hive version 3.1.3

以往我们插入分区 需要
insert ovewrite table p_table partition(period_id=‘202212’)
select id name from xxxx;
或者是
insert overwrite table
select id,name,period_id from table where period_id=202212
前者是指定分区,后者是动态分区。没啥好说的。
但是今天遇到一个问题,如果我查询的数据=0,那么数据还会覆盖么?

insert overwrite table dwdmdata.xxx partition (period_id = '209901')
select id ,name
from dwdmdata.dm_ce_f_debts_mandate where 1=2
insert overwrite table dwdmdata.xxx
select id ,name,'209902' as period_id
from dwdmdata.dm_ce_f_debts_mandate where 1=2

结果
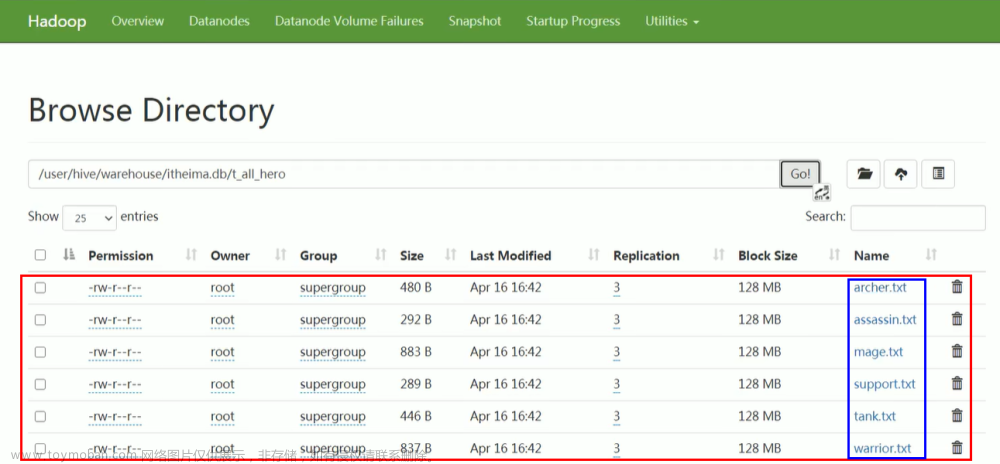
直接插入分区的,分区都没了。209901不见了
动态分区插入的 没有影响。
所以这里有个注意事项!!!! 如果我们建立了一个分区表,如果每个月都要更新数据,不要因为省事就是用动态分区插入。文章来源:https://www.toymoban.com/news/detail-533795.html
比如跑上月的数据最开始有44条记录,后面业务说不对,应该一条都没有的,结果你重跑了,确实跑出了0条记录,但是你插入的时候就是不能覆盖。文章来源地址https://www.toymoban.com/news/detail-533795.html
到了这里,关于hive分区表之insert overwrite 注意事项的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!