背景:
在日常编写代码的过程中,我们经常会在方法内部new很多的其他类对象来进行编码工作,那么对于这种情况怎么让new出来的对象是一个我们特意创建出来的一个mock实例,从而让我们能完全控制new出来的对象的所有行为呢?本文就来讲解下如何在powermock中mock类的构造函数。
原理追踪:
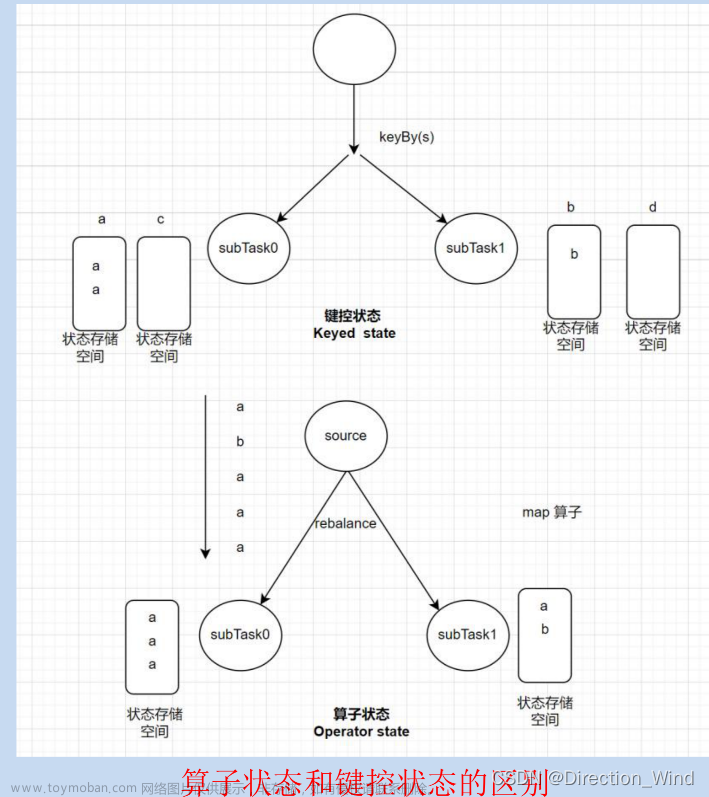
首先对于flink来说,对于算子的每个并行任务,每个任务也就是每个task都有存储有一份自己的状态,也就是Flink的状态是基于task的本地存储的,是保存在本地内存中的一份数据,同一个算子的多个并行task之间是没有跨 task 通讯。
其实对于下游的算子来说,收到广播元素的顺序有可能是不一样的,如下图所示:下游算子任务1收到元素的顺序是先A后B,而下游算子任务2收到元素的顺序是先B后A,
敏感的你是不是意识到了什么?是不是意味着有一个时刻,下游算子任务1的广播状态包含A,而下游算子任务2的广播状态包含的是B,这两个并行算子的广播状态是不一致?顺着推理假设此时有其他非广播流的元素关联广播状态,意味着有可能在算子任务1上得到的结果和算子任务2上得到的结果是不一样的?进一步引申,如果故障恢复后,下一次运行时,下游算子任务1和下游算子任务2都先收到A,假设此时同样是非广播流过来connect,是不是就会导致此时得到的结果和之前故障前那一次运行得到的结果是不一致的?也就是意味这个结果不具有确定性!!
最后,你一定好奇,那广播状态保证的语义是什么?答案是最终一致性,还是用上面的图作为例子,当保存到checkpoint检查点时,算子任务1和算子任务2肯定都收到了A和B两个元素,只是一个顺序是AB,一个顺序是BA,但是他们再不理会顺序的前提下保存到checkpoint保存点的内容是一样的。所以当从故障中恢复时,他能保证每个并行算子任务的广播状态的一致性.文章来源:https://www.toymoban.com/news/detail-534323.html
总结:
算子的并行task之间是没有跨task通信的,所以所有的状态都是存放在本地机器的本地内存中,是单机级别的,他们能实现所谓的广播状态号称多个并行task之间状态一致性的前提是他们只保证最终一致性,也就是通过map的实现,他们保证元素在不区分到达顺序的情况下多个算子任务的状态是可以保持最终一致的.文章来源地址https://www.toymoban.com/news/detail-534323.html
到了这里,关于Flink的状态是否支持任务间共享的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!