback
moduleclkMemory_Writeback(clk,RegWriteM,MemtoRegM,ALUOutM,RD,WriteRegM,
RegWriteW,MemtoRegW,ALUOutW,ReadDaraW,WriteRegW);
input clk,RegWriteM,MemtoRegM;
input [4:0] WriteRegM;
input [31:0] RD,ALUOutM;
output reg RegWriteW,MemtoRegW;
output reg[4:0] WriteRegW;
output reg[31:0] ALUOutW,ReadDaraW;
always @ (posedge clk)
begin
RegWriteW<=RegWriteM;
MemtoRegW<=MemtoRegM;
ALUOutW<=ALUOutM;
ReadDaraW<=RD;
WriteRegW<=WriteRegM;
end
endmodule
1.6 HazardUnit
我们知道影响流水线性能的有三个冒险:数据冒险,结构冒险,控制冒险。
(1)由于数据存储器和指令存储器分离,所以流水线读指令和写数据可以并行执行,不存在存储器争用问题,寄存器堆采用读写双端口,因此也不会出现资源争用问题。
(2)数据冒险
寄存器的值还没有被写回寄存器,若此时读取寄存器数据并用此数据参与运算就会造成错误。
a.不访存的数据冒险

图1.6.1不访存的数据冒险
add $s0,$s2,$s3
add $t0,$s0,$s1
第二条add要用s0的数据进行计算时,也就是execute阶段,可以将第一条正处于memory阶段的AluOutM结果给第二条指令的ALU输入。
这就是所谓的旁路技术
if ((rsE != 0) AND (rsE == WriteRegM) AND RegWriteM)
then ForwardAE = 10
elseif ((rsE != 0) AND (rsE == WriteRegW) AND RegWriteW)//访问存储器
then ForwardAE = 01
else ForwardAE= 00
b.访存造成的数据冒险

图1.6.2访存造成的数据冒险
lw $s0,40($0)
add$s0,$s0,$s1
add的execute阶段,需要用到上一条指令写回的$s0的数值,而上一条指令要从存储器取数据,在Writeback阶段才能得到$s0的数值,所以需要停顿一个时钟周期,等到lw指令进入Writeback阶段再通过旁路技术将ResultW引入到add的执行阶段。
本条指令停顿了,后面的指令也要跟着停顿一个时钟周期。
lwstall=
((rsD==rtE) OR (rtD==rtE))AND MemtoRegE
StallF = StallD = FlushE = lwstall
(3)控制冒险

图1.6.3控制冒险1
在Memory阶段进行转移判断会造成后面三条不该执行的指令执行,流水线数值改变,所以应该清空流水线。

图1.6.4控制冒险2
如果在指令译码后直接判断Rs和Rt是否相等,则只有一条不该执行的指令执行了。
如果判断的Rs或者Rt还没有被写入到寄存器堆,则产生新的数据冒险,由于Decode阶段要用到Rs和Rt,而寄存器的值需要在Memory阶段或者Writeback阶段产生,所以不仅要有前向通路,还要有停顿才可以处理此数据相关。
Forwardinglogic:
ForwardAD = (rsD!=0) AND (rsD == WriteRegM) AND RegWriteM
ForwardBD = (rtD !=0) AND (rtD == WriteRegM) AND RegWriteM
Stallinglogic:
branchstall = BranchD AND RegWriteEAND
(WriteRegE == rsDOR WriteRegE == rtD)
OR
BranchD AND MemtoRegM AND
(WriteRegM == rsDOR WriteRegM == rtD)
StallF = StallD= FlushE = lwstall OR branchstall

图1.6.5冒险控制单元

图1.6.6提前获得转移判断
moduleHazardUnit(StallF,StallD,
BranchD,ForwardAD,ForwardBD,ForwardAE,ForwardBE,
RsD,RtD,RsE,RtE,FlushE,RegWriteE,MemtoRegE,
WriteRegE,WriteRegM,RegWriteM,RegWriteW,WriteRegW,
MemtoRegM);
inputRegWriteE,RegWriteM,RegWriteW,MemtoRegE,MemtoRegM,BranchD;
input[4:0] RsD,RtD,RsE,RtE,WriteRegE,WriteRegM,WriteRegW;
outputreg [1:0] ForwardAE,ForwardBE;
outputreg ForwardAD,ForwardBD,StallF,StallD,FlushE;
reglwstall,branchstall;
always @( * )
begin
if( (RsE != 0)&& (RsE ==WriteRegM) && RegWriteM) //上一条指令的写回寄存器(WriteRegM)与本条指令的寄存器一致,
//采用旁路技术,将上一条指令的结果直接送到执行处。
ForwardAE= 2'b10;
else if ((RsE != 0)&& (RsE ==WriteRegW) && RegWriteW) //上上条指令的写回寄存器(WriteRegW)与本条指令的寄存器RS一致
//旁路技术,ResultW送入执行处
ForwardAE = 2'b01;
else ForwardAE= 2'b00;
if((RtE != 0)&&(RtE == WriteRegM)&& RegWriteM)
ForwardBE <= 2'b10; //上一条指令的写回地址(WriteRegM)与本条指令的操作数地址(寄存器RT)一致,
//采用旁路技术,将上一条指令的结果直接送到执行处。
else if ( (RtE != 0)&&(RtE ==WriteRegW) && (RegWriteW))
ForwardBE <= 2'b01;
else ForwardBE <= 2'b00;
//bne指令,在译码阶段开始判断RS和RT的值,提前判断,防止之后的指令执行
//当上上条指令要写回寄存器参与本次bne比较,通过旁路技解决,RD1/RD2<=ALUOut
ForwardAD <= (RsD != 0)&&(RsD==WriteRegM)&& RegWriteM;
ForwardBD <= (RtD != 0)&&(RtD==WriteRegM)&& RegWriteM;
branchstall <= (BranchD &&RegWriteE && (WriteRegE == RsD || WriteRegE == RtD) )//上一条指令要写这次比较的操作数
|| (BranchD && MemtoRegM&& (WriteRegM == RsD || WriteRegM == RtD));//上两条指令要写这次比较的操作数
//stall
lwstall <= ((RsD==RtE) || (RtD==RtE))&& MemtoRegE;
StallF <= lwstall || branchstall;
StallD <= StallF;
FlushE <= StallD;//清空流水线防止再次判断并转移
end
endmodule

表1.6.1、停顿以及前向通路的举例分析
2.Top模块设计
顶层模块全部采用例化连接
顶层模块所有信号和连接代码如下
inputclk,rst;
wireRegWriteD,RegDstD,ALUSrcD,BranchD,MemWriteD,MemtoRegD,PCSrcD;//decode_cu EqualD
wireRegWriteE,RegDstE,ALUSrcE,MemWriteE,MemtoRegE;//excute_cu
wireRegWriteM,MemtoRegM,MemWriteM;//memory_cu
wireMemtoRegW,RegWriteW;//writeback_cu
wire[2:0] ALUControlD,ALUControlE;//cu
wireForwardAD,ForwardBD,StallF,StallD,FlushE;//冒险
wire[1:0] ForwardAE,ForwardBE;
wire[4:0] WriteRegW,WriteRegE,WriteRegM,RtE,RdE,RsE;
wire[31:0] PC,PCF,A,PCPlus4F,PCPlus4D,PCBranchD,RD,InstrD,WD3,RD1,RD2,SignlmmD,
RD1E,RD2E,SignlmmE,SrcAE,SrcBE,ALUResult,
ReadDataW,ALUOutW,WriteDataE,ALUOutM,WriteDataM,ReadData,ResultW;
module Top(clk,rst);
input clk,rst;
wireRegWriteD,RegDstD,ALUSrcD,BranchD,MemWriteD,MemtoRegD,PCSrcD;//decode_cu EqualD
wire RegWriteE,RegDstE,ALUSrcE,MemWriteE,MemtoRegE;//excute_cu
wire RegWriteM,MemtoRegM,MemWriteM;//memory_cu
wire MemtoRegW,RegWriteW;//writeback_cu
wire [2:0] ALUControlD,ALUControlE;//cu
wire ForwardAD,ForwardBD,StallF,StallD,FlushE;//冒险
wire [1:0] ForwardAE,ForwardBE;
wire [4:0] WriteRegW,WriteRegE,WriteRegM,RtE,RdE,RsE;
wire [31:0]PC,PCF,A,PCPlus4F,PCPlus4D,PCBranchD,RD,InstrD,WD3,RD1,RD2,SignlmmD,
RD1E,RD2E,SignlmmE,SrcAE,SrcBE,ALUResult,
ReadDataW,ALUOutW,WriteDataE,ALUOutM,WriteDataM,ReadData,ResultW;
//clk 五级流水
clkPC clkPC(.clk(clk),.rst(rst),.StallF(StallF),.PC(PC),.PCF(PCF));
clkFetch_Decodeclk Fetch_Decode(.clk(clk),.clr(PCSrcD),.StallD(StallD),
.RD(RD),.PCPlus4F(PCPlus4F),.InstrD(InstrD),.PCPlus4D(PCPlus4D));
clkDecode_Excuteclk Decode_Excute(.clk(clk),.clr(FlushE),.RegWriteD(RegWriteD),
.RegDstD(RegDstD),.ALUSrcD(ALUSrcD),
.BranchD(BranchD),.MemWriteD(MemWriteD),.MemtoRegD(MemtoRegD),.ALUControlD(ALUControlD),
.RD1(RD1),.RD2(RD2),.RsD(InstrD[25:21]),.RtD(InstrD[20:16]),.RdD(InstrD[15:11]),.SignlmmD(SignlmmD),.RegWriteE(RegWriteE),
.RegDstE(RegDstE),.ALUSrcE(ALUSrcE),.MemWriteE(MemWriteE),.MemtoRegE(MemtoRegE),
.ALUControlE(ALUControlE),.RD1E(RD1E),.RD2E(RD2E),.RtE(RtE),.RdE(RdE),.RsE(RsE),.SignlmmE(SignlmmE));
clkExcude_Memory clkExcude_Memory(clk,RegWriteE,MemtoRegE,MemWriteE,
ALUResult,WriteDataE,WriteRegE
RegWriteM,MemtoRegM,MemWriteM,ALUOutM,WriteDataM,WriteRegM);
clkMemory_Writeback clkMtoW(clk,RegWriteM,MemtoRegM,ALUOutM,ReadData,
WriteRegM,RegWriteW,MemtoRegW,ALUOutW,ReadDataW,WriteRegW);
//各个小模块
PCPlus PCPlus(PCF,PCPlus4F);
instruction instruction(PCF>>2,RD);
regfile regfile(.clk(clk),.a1(InstrD[25:21]),.a2(InstrD[20:16]),.a3(WriteRegW),.we3(RegWriteW),.wd3(ResultW),.rd1(RD1),.rd2(RD2));
PC1 PC1(PCBranchD,PCPlus4F,PCSrcD,PC);
PCBranch PCBranch(PCPlus4D,SignlmmD,PCBranchD);
WriteReg_2to1 WriteReg_2to1(RegDstE,RdE,RtE,WriteRegE);//WriteRegE的选择
//控制单元
Control_Unit Control_Unit(InstrD[31:26],InstrD[5:0],RegWriteD,RegDstD,
ALUSrcD,BranchD,MemWriteD,MemtoRegD,ALUControlD);
Sign_Extend Sign_Extend(InstrD[15:0],SignlmmD);
ALU_Forward ALU_Forward(ForwardAE,ForwardBE,RD1E,RD2E,SignlmmE,
ALUSrcE,ALUOutM,ResultW,WriteDataE,SrcAE,SrcBE);
alu alu(SrcAE,SrcBE,ALUControlE,ALUResult);
data data(ReadData,clk,MemWriteM,ALUOutM,WriteDataM);
EqualD equal(ForwardAD,ForwardBD,ALUOutM,RD1,RD2,BranchD,PCSrcD);
//数据冒险和控制冒险
HazardUnit HazardUnit(StallF,StallD,BranchD,ForwardAD,ForwardBD,
ForwardAE,ForwardBE,InstrD[25:21],InstrD[20:16],
RsE,RtE,FlushE,RegWriteE,MemtoRegE,WriteRegE,WriteRegM,RegWriteM,RegWriteW,WriteRegW,MemtoRegM);
ResultWritebackResultWriteback(MemtoRegW,ReadDataW,ALUOutW,ResultW);
endmodule
图2.1顶层模块连接
3.代码设计
代码实现从数据存储器1号地址里的数累加到100号地址里的数,再除以100取平均数,由于数据存储器存的数为对应的地址,所以累加和为5050,平均数为50
001000_00000_00001_0000_0000_0000_0001//addiR1,R0,0 R1为变址寄存器X
001000_00000_00010_0000_0000_0000_0000//addiR2,R0,0 R2存放结果
001000_00000_00011_0000_0000_0110_0100//addiR3,R0,100 R3存放100
001000_00001_00001_0000_0000_0000_0001//addiR1,R1,1 R1自加一 即INX
101011_00001_00100_0000_0000_0000_0000//lw M(R1)->(R4)数据相关,R1还未加一,旁路技术解决此数据相关
000000_00010_00100_00010_00000_100000//add (R2)+(R4)->(R2) //R4还未写回寄存器堆,停顿加旁路技术解决此数据相关
000101_00001_00011_1111_1111_1111_1100 //BNE (R1) (R3) -4
000000_00010_00011_00010_00000_111111//DIV (R2)/(R3)->(R2)
四、仿真结果

控制信号初始状态不定,需要译码后产生。
可以看到取出的第一个数是1,也就是地址1里的数。
第二次取出的数是2,累加结果为3

结果分析:
每次RtD等于RtE都是R4时会有lwstall,停顿一个时钟周期以便旁路技术将WriteBack阶段
的结果写回到execute
累加结果为5050
可以看到仿真最后WriteBack的值是平均值50
五、设计心得
5.1遇到的问题
(1)线路连接不对,例化时建议直接将模块名和顶层信号名对应,不需要.(clk)这样比较麻烦
(2)位宽不对,导致出错
(3)不加Reg不能在always赋值
(4)assign不能对reg赋值
(5)readmemh读十六进制数存十进制数
(6)指令读取后若无停顿及clr,PC自动加4,所以判断不相等转移指令要考虑PC加4了
5.2我的收获
(1)CPU流水线加快了CPU的运行速度,开发了CPU的并行性,若没有停顿,五级流水线的运行速度会是单周期的五倍
(2)数据冒险可以通过前向通路和停顿解决,控制冒险可以通过在Decode阶段提前判断是否符合转移条件提前转移,同时清空流水线,防止流水线数据混乱。
(3)do文件可以快速完成文件的编译,仿真波形添加,大大提升了使用modelsim的效率。
(4)verilog语言很好地可以实现硬件的设计,我们要好好掌握,为更复杂的集成电路设计打下坚实基础。
以上介绍包含了关键代码,同学们可以参考学习,是我的一个课程设计,不明白的地方可以私信我,评论留言也可文章来源:https://www.toymoban.com/news/detail-533274.html
到了这里,关于基于Verilog的mips指令集单周期/五级流水cpu,modelsim/vivado仿真设计 设计的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!